TACL 2022 | 跨语言摘要最新综述:典型挑战及解决方案


论文标题:
A Survey on Cross-Lingual Summarization (目前已被TACL接收)
https://arxiv.org/abs/2203.12515
本综述的组织结构如下:
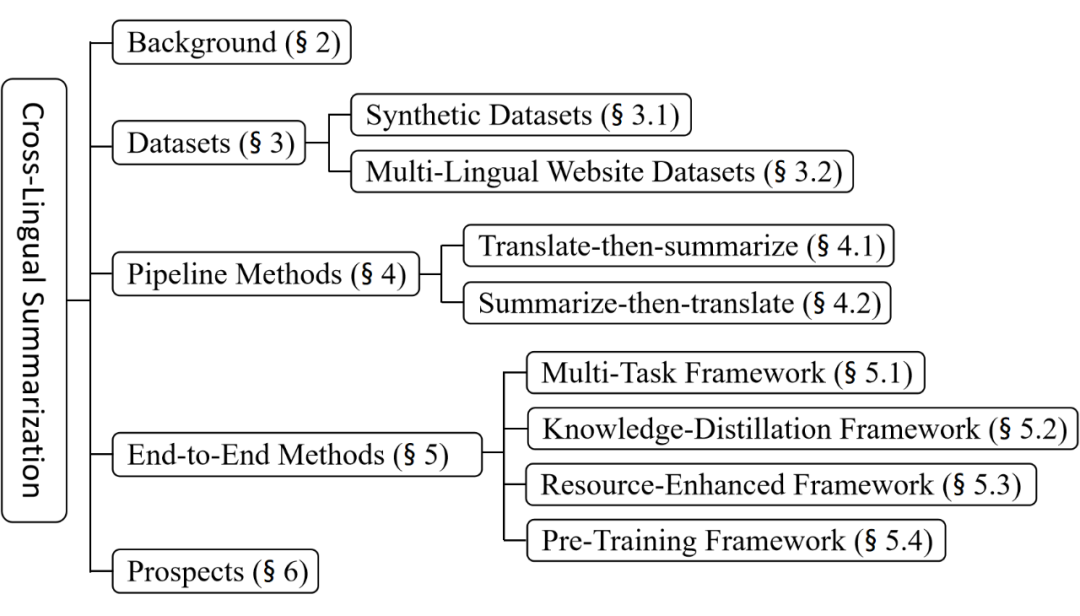

跨语言摘要普遍被认为是文本摘要与机器翻译的复合任务。该任务的挑战从数据和模型层面分别概括如下:
2. 从模型角度出发:跨语言摘要需要模型同时掌握摘要与翻译能力,这使得模型直接完成跨语言摘要任务充满挑战 [25]。早期的研究为了规避掉这一挑战点,普遍采用 pipeline 的方式,即先摘要后翻译或先翻译后摘要。然而这种方式误差传播严重、推理速度缓慢且严重依赖于机器翻译的效果,因此并不满足现实需求。近几年的研究也表明了端到端的方式优于 pipeline 方式。尽管如此,端到端的跨语言摘要模型距离落地还有很长的路要走。

为了缓解数据难收集的痛点,研究员们探索出了两种不同的方式来构建跨语言摘要数据集。据此,我们将现有数据集分为合成数据集与多语言网站数据集。
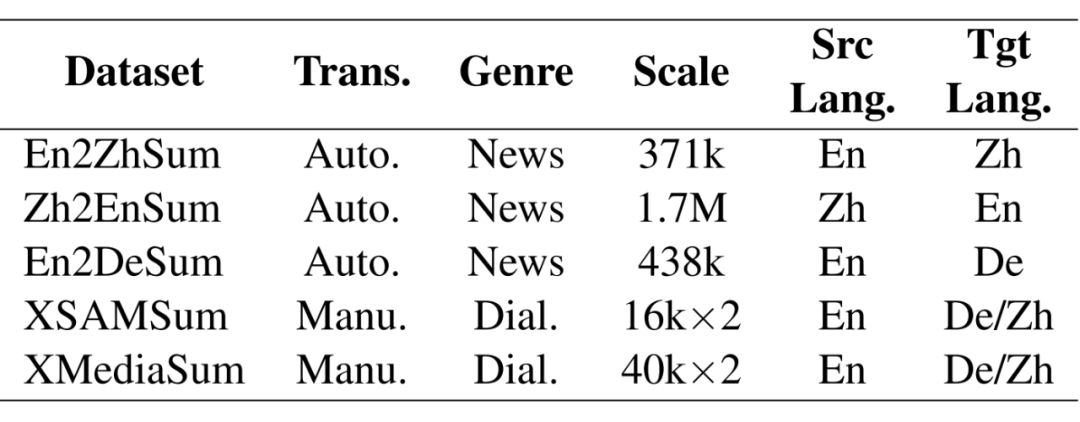
2.1 合成数据集
下表分别从翻译方式、文档题材、数据规模、源语言以及目标语言方面统计了目前主要的合成数据集:
2.2 多语言网站数据集
与 WikiLingua 类似,XWikis [11] 从维基百科网站 [12] 收集了四种语言(英语、德语、法语和捷克语)的百科文本,不同语言百科词条之间也存在对应关系。对于某一个百科词条,XWikis 假设其中一个语言版本的引导段为目标摘要,而另一个语言的正文段为输入文档,这样便可收集跨语言摘要样本。除上述工作之外,CrossSum 数据集 [13] 从BBC新闻网站 [14] 收集了大量的跨语言摘要对,这得益于 BBC 所提供的全球化新闻服务。

早期对跨语言摘要的研究主要集中在 pipeline 方法,即让模型分步完成单语摘要和机器翻译。根据完成先后顺序的不同又可分为先摘要后翻译方法和先翻译后摘要方法。
3.1 先摘要后翻译方法
