过参数化、剪枝和网络结构搜索
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:YE Y
来源:https://zhuanlan.zhihu.com/p/74553341
本文已经作者授权,禁止二次转载
字好多啊不想读,但是我想试一试只需要四行代码就可以给PyTorch模型提供通道剪枝全套服务,同时还支持OpenVINO进一步加速的netslim:
↓↓↓ 翻到文章最后一部分,有使用简介和Github链接 ↓↓↓
========== 正文分割线 ==========
过参数化(Over-parameterization)
从U曲线到
曲线
自诞生起,神经网络就常常与大参数量联系在一起,并且是其常常被诟病的缺点之一。在深度学习刚冒出来时,网络参数动辄比数据量大千百倍的过参数化更是家常便饭。甚至有一种言论认为深度学习就是一种过拟合(over-fitting),过拟合是啥呢?看下图:
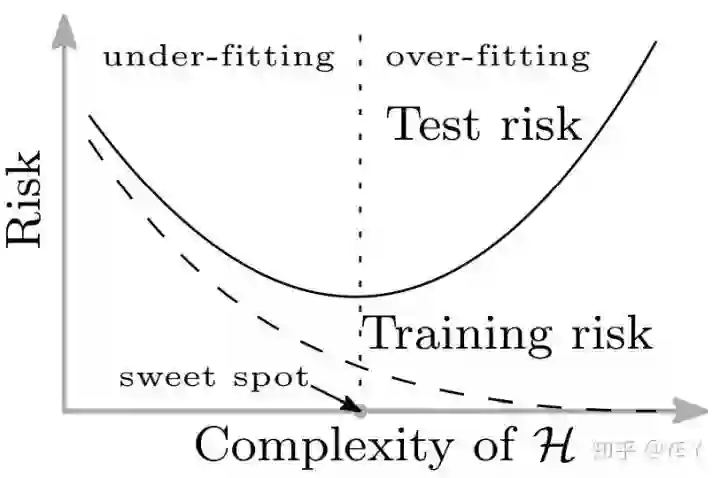
这个就是机器学习里著名的U-curve,简单来说过拟合就是在训练数据上表现良好,但是这种表现没法泛化(generalize)到其他的同分布数据上,比如测试数据。
深度学习有没有过拟合呢?随便搞个参数量大的网络是很容易实现过拟合的,不过在ReLU这种分段线性激活函数大行其道的今天,再加上各种trick的帮助,过拟合已经不是一个特别值得担心的问题。甚至大体上来讲,差不多架构的网络,参数量越大,效果是越好的。比如常见的VGG、ResNet和DenseNet等,当然是名字后面数字越大的效果越好。更变态的比如BigGAN、GPipe之流,作者们明知道对大部分人也没啥用,还是发表出来,也许就是想告诉我们,真的是参数量越大越好吧。

是传统的观点错误了吗?其实也可能是深度学习打开了新世界的大门:
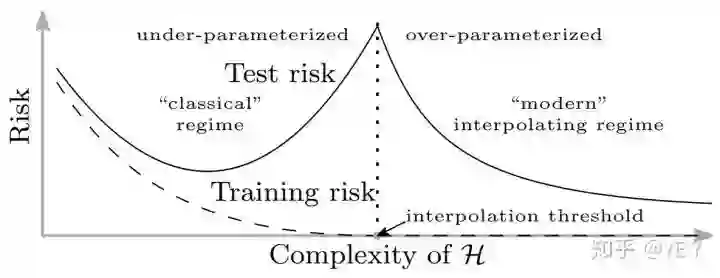
上图来自论文《Reconciling modern machine-learning practice and the classical bias–variance trade-off》(arXiv版本:1812.11118)。说的是对于神经网络,当复杂度不够高的时候,U曲线是成立的。而当复杂度达到某一个临界点,就来到了新的世界:
论文 链接:
https://www.pnas.org/content/116/32/15849
1812.11118 链接:
https://arxiv.org/abs/1812.11118
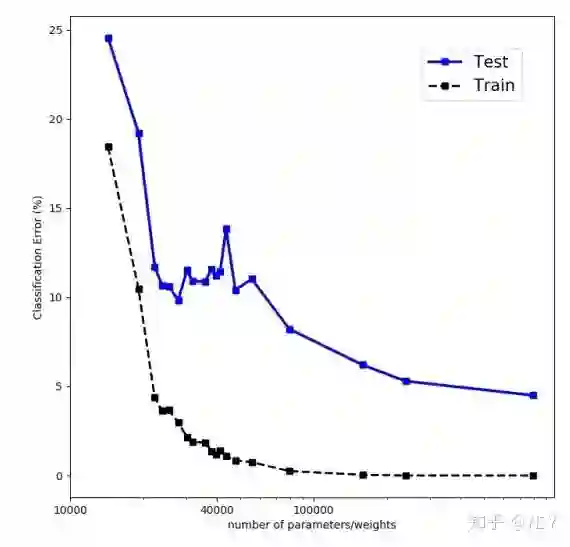
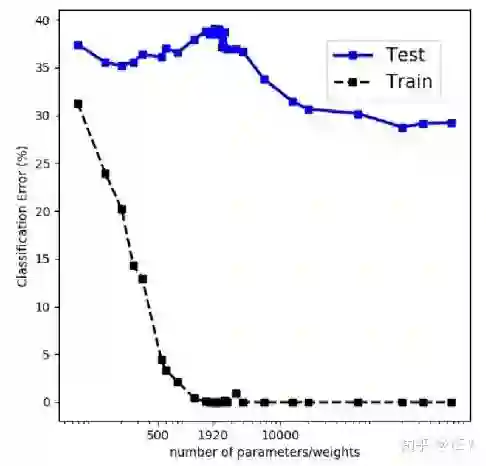
