博客 | 度量学习笔记(一) | Metric Learning for text categorization

本文原载于微信公众号:磐创AI(ID:xunixs),欢迎关注磐创AI微信公众号及AI研习社博客专栏。
作者 | Walker
编辑 | 安可
出品 | 磐创AI技术团队
目前,机器学习中的K近邻(KNN)分类算法和支持向量机(SVM)算法被认为是处理文本分类的最好方法。但KNN分类算法有以下的缺陷:
KNN是基于近邻度量的一种模式分类算法,它高度依赖于数据间的相似度度量,简单的欧式距离在实际应用时,由于不考虑不同维度之间对分类的影响以及输入数据数据维数高的问题,往往不能取得良好的分类效果。
KNN 分类算法虽然可以一定情况下克服数据偏斜带来的分类误差,但是这也是造成它对样本密度分布敏感的主要原因,当类间密度高度分布不均时,分类效果会有较大的影响。
解决方案:要想提高KNN文本分类的准确率,首先要解决的是距离度量的问题,于是我们就要用到距离度量算法,其中的大边界最近邻算法(Large Margin Nearest Neighbor, LMNN)是一类专门改进 K 近邻分类算法的距离度量算法。
那么什么是度量学习呢?度量学习 (Metric Learning) 是人脸识别中常用的传统机器学习方法,由Eric Xing在NIPS 2002提出,可以分为两种:一种是通过线性变换的度量学习,另一种是通过非线性变化的度量。其基本原理是根据不同的任务来自主学习出针对某个特定任务的度量距离函数。后来度量学习又被迁移至文本分类领域,尤其是针对高维数据的文本处理,度量学习有很好的分类效果。
LMNN是最常使用的一种度量学习算法,其可以通过对训练集学习来得到一种原始数据的新度量,这种方法可以在一定程度上对原始数据分布进行重构,得到一个更加合理的数据分类空间。其次,要解决的就是样本密度分布不均的问题,在应用LMNN 算法时我们注意到可能会加剧样本的密度分布不均衡,我们通常采用裁剪或是填充的方案。
大边界最近邻算法(LMNN)是用于度量学习的统计机器学习算法。它学习了为k近邻分类设计的伪测量,是以监督方式学习该全局(伪)度量的算法,以提高k最近邻规则的分类准确性。该算法基于半定规划,是凸优化的子类。LMNN背后的主要直觉是学习伪测量,在该伪测量下,训练集中的所有数据实例被至少k个共享相同类标签的实例包围,该算法学习该类型的伪测量:

矩阵M 需要是正半正定的。欧几里德度量是一个特例,其中 M是单位矩阵。这种概括通常被称为Mahalanobis度量。
LMNN样本训练前后的示意图如下所示:
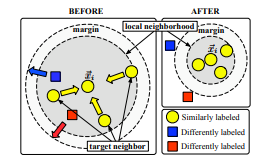
基于 LMNN 算法的文本分类:文本分类首先要对文本进行特征提取将待测试文本和训练文本表示成向量空间模型(Vector Space Model, VSM),定义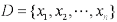