先摘要后翻译方法首先为源语言文档生成源语言摘要,再将摘要翻译至目标语言。Orasan 等人 [15] 先使用 MMR 算法得到源语言新闻的摘要,再通过 eTranslator 翻译服务 [16] 将摘要翻译到目标语言。Wan 等人 [17] 发现在此类方法中可能会因为翻译模型的缺陷导致最终的跨语言摘要效果欠佳,于是他们首先利用 SVM 算法预测源语言文章中每个句子的翻译质量,并将翻译质量和信息量都高的句子组成摘要,之后使用谷歌翻译将摘要翻译至目标语言。
3.2 先翻译后摘要方法
Yao 等人 [21] 首先将源语言文档翻译成目标语言,接着基于翻译前后的双语特征筛选出重要的句子得到候选目标语言摘要,最后通过删除冗余或翻译质量差的短语以构建最终摘要。Zhang 等人 [22] 首先将翻译前后的文档解析成 PAS (Predicate-Argument Structures)结构,再根据双语特征将 PAS 元素融合成最终摘要。Linhares Pontes等人 [23] 利用翻译前后文档的双语特征将重要句子压缩成最终摘要。除此之外,随着 En2ZhSum 和 Zh2EnSum 大规模数据集的发布,Ouyang 等人 [24] 随后首次在 pipeline 中使用了基于 seq2seq 框架的单语摘要生成模型。

尽管 pipeline 方法更加直观,它仍存在着许多弊端,例如误差传播严重、依赖于外部的翻译系统、具有额外开销并且推理速度慢。为了缓解上述问题并满足现实需求,近年来的跨语言摘要研究大多集中在端到端方法,即让模型直接完成跨语言摘要任务。这也意味着模型需要同时学习摘要和翻译两种能力。为了让模型更好地完成这一任务,研究者们普遍利用相关任务(例如单语摘要或机器翻译)或额外资源(例如双语字典)辅助模型的学习。我们将现有的端到端方法分为四种不同框架:(1)多任务学习框架、(2)知识蒸馏框架、(3)资源增强框架以及(4)预训练框架。
4.1 多任务学习框架
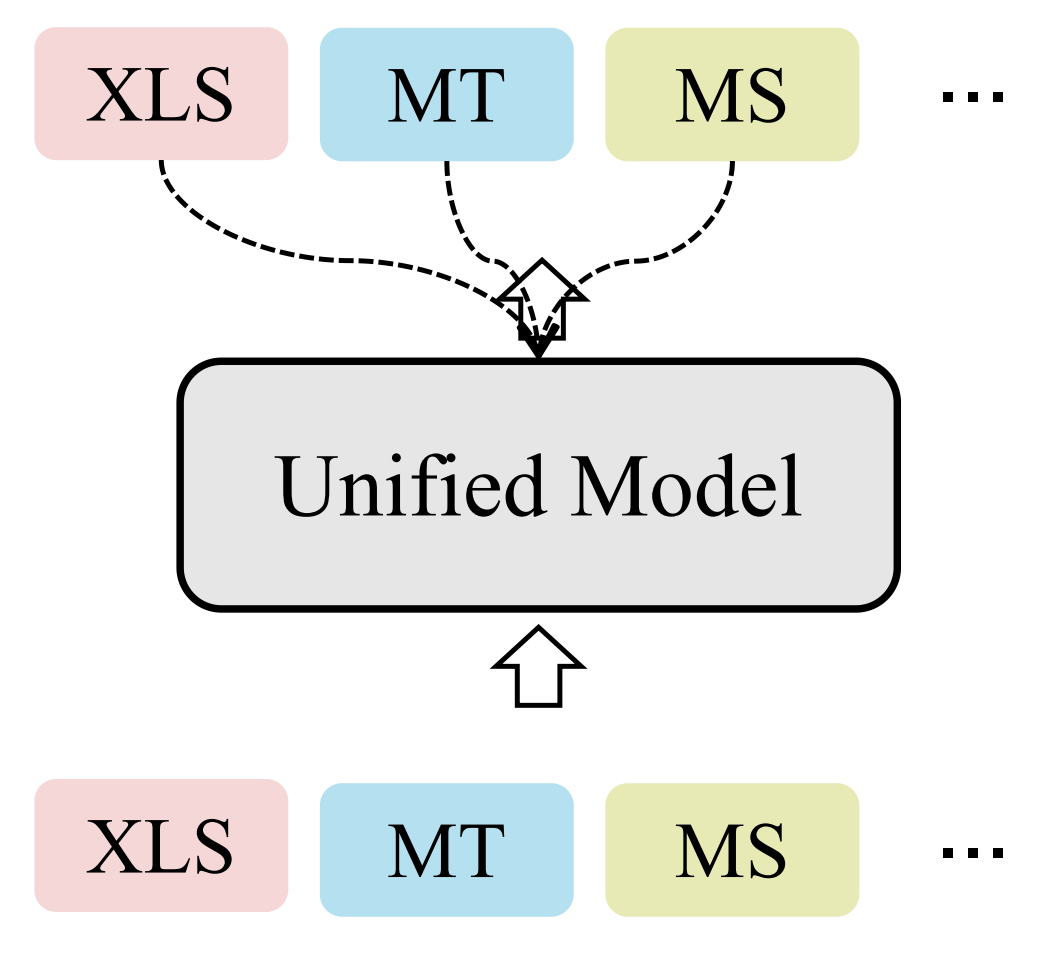
▲ XLS: 跨语言摘要; MT: 机器翻译; MS: 单语摘要。虚线代表监督信号
Liang 等人 [27] 则选择利用变分自编码器完成跨语言摘要。具体地,他们使用三种变量来重建机器翻译、单语摘要和跨语言摘要结果。所使用的编码器和解码器在三个任务之间共享且每个任务有不同的先验网络。