这个曲线可能看上去过于随意了些,后续有个工作把这个现象和颗粒物质的阻塞现象联系了起来,里面的实验结果看上去更加明显一些。虽然个人感觉这个现象到了CNN上有可能站不住脚(如果有哪位大佬试了,或者发现有人试了恳请留言告知),但是至少说明了一个其实很显然的结论:用传统观点看待神经网络的过参数化是行不通的。
工作 链接:
https://arxiv.org/abs/1810.09665
过参数化和冗余性
为什么参数量越大就越好呢?我不太熟悉这个领域,不过Google一下,感觉经常提到的一个词是Redundancy。参数多了就会带来冗余,参数过多也是可以产生冗余的必要条件,这是个很自然的结论,但冗余真的能提高模型的性能吗?Dropout也许能带来一些启示。比如这本书里提到了一种网上很常见的说法:Dropout会迫使网络学习到一定程度的feature redundancy,这种类型的redundancy是可以提高模型鲁棒性的。Dropout最早的出处是在论文《Improving neural networks by preventing co-adaptation of feature detectors》看名字就知道Dropout是用来防止co-adaptation的。Co-adaptation的意思是说,一个学到的feature如果需要其他feature一起才能发挥作用,那就说明他们之间是一种co-adaptation的关系。所以冗余性的体现也许可以理解为,减弱了co-adaptation就等于说缺了其他的一些feature,剩下的部分feature仍然能比较完整的保留针对任务所需要的信息。
这本书 链接:
http://www.charuaggarwal.net/neural.htm
论文 链接:
https://arxiv.org/abs/1207.0580
其实这个结论个人来说似懂非懂,不过沿着冗余有助于提升鲁棒性进而提升泛化的角度来看Dropout的一些后续工作(各种DropXXX和XXXout),好像都挺有道理。顺便一提的是,按照ResBlock层来drop的Stochastic Depth,指出了layer级的feature redundancy(或者叫re-use),后来作者又指出ResNet的Skip-Connection可以看作是一种很直接的feature replication。从冗余性的角度,前者提高泛化性,后者避免专门为replication的计算量,放一起就是DenseNet。
Stochastic Depth 链接:
https://arxiv.org/abs/1603.09382
DenseNet 链接:
https://arxiv.org/abs/1608.06993
过参数化和运气
