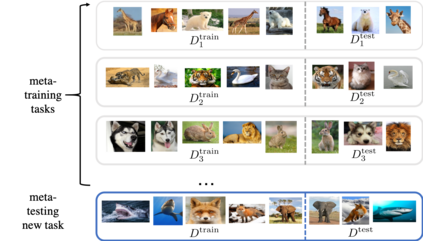
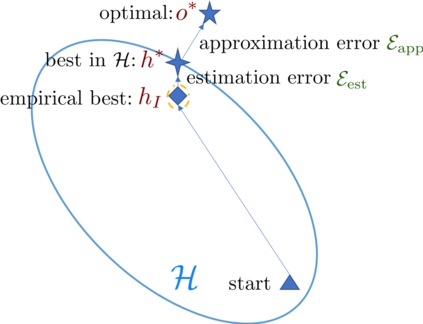
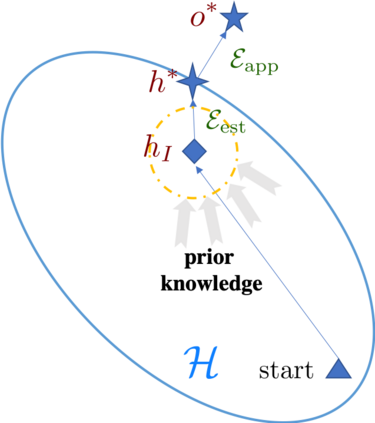
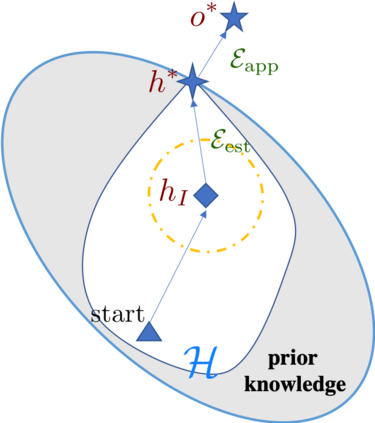
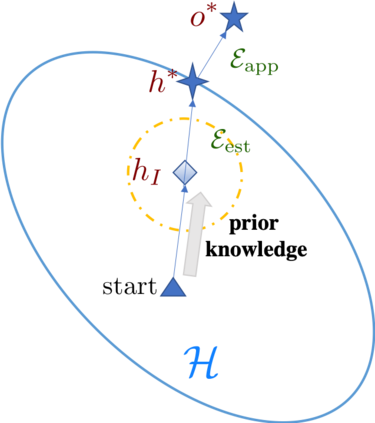
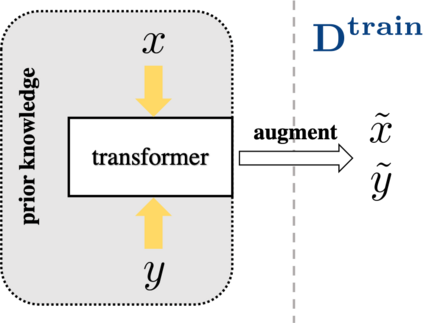
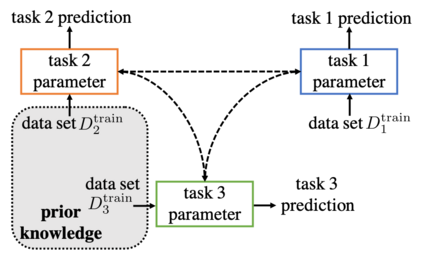
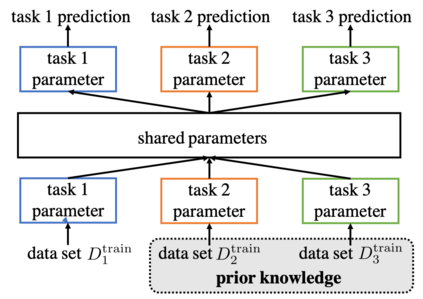
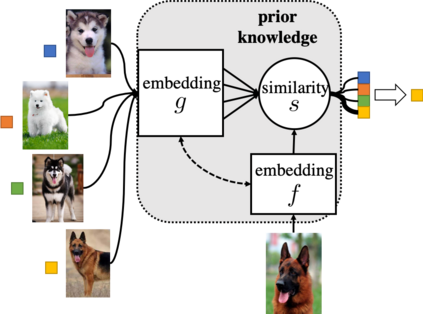
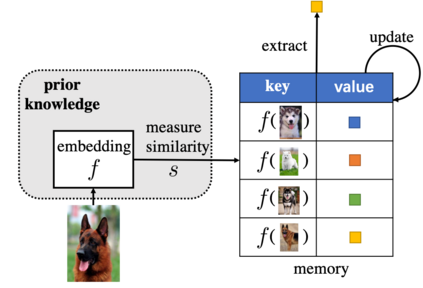
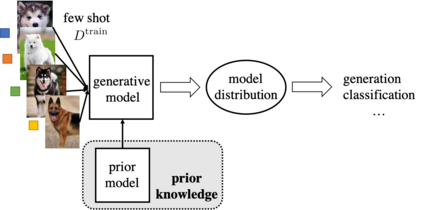
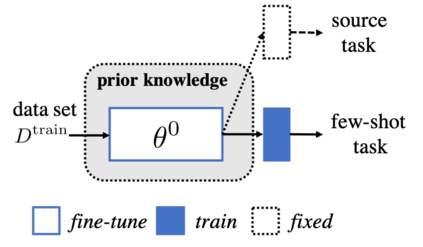
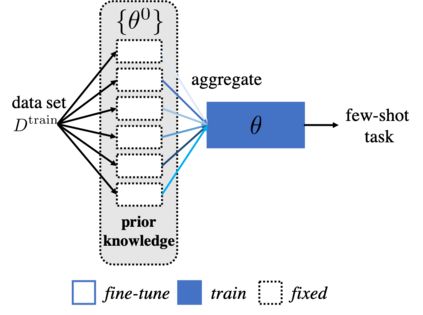
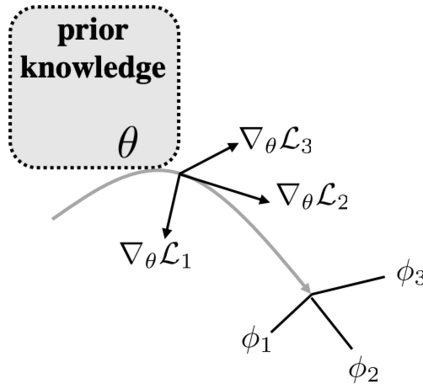
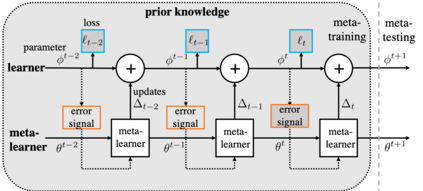
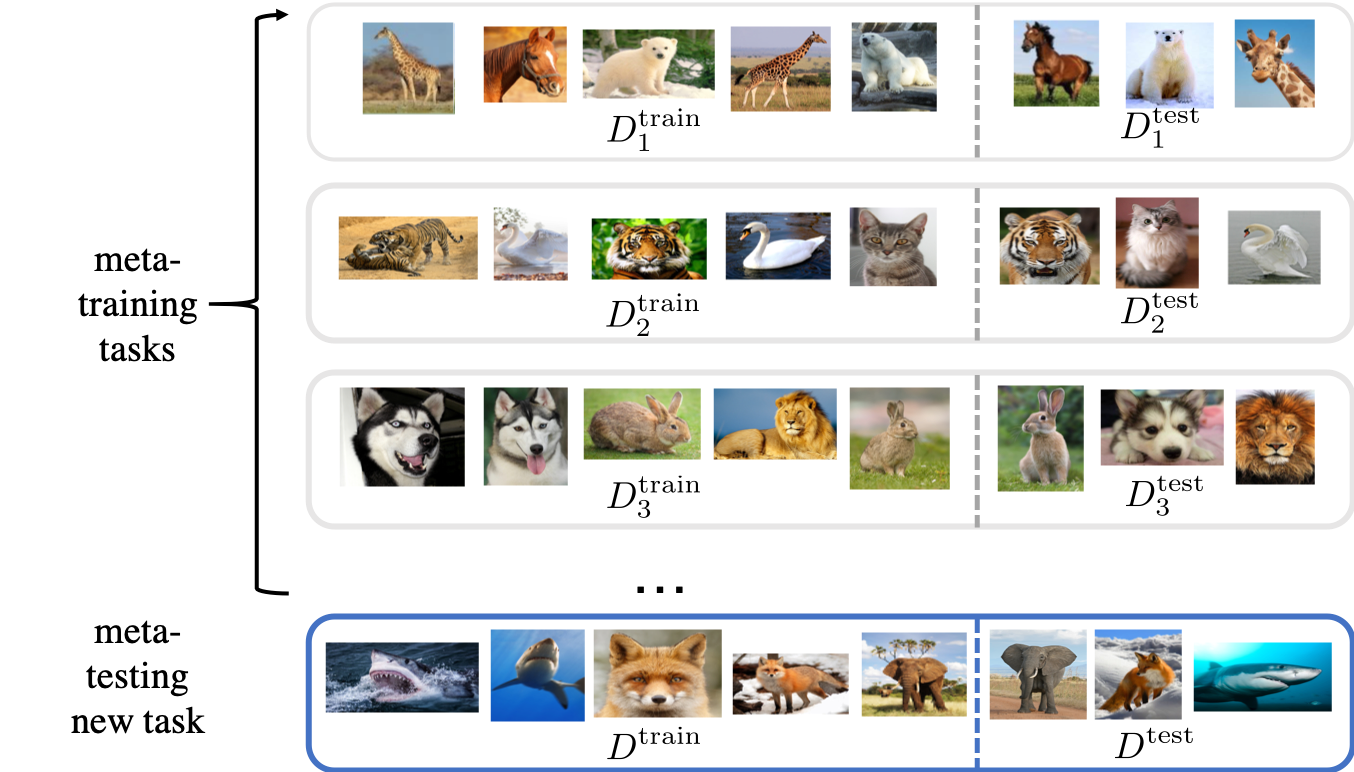
The quest of `can machines think' and `can machines do what human do' are quests that drive the development of artificial intelligence. Although recent artificial intelligence succeeds in many data intensive applications, it still