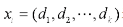
算法流程:
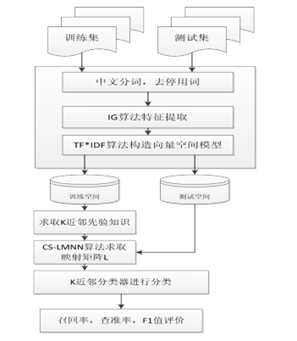
(1)首先,对中文文本文本进行分词、去停用词等预处理。
(2)对文本进行特征选择,本文选用了IG 这种常用的的特征提取算法来对文本进行特征提取。
(3)构造向量空间模型(Vector SpaceModel,VSM),本文所采用的是经典TF*IDF 法。
(4)对训练样本以欧氏距离用留一法计算出训练集中每个数据点的先验知识 K近邻,并做好标签,设定此 K 值为 Kp 。
(5)利用 LMNN 算法对训练集进行学习,求出映射矩阵 L。
(6)对训练样本和测试样本分别作映射。
(7)跟据上一节中所提出的基于 LMNN 的文本分类算法对测试集进行分类。
此外,在LMNN的基础上,又有人提出了基于密度加权的 LMNN 分类算法(DLMNNC):这是因为在将 LMNN 算法与 KNN 结合时由于 LMNN 算法的特点在很大程度上可能会增加样本密度分布不均匀,在应用于文本分类仍然会有较大的误差。
针对此,我们又提出了基于密度加权的 K 近邻分类算法和 LMNN 文本分类算法相结合,称之为 DLMNNC 算法.可以一定程度上解决上述由于 LMNN 的引入所造成的密度分布更加不均匀问题。例如某网站中娱乐类新闻明显要比历史类新闻要多的多,这就有可能造成经特征提取后的数据点在某种度量意义下密度分布不均衡,特别地在应用 LMNN算法来对样本点进行距离度量学习时:
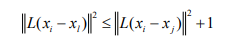
描述了了在目标样本 i x 在其 K 个近邻中噪声点(impostor)的标准,并且以此定义非等价约束条件,对近邻中的异类点有一个推力作用,使其在马氏距离度量意义下远离目标样本。
密度公式:
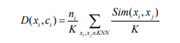
其中, i x 为 j x 的 K 近邻点, (,) Dx c i i 表示 K 近邻中类标签为 i y 向量的密度,K 为最近邻数, i n 为类标签为 i y 的 K 近邻中向量个数,K近邻决策公式表示为:
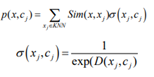
基于余弦的距离度量学习(CS-LMNN)算法:对于文本数据余弦距离度量要比欧式距离度量要好一些,这主要因为:对于不同向量,方向性要比数值更加重要,而传统的欧氏距离度量标准只对数值敏感,并没有利用向量之间的方向性。而余弦相似度和欧式距离度量相比较,更加注重两个向量在方向上的差异,而非距离或长度。
根据类标签相同的点应尽量相近,类标签不同的点应尽量远离这两个条件我们提出了一种新的基于余弦的距离度量学习算法,称之为 CS-LMNN 算法。该算法和 LMNN 算法类似,也需要训练集的 K 近邻先验知识同样以 Kp表示,它根据余弦夹角的性质,即任意夹角的余弦值不可能大于 1,这一条件来构造非等价性约束,然后,在最优化表达式中,通过最小化近邻同类标签样本的余弦距离来构造等价性条件。最终,将两条件改写为一个最优化问题进行求解。具体算法流程如下:首先,定义余弦距离度量,在训练集 D中任意两点 ,i j x x 间的余弦距离度量表达式:
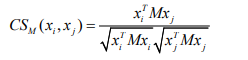
目标样本 i x 具有类标签 i c 在其 K 近邻点中有 l x 类标签为 l c ,定义噪声点为对任意目标样本 i x 有 l i c c ≠ ,满足:
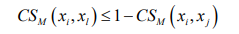
损失函数:
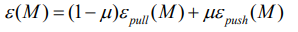
基于余弦距离度量(CS-LMNN)的文本分类算法的具体流程如下:
PFLMNN:Parameter Free Large Margin Nearest Neighbor for DistanceMetric Learning:PFLMNN(无参数大边界最近邻)是一种新的度量学习算法,不同于LMMN将目标邻居拉到一起,同时将冒名顶替者推开,我们的方法只考虑将冒名顶替者推出邻居的行为。这种方式与LMNN相比,我们简化了我们的优化问题的任务。
为了提高k个最近邻之间的距离和查询的能力,PFLMN是一种利用LMNN忽略的冒名者之间的几何信息推送冒名者的新方法。简而言之,仅考虑每个查询的最近活动冒名顶替者。根据距离度量,当最近的冒名顶替者不在附近时,所有其他冒名顶替者都不在。通过这种方式,减少了由冒名顶替者显示的需要被推动的约束,使得所提出的模型在不削弱其约束能力的情况下将更加简单。
因此,与LMNN相比,PFLMNN模型更容易被优化。此外,由于模型只包含一个项,因此不需要调整成本函数中的参数,使得该方法更便于使用。我们比较一下LMNN与PFLMNN的异同,LMNN是k=3邻域在小半径内被拉在一起,而具有不同标记的输入被从小半径内拉出有限边距。
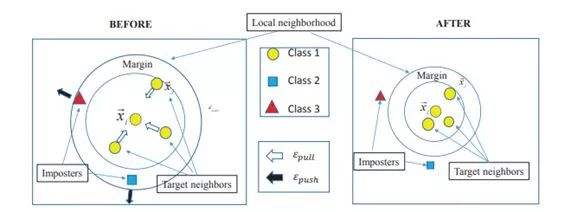
LMNN原理图

PFLMNN原理图
如图所示,与LMNN不同的是,PFLMNN只采取拉不同标记输入的动作。以有限的余量从小半径中拉出来,这样模型更加简单,易被优化。
【总结】:本文从中文文本分类问题出发,介绍了LMNN、DLMNNC、CS-LMNN、PFLMNN等几种常见的几种度量学习。对度量学习以及及机器学习感兴趣的小伙伴,欢迎持续关注我们的公众号【磐创AI】,以及后续度量学习的系列教程。
欢迎扫码关注磐创AI微信公众号


点击 阅读原文,查看更多内容