4.2 知识蒸馏框架
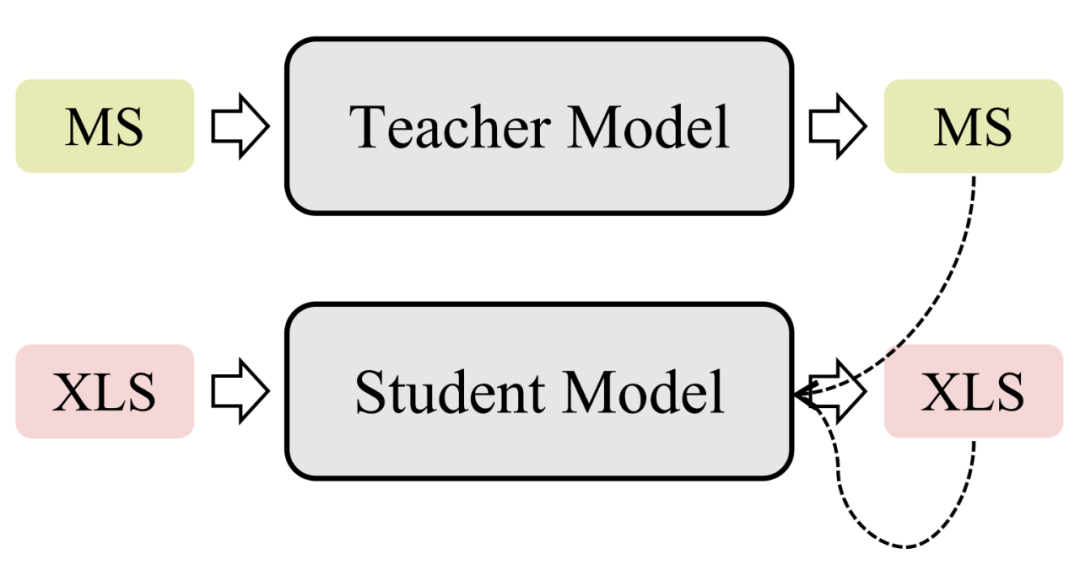
由于单语摘要/机器翻译任务和跨语言摘要任务之间密切的关系,一些研究者们尝试将单语摘要/机器翻译模型作为教师模型,并在跨语言摘要模型的训练过程中对其进行监督。Ayana 等人 [28] 使用大规模单语摘要数据集和机器翻译数据集分别训练了两个教师模型,再分别用教师模型的输出分布作为软标签监督跨语言摘要模型。Duan 等人 [29] 延续了这一思想并额外利用了教师模型和学生模型注意力权重的欧式距离来监督学生模型(即跨语言摘要模型)。类似地,Nguyen 等人 [30] 也尝试了此类方法,并基于 Sinkhorn 散度设计了一个新的变体,更好地让教师模型指导跨语言摘要模型。
4.3 资源增强框架
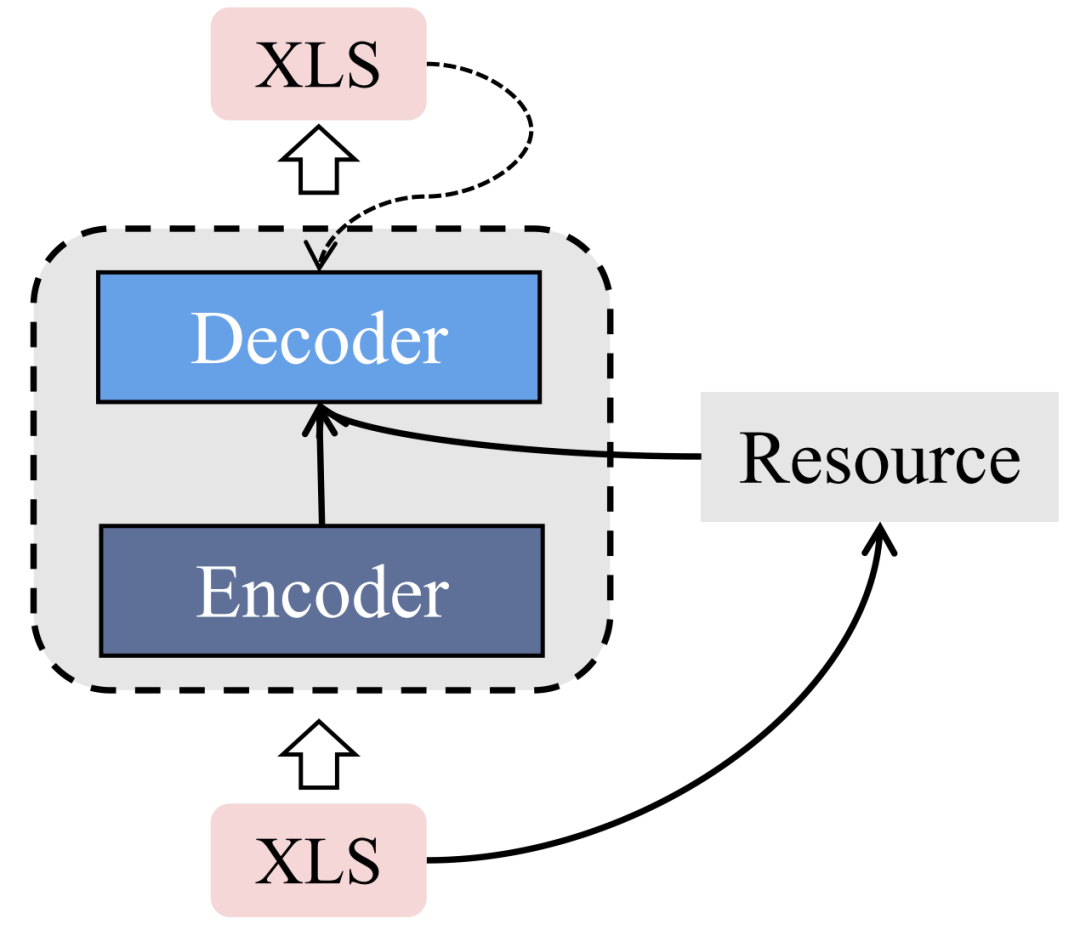
Jiang 等人 [33] 使用 TextRank 算法从输入文档中提取关键词,并以此建立图结构。接着他们分别使用 transformer encoder 和 graph encoder 编码输入文档和所引入的图结构,最后使用改进 cross-attention 后的 transformer decoder 基于两个 encoder 的结果生成最终的跨语言摘要。
4.4 预训练框架
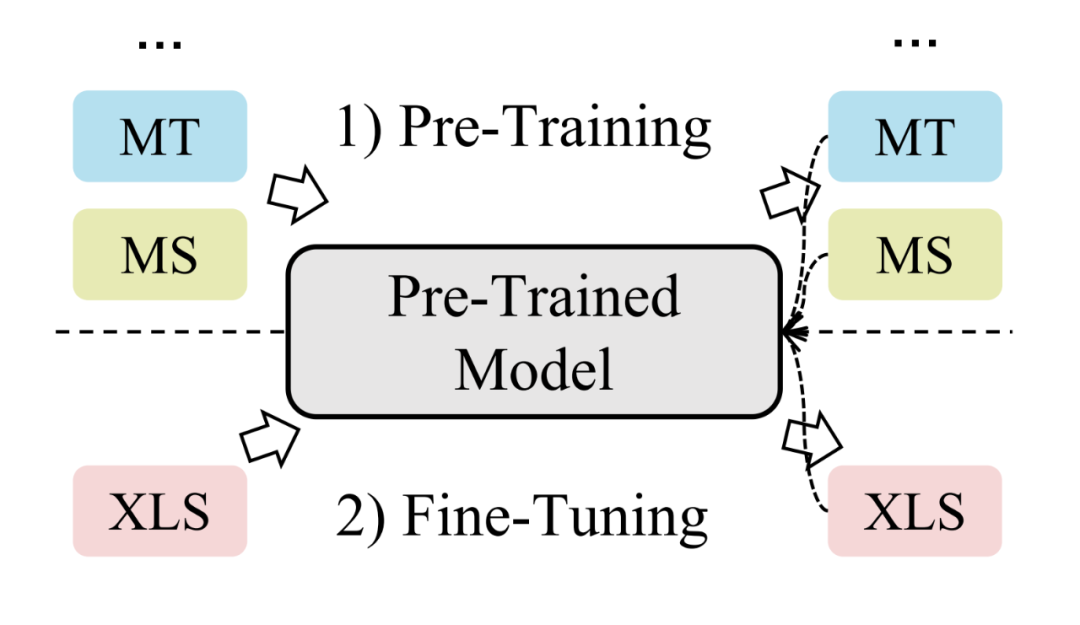
自从 BERT 出世以来,预训练的思想早已深入人心。近年来也涌现出了人们所熟知的多语言预训练模型,例如 mBART [34] 与 mT5 [35]。Liang 等人 [27] 发现简单地微调 mBART 模型就可以超越许多跨语言摘要模型的效果,这也表明了预训练语言模型的强大。然而 mBART 和 mT5 在预训练过程中仅使用了来自多种语言的单语数据进行训练(即输入输出始终为同一种语言,没有任何跨语言监督信号)。这也导致了 mBART 和 mT5 的跨语言生成能力并没有被完全探索。

▲ 常见的跨语言预训练任务