lacks the ability of learning from limited exemplars and fast generalizing to new tasks. To tackle this problem, one has to turn to machine learning, which supports the scientific study of artificial intelligence. Particularly, a machine learning problem called Few-Shot Learning (FSL) targets at this case. It can rapidly generalize to new tasks of limited supervised experience by turning to prior knowledge, which mimics human's ability to acquire knowledge from few examples through generalization and analogy. It has been seen as a test-bed for real artificial intelligence, a way to reduce laborious data gathering and computationally costly training, and antidote for rare cases learning. With extensive works on FSL emerging, we give a comprehensive survey for it. We first give the formal definition for FSL. Then we point out the core issues of FSL, which turns the problem from "how to solve FSL" to "how to deal with the core issues". Accordingly, existing works from the birth of FSL to the most recent published ones are categorized in a unified taxonomy, with thorough discussion of the pros and cons for different categories. Finally, we envision possible future directions for FSL in terms of problem setup, techniques, applications and theory, hoping to provide insights to both beginners and experienced researchers.
翻译:探索“机器思考”和“机器做人的工作”是驱动人造情报发展的探索。虽然最近的人工智能在许多数据密集应用中取得了成功,但是它仍然缺乏从有限的外表和快速推广到新任务方面的学习能力。为了解决这一问题,我们必须转向机器学习,这支持人工智能的科学研究。特别是,一个称为“少点学习”目标的机器学习问题。它可以通过转向先前的知识,迅速将有限的监督经验推广到新的任务,这种知识模仿人类通过一般化和类推从少数例子获得知识的能力。它被视为一个真正的人工智能的测试台,一种减少收集难用数据和计算成本昂贵的培训以及稀有案例学习的解药的方法。随着关于FSL的广泛研究的出现,我们对此进行了全面的调查。我们首先给FSL给出了正式的定义。然后我们指出FSL的核心问题,将问题从“如何解决FSL”到“如何处理核心问题”的先入手。因此,从最近一些关于FSFSL的理论的理论到将来的彻底的理论,从我们所出版的理论到将来的理论,最后的理论,从可能的分类,从FSFSFSFSFS的理论到可能的分类。