提到运气,就会自然而然地想到赌(A)博(gu),哦不对,彩票。ICLR2019的best paper,《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》正是这样一项研究。文章提出了“彩票假设”:在一个随机初始化的神经网络中,存在一个中奖子网络(winning ticket),这个子网络拿出来单独训(差不多同样的迭代次数),效果和原网络差不多。文章提出了一种非常简单的训练策略,给定一个权重可以表示为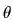
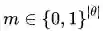
best paper 链接:
https://openreview.net/forum?id=rJl-b3RcF7
先训练一遍
所有权重按绝对值排序
把权重绝对值最小的p%部分权重对应的m置为0
将权重重新初始化为训练前,则得到了一张winning ticket
可以选择迭代上述步骤,作者在文章中默认也是要迭代的,并且在后续的改进版中,管这个过程叫做IMP(Iterative Magnitude Pruning)。
改进版 链接:
https://arxiv.org/abs/1903.01611
按照这个思路,理所应当的参数量越大,包含潜在winning ticket的数量就会越多,而其他的部分只是在陪跑而已……其实这也有点类似于遗传算法的感觉,population越大,效果通常越好,当然是有运气成分啊。
一个相近的研究是FAIR大佬Tian, Yuandong的《Luck Matters: Understanding Training Dynamics of Deep ReLU Networks》。文中验证运气的方式是提出了一种小teacher-大student的训练框架(基于ReLU的MLP),然后发现,对于一个参数足够小使得node间overlap很小的teacher小网络,student大网络中和teacher网络中重合度最高的node对应的权重收敛速度更快,并且那些无关权重的fanout会渐渐向0收敛。
研究 链接:
https://arxiv.org/abs/1905.13405
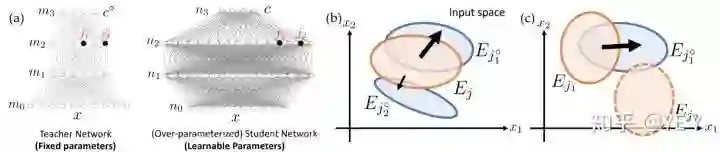
用来解释Lottery Ticket假设就是下图b,两个橙色圈就是winning ticket
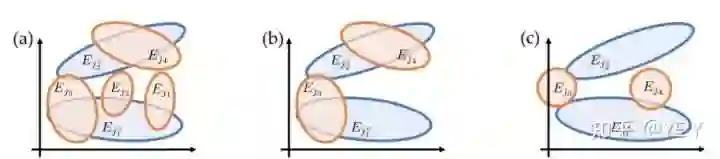
对于神经网络能训练随机标签的数据,也有相应解释

在大佬的专栏里也专门对这篇有所提及:求道之人,不问寒暑(三)。从运气的角度来看,随机初始化包含了运气,那基于finetune的迁移学习算不算是强行整来winning ticket,加大了好运气呢?