除此之外,还有一些面向通用场景的跨语言文本生成预训练模型。Chi 等人 [38] 提出了 mT6,该模型使用 SC(Span Corruption)和 TSC 作为预训练任务,并在预训练过程中设计了 PNAT 解码策略(一种非自回归的解码方式)。类似地,Ma 等人提出了 DeltaLM 模型 [39],该模型也采用了 SC 和 TSC 预训练任务。

评估指标:当前跨语言摘要的自动评估指标直接借鉴于单语言摘要,然而不同于单语摘要,跨语言摘要包含了<源语言文档, 源语言摘要, 目标语言摘要>,除了 ground truth 目标语言摘要之外,如何利用其余的信息评估模型的生成结果,甚至如何设计 reference-free 的评估指标将是一个有趣的探索点。

在这篇综述中,我们首次对跨语言摘要任务进行了全面的回顾。我们系统性地总结了已有的数据集工作与模型工作,并分别将模型和数据集进行分类,强调每种类别的特点以及优缺点。此外,我们还讨论了跨语言摘要未来值得研究的方向。我们希望这篇综述能够加深研究者对跨语言摘要的理解,并指导跨语言摘要未来的发展。

参考文献
[2] Baotian Hu, Qingcai Chen, and Fangze Zhu. LCSTS: A Large Scale Chinese Short Text Summarization Dataset. In EMNLP 2015
[3] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, Phil Blunsom. Teaching Machines to Read and Comprehend. In NIPS 2015
[4] Yu Bai, Yang Gao, and Heyan Huang. Cross-Lingual Abstractive Summarization with Limited Parallel Resources. In ACL 2021.
[5] Xiachong Feng, Xiaocheng Feng, Bing Qin. A Survey on Dialogue Summarization: Recent Advances and New Frontiers. In IJCAI 2022 (survey track).
