【ACL2020】基于语境的文本分类弱监督学习
作者:丁磊 (北京工业大学)
paper: Contextualized Weak Supervision for Text Classification

高成本的人工标签使得弱监督学习备受关注。seed-driven 是弱监督学习中的一种常见模型。该模型要求用户提供少量的seed words,根据seed words对未标记的训练数据生成伪标签,增加训练样本。
但是由于一词多义现象的存在,同一个seed word会出现在不同的类别中,从而增加生成正确伪标签的难度;同时,单词w在语料库中的所有位置都使用一个的词向量,也会降低分类模型的准确性。
而本篇论文主要贡献有:
-
开发一种无监督的方法,可以根据词向量和seed words,解决语料库中单词的一词多义问题。
-
设计一种排序机制,消除seed words中一些无效的单词;并将有效的单词扩充进seed words中。
模型整体结构为:
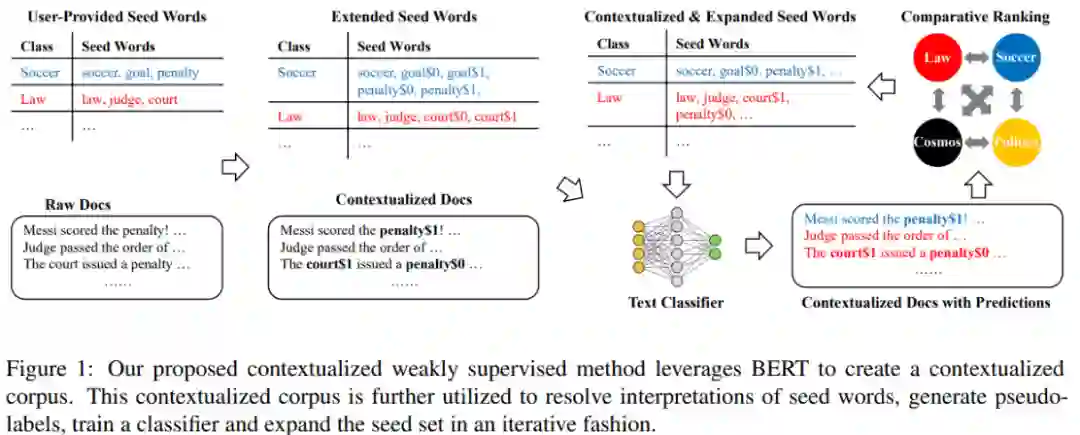
第一步:使用聚类算法解决语料库中单词的一词多义问题
对于每一个单词 w, 假设w出现在语料库的n个不同位置, 分别为 ,使用K-Means算法将 分成K类,这里K可理解为单词w的K个不同解释。
用下列公式计算K的值:
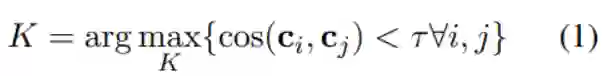
其中
代表第i个聚类中心的向量。
的计算方法如下:
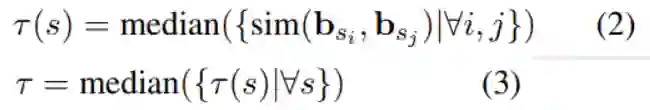
这里s表示一个seed word,且 表示s在语料库第i次出现,对应的词向量为 。
sim() 表示余弦函数,median( )表示取中位数。
则对于任意 ,有
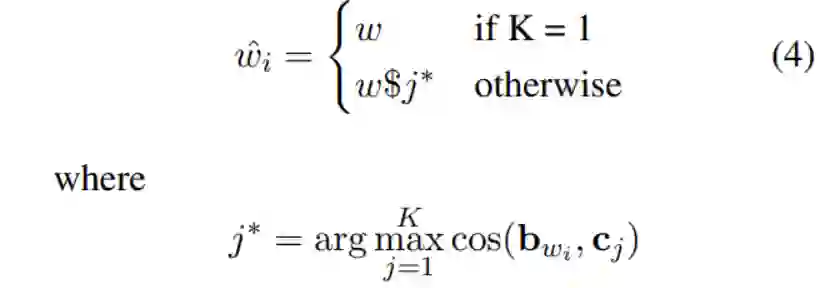
综上,一词多义问题解决算法如下:

使用上面算法,我们就可以将原始语料库转变为基于语境下的语料库:

第二步:对未标记的训练数据生成伪标签令
表示文档d的伪标签;
表示类别为
的seed word 集合;
表示单词w出现在文档d的词频
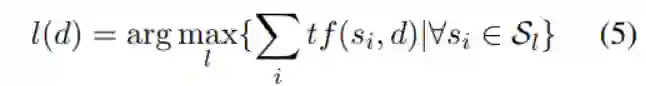
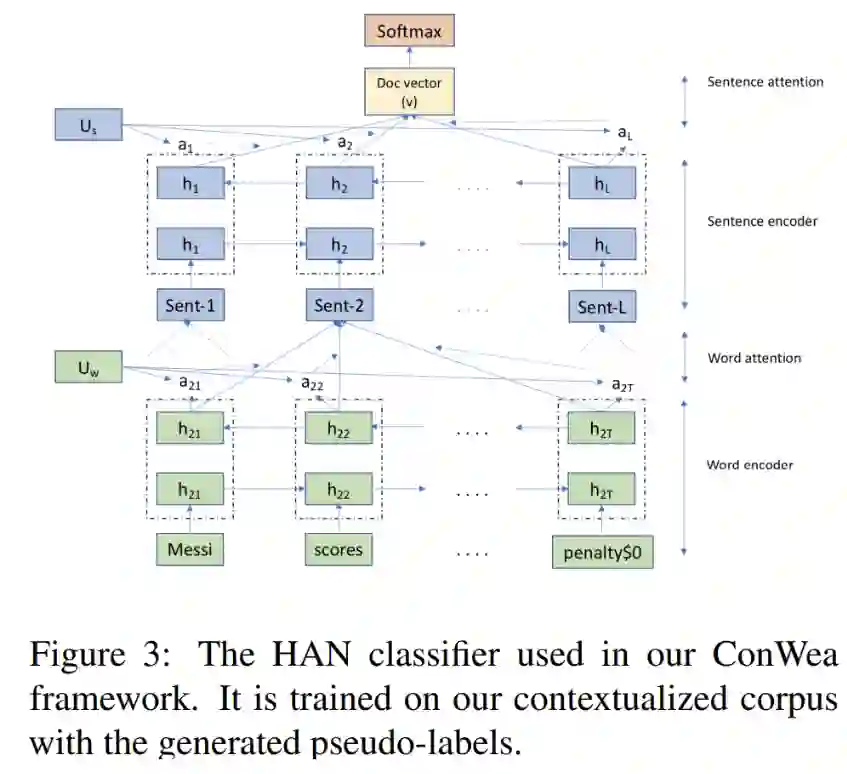
第三步:使用基于语境下的语料库进行文档分类
本篇论文使用Hierarchical Attention Networks (HAN) 进行文本分类。
第四步:设计排序函数,更新seed words我们设计出一个打分函数
,用于表示单词w仅高频的出现在类别为
的文档。分值越高,表示单词w对类别
越重要。我们可以选择分值最高的前几个单词作为新的seed word。也可以剔除一些不重要的seed word。
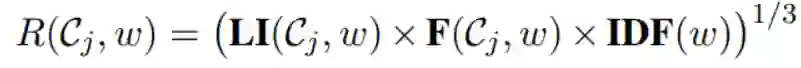
其中:
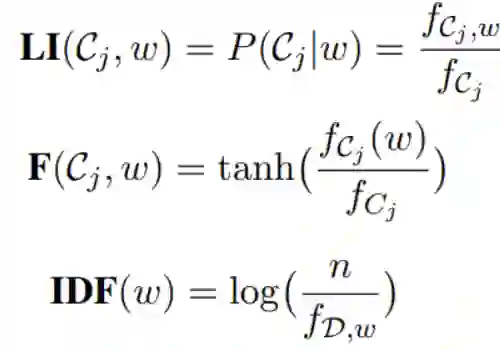
表示类别为 的文档的数量。 表示类别为 且含有单词w的文档的数量。 表示在类别为 的文档中,单词w的词频。
n为语料库D的文档总数目 表示语料库D中含有单词w的文档的数量。
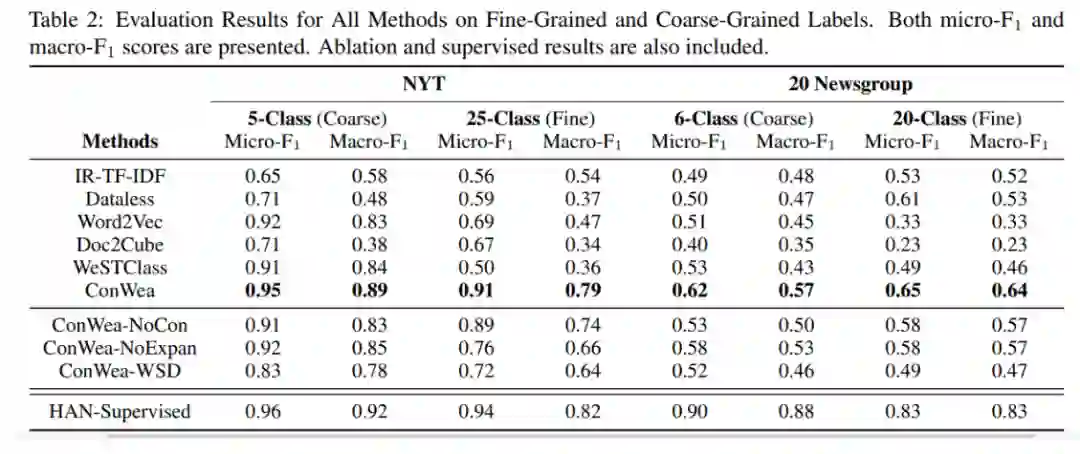
结果
我们的完整模型称为 ConWea,
而 ConWea-NoCon是 ConWea确实缺少第一步的变体。
ConWea-NoExpan是 ConWea确实缺少第四步的变体。
ConWea-WSD是将 ConWea第一步的方法换成Lesk算法。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!