求道之人,不问寒暑(三)链接:
https://zhuanlan.zhihu.com/p/67782029
过参数化和优化
其实从训练/优化角度看待过参数化的研究才是最多的,相关论文古已有之。比如这篇1991年的文章摘要里就指出:参数足够多的情况下,神经网络里几乎肯定不会遇到local minimum。上一小部分提到的文章里其实也可以算到优化角度看待过参数化的范畴里,这部分的文章数量大,且看不太懂,就不详细讨论了。
文章 链接:
https://ieeexplore.ieee.org/document/155333
总之,大体上的一个感觉是,过参数化的正面作用主要体现在训练上。如果是从inference的角度,那就完全不一样了。
剪枝(Pruning)
无论大参数量对训练有再大帮助,实际部署的时候都不是一件好事,尤其是对不在Google,FAIR和各种壕研究组的穷人来说。从实用角度,剪枝的必要性是毋庸置疑的。
和对过参数化的研究一样,神经网络压缩和剪枝的研究也是古已有之。1989年,LeCun巨佬就发了一篇《好脑残》(Optimal Brain Damage),基于Hessian矩阵的对角元素,计算了和权重平方的乘积,命名为saliency作为贡献指标。后来在1993年,当时还在Stanford读PHD的Hassibi把Hessian矩阵的对角元素近似假设去掉,发了一篇OBD的加强版叫《治好脑残》(Optimal Brain Surgeon)。
《好脑残》链接:
http://papers.nips.cc/paper/250-optimal-brain-damage.pdf
《治好脑残》链接:
http://papers.nips.cc/paper/647-second-order-derivatives-for-network-pruning-optimal-brain-surgeon.pdf
深度学习崛起后,常见剪枝paper都会提到2015年Han, Song的《Learning both Weights and Connections for Efficient Neural Network》,方法是直接把权重里绝对值小的给剪去,当然在作者基于Caffe的实现中,并没有真的“剪”,而是实现了一个和前面提到彩票那篇一样的mask用来做实验。这种最细粒度的权重裁剪可以获得非常高的压缩率,对于一些比较原始简单的网络设计,十几二十倍的压缩率是家常便饭。注意这篇还没有给权重加上sparsity constraints,后续的各种改进效果要更好。但是此类方法的缺点是,压缩后的模型带来的计算量节省并不是立竿见影的,得需要有硬件或是底层代码层面的支持,否则对sparse matrix以及CNN等操作的计算支持并不是常见框架所支持的。这种剪枝方法通常被称为unstructured pruning。相应的另一派流行的方法叫做structured pruning,剪枝的粒度是channel及以上级别的,当然常见paper几乎都是基于channel的。这样压缩率并没有被逼到很极致,但是通常都可以直接支持在现有的计算框架里使用。此类方法也多如牛毛,尤其是最近两年感觉非常火爆。
剪枝paper 链接:
http://papers.nips.cc/paper/5784-learning-both-weights-and-connections-for-efficient-neural-network
除了按照unstructured/structured划分,具体到CNN来说,剪枝方法通常还可以按照所依据的评判标准来划分,最常见的有基于channel magnitude、基于对loss的贡献(或者有些文献叫sensitivity)还有基于channel的可重建性等。光是看字面也能感觉到,基于magnitude似乎是最简单的,因为magnitude是三类里最容易得到的。
本文主要介绍的是围绕一篇基于magnitude的structured pruning的文章,发表在ICCV2017的《Learning Efficient Convolutional Networks Through Network Slimming》。从实用角度来看,这篇文章是我个人认为现有剪枝文章里最易于实现的一篇。文章的方法异常的简单,channel的贡献可以和Batchnorm层关联起来,如果channel后的batchnorm层中对应的scaling factor足够小,就说明该channel的贡献可以被忽略,如下图所示:
文章 链接:
http://openaccess.thecvf.com/content_iccv_2017/html/Liu_Learning_Efficient_Convolutional_ICCV_2017_paper.html
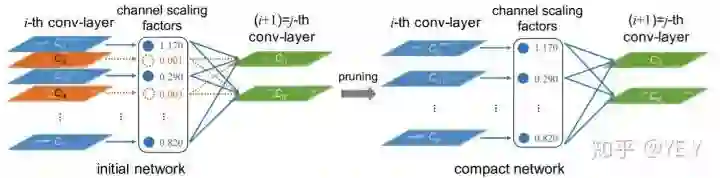
训练的时候只需要在所有BN层的scale factor上加一个L1的约束就完事了。训练完后按照一个给定的百分比对所有可剪枝的BN层的channel进行排序,然后剪去magnitude最小的channels。其实如果把BN的scaling factor看作是一个代理的变量的化,本质上这个方法进行剪枝依据的是channel的幅度(的统计)。后来ECCV2018的文章《Data-Driven Sparse Structure Selection for Deep Neural Networks》中,这个思想被进一步一般化并推广到了更多的结构上,比如一个channel group,或者是一个residual block。不过就训练和部署时的繁琐程度来说,还是基于BN选channel的方法最简单。
文章 链接:
http://openaccess.thecvf.com/content_ECCV_2018/html/Zehao_Huang_Data-Driven_Sparse_Structure_ECCV_2018_paper.html
剪枝和网络结构搜索(Neural Architecture Search, NAS)
剪枝的各种方法里,有一个非常常见的套路是:训练-剪枝-微调三步走

微调这一步隐含了一个假设,就是完整结构的大网络训练出的参数,对最终结果是有贡献的。这种想法,其实和Lottery Hypothesis文章中的思路是有共通之处的,背后的一个思想是:参数和结构是紧密相连的。在Lottery Hypothesis里,通过实验验证了如果winning ticket没有用一开始的那组参数初始化,结果相比起来就会变差。
这个观点在同样是ICLR2019,也是上一部分Network Slimming作者的文章《Rethinking the Value of Network Pruning》中,则发现了看上去完全相反的结果:一个通过剪枝得到的模型结构,如果从头开始训练,会得到不比finetune差,甚至是更好的结果。同样是ICLR2019的另一篇文章《SNIP: Single-Shot Network Pruning Based on Connection Sensitivity》也报道了类似的观察。
文章 1链接:
https://openreview.net/forum?id=rJlnB3C5Ym
文章 2链接:
https://openreview.net/forum?id=B1VZqjAcYX
这是个很有意思的问题,不仅仅因为是两篇ICLR的文章,得到了看上去完全相反的结论,更因为如果参数和结构可以解耦开来的话,那剪枝就是NAS的一种特殊情况了,而且是计算cost很低的那种。
相关问题插播:我在一个问题下的回答,介绍的是另一个用剪枝进行NAS的方法
如何评价论文:Slimmable Neural Networks?
链接:
https://www.zhihu.com/question/306865592/answer/780032130
在Lottery Hypothesis中,对这个现象给出的一个可能解释是:winning ticket中的参数,和最终参数的“距离”会比较近,甚至最极端的情况下,一些参数已经是最终参数了。换句话说,一出生就是人生赢家,正是前面提到的运气。不过原文里就在作者给出这个解释的下一句,就很幽默的表示,通过实验,发现winning ticket的权重通常“走”得比其他权重更远……最后作者认为初始化这件事情,是和优化算法相关的……坦白讲这一番令人窒息的操作我没看太懂,不过winning ticket会走得更远我倒是感觉好有道理,反正无关的参数,训也是白训嘛。Luck Matters里面讲的fanout为0也许和这个现象也是联系在一起的,更远的我觉得今年CVPR倍受争议的RePR也许也是关联的,也许作者把非winning ticket拿出来re-pr一下没准就又是一篇CVPR。后来作者在比较新的一篇论文《Stabilizing the Lottery Ticket Hypothesis》中进一步通过实验比较了这个现象和sparsity的联系(还比较了SNIP),看上去很有道理,虽然实验还是在CIFAR-10上。
因为是open review,所以Lottery和Rethinking两篇文章互相也有提到对于train-from-scratch结果差异的讨论。除了上一段,Lottery给出的解释是,Rethinking文章中实验剪枝达到的sparsity并没有很高,如果超过了某一个值之后,initialization就变得重要了,并用VGG做了实验。而在Rethinking一文中,则给出了更全面和仔细的比较:1)structured pruning和unstructured pruning的区别;2)实验复杂度的区别,Lottery中不仅结构简单,数据也只是MNIST和CIFAR;3)学习率的区别,相比起来,Lottery中的学习率都很小。关于第三点,作者本人在知乎上也有一个回答讨论了这件事:
如何评价ICLR 2019最佳论文《The Lottery Ticket Hypothesis》?