[6] Jiaan Wang, Fandong Meng, Ziyao Lu, Duo Zheng, Zhixu Li, Jianfeng Qu and Jie Zhou. ClidSum: A Benchmark Dataset for Cross-Lingual Dialogue Summarization. In ArXiv preprint abs/2202.05599.
[7] Bogdan Gliwa, Iwona Mochol, Maciej Biesek, and Aleksander Wawer. SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization. In EMNLP 2019 New Frontiers in Summarization workshop.
[8] Chenguang Zhu, Yang Liu, Jie Mei, and Michael Zeng. MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization. In NAACL 2021.
[9] Faisal Ladhak, Esin Durmus, Claire Cardie, and Kathleen McKeown. 2020. WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization. In Findings of EMNLP 2020.
[10] https://www.wikihow.com/Main-Page
[11] Laura Perez-Beltrachini and Mirella Lapata. Models and Datasets for Cross-Lingual Summarisation. In EMNLP 2021.
[12] https://www.wikipedia.org/
[13] Hasan, Tahmid, Abhik Bhattacharjee, Wasi Uddin Ahmad, Yuan-Fang Li, Yong-Bin Kang and Rifat Shahriyar. CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs. In ArXiv preprint abs/2112.08804.
[14] https://www.bbc.com/
[15] Constantin Orasan and Oana Andreea Chiorean. Evaluation of a cross-lingual RomanianEnglish multi-document summariser. In LREC 2008.
[16] https://www.etranslator.ro/
[17] Xiaojun Wan, Huiying Li, and Jianguo Xiao. Cross-Language Document Summarization Based on Machine Translation Quality Prediction. In ACL 2010.
[18] Anton Leuski, Chin-Yew Lin, Liang Zhou, Ulrich Germann, Franz Josef Och, and Eduard H. Hovy. Cross-lingual CSTRD: English access to Hindi information. In TALIP 2003.
[19] Xiaojun Wan. Using Bilingual Information for Cross-Language Document Summarization. In ACL 2011.
[20] Boudin, Florian, Stéphane Huet and Juan-Manuel Torres-Moreno. A Graph-based Approach to Cross-language Multi-document Summarization. In Polibits 2011.
[21] Jin-ge Yao, Xiaojun Wan, and Jianguo Xiao. Phrase-based Compressive Cross-Language Summarization. In EMNLP 2015.
[22] Jiajun Zhang, Yu Zhou, and Chengqing Zong. Abstractive Cross-Language Summarization via Translation Model Enhanced Predicate Argument Structure Fusing. In TASLP 2016.
[23] Elvys Linhares Pontes, Stéphane Huet, Juan-Manuel Torres-Moreno, and Andréa Carneiro Linhares. Cross-Language Text Summarization Using Sentence and Multi-Sentence Compression. In NLDB 2018.
[24] Jessica Ouyang, Boya Song, and Kathy McKeown. A Robust Abstractive System for Cross-Lingual Summarization. In NAACL 2019.
[25] Yue Cao, Hui Liu, and Xiaojun Wan. Jointly Learning to Align and Summarize for Neural Cross-Lingual Summarization. In ACL 2020.
[26] Takase, Sho and Naoaki Okazaki. Multi-Task Learning for Cross-Lingual Abstractive Summarization. In ArXiv preprint abs/2010.07503.
[27] Yunlong Liang, Fandong Meng, Chulun Zhou, Jinan Xu, Yufeng Chen, Jinsong Su, and Jie Zhou. A Variational Hierarchical Model for Neural Cross-Lingual Summarization. In ACL 2022.
[28] Ayana, Shi-qi Shen, Yun Chen, Cheng Yang, Zhi-yuan Liu, and Mao-song Sun. Zero-Shot Cross-Lingual Neural Headline Generation. In TASLP 2018.
[29] Xiangyu Duan, Mingming Yin, Min Zhang, Boxing Chen, and Weihua Luo. Zero-Shot Cross-Lingual Abstractive Sentence Summarization through Teaching Generation and Attention. In ACL 2019.
[30] Thong Thanh Nguyen and Anh Tuan Luu. Improving Neural Cross-Lingual Abstractive Summarization via Employing Optimal Transport Distance for Knowledge Distillation. In AAAI 2022.
[31] Junnan Zhu, Yu Zhou, Jiajun Zhang, and Chengqing Zong. Attend, Translate and Summarize: An Efficient Method for Neural Cross-Lingual Summarization. In ACL 2020.
[32] Chris Dyer, Victor Chahuneau, and Noah A. Smith. A Simple, Fast, and Effective Reparameterization of IBM Model 2. In NAACL 2013.
[33] Jiang Shuyu, Dengbiao Tu, Xingshu Chen, R. Tang, Wenxian Wang and Haizhou Wang. ClueGraphSum: Let Key Clues Guide the Cross-Lingual Abstractive Summarization. In ArXiv preprint abs/2203.02797.
[34] Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. Multilingual Denoising Pre-training for Neural Machine Translation. In TACL 2020.
[35] Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In NAACL 2021.
[36] Ruochen Xu, Chenguang Zhu, Yu Shi, Michael Zeng, and Xuedong Huang. Mixed-Lingual Pre-training for Cross-lingual Summarization. In AACL 2020.
[37] Zi-Yi Dou, Sachin Kumar, and Yulia Tsvetkov. A Deep Reinforced Model for Zero-Shot Cross-Lingual Summarization with Bilingual Semantic Similarity Rewards. In ACL 2020 NGT workshop.
[38] Zewen Chi, Li Dong, Shuming Ma, Shaohan Huang, Saksham Singhal, Xian-Ling Mao, Heyan Huang, Xia Song, and Furu Wei. mT6: Multilingual Pretrained Text-to-Text Transformer with Translation Pairs. In EMNLP 2021. [39] Ma Shuming, Li Dong, Shaohan Huang, Dongdong Zhang, Alexandre Muzio, Saksham Singhal, Hany Hassan Awadalla, Xia Song and Furu Wei. DeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders. In ArXiv preprint abs/2106.13736.
[40] Bai, Yu, Heyan Huang, Kai Fan, Yang Gao, Zewen Chi and Boxing Chen. Bridging the Gap: Cross-Lingual Summarization with Compression Rate. In ArXiv preprint abs/2110.07936.
[41] Koh, Huan Yee, Jiaxin Ju, Ming Liu and Shirui Pan. An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics. In ACM Journal of the ACM (JACM) 2022.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
点击「关注」订阅我们的专栏吧