链接:
https://www.zhihu.com/question/323214798/answer/678706173
另外有一篇Google的文章里也用了更多实验分析过这个问题
The State of Sparsity in Deep Neural Networks
文章链接:
https://arxiv.org/abs/1902.09574
大体来说还是可以得到的结论是,对于一定程度sparsity的structured pruning,train-from-scracth是可以的。
其实就initialization是否重要这件事情,我觉得更有意思的问题是,比起通常给定结构优化学习参数的方法,还有关注点只集中在网络结构的NAS,是不是有可能两种一起学习呢?比如有些paper里把一个学习出的结构对random seed的响应归为reproducibility
https://arxiv.org/abs/1902.08142
https://arxiv.org/abs/1902.07638
不知道有没有专门研究random initialization对NAS结构的影响的文章。如果有的话,设想一下,有个特殊的,对initialization很敏感网络结构,就像winning ticket一样,换个random seed初始化就效果不好,可是不换的话用起来也没什么问题。那如果学出这样的模型,算不算一个好的模型呢?我对NAS没什么了解,不知道是不是有那些基本理解是错误的。如果有哪位熟悉NAS大佬看到这篇文章,还希望能留言或回答指点一二
有没有专门研究random seeds/initialization对NAS影响的文章?
链接:
https://www.zhihu.com/question/339954808
netslim
其实写这篇文章最开始是因为最近刚好工作中用到了一下剪枝,所以翻了翻论文接触一下这个领域。虽然不会继续做,不过利用周末把实现方法重写整理了一个包:netslim。netslim提供从训练、剪枝到测试的全流程支持。和其他常见的Slimming的开源代码相比,最大好处是pruning部分不需要写任何代码,可以用于一些自定义的网络。训练和剪枝只需要在原有代码基础上添加几行,很方便。步骤如下:
1、在训练脚本中import更新BN的函数
from netslim import update_bn
2、在loss.backward()和optimizer.step()之间加入一行代码
update_bn(my_model)
3、训练结束后对模型进行剪枝
from netslim import prune
# For example, input_shape for CIFAR is (3, 32, 32)
pruned_model = prune(model, input_shape, prune_ratio=0.5)
4、读取保存好的剪枝后模型就可以用啦
from netslim import load_pruned_model
my_model = MyModel()
pruned_weights = torch.load("/path/to/pruned-weights.pth")
pruned_model = load_pruned_model(model, pruned_weights)
...
大体的原理是利用了torch.jit的traced graph,从里面提取了BN层的连接关系,找到那种只和Conv还有Linear相连接的BN层,标定为可剪枝的BN层,然后执行通道剪枝算法,对相应的Conv和Linear层也进行剪枝。load剪枝后权重的时候,采取比较dirty的策略,就是直接在内存中将已经初始化好的Conv(groups=1)和Linear按照剪枝后的权重进行替换,从而实现不需要任何专门代码的剪枝部署。当然了,因为可以被剪枝的BN有限制,而且没有专门的代码,比如Network Slimming作者官方代码中用的channel selection,所以对于一些有Skip-Connection的模型,剪枝的sparsity会有损失。
虽然方法有些dirty,不过经过初步测试可以export到onnx(完整测试进行中,后续会更新),这样用起来就没差了,用到一些后续改进中也有比较大的想象空间,比如CPU上OpenVINO的进一步优化加速。
在CIFAR-100数据上,基于netslim用VGG-11、VGG-11简化版、ResNet-18和自己瞎改的一个DenseNet-63做了测试,结果如下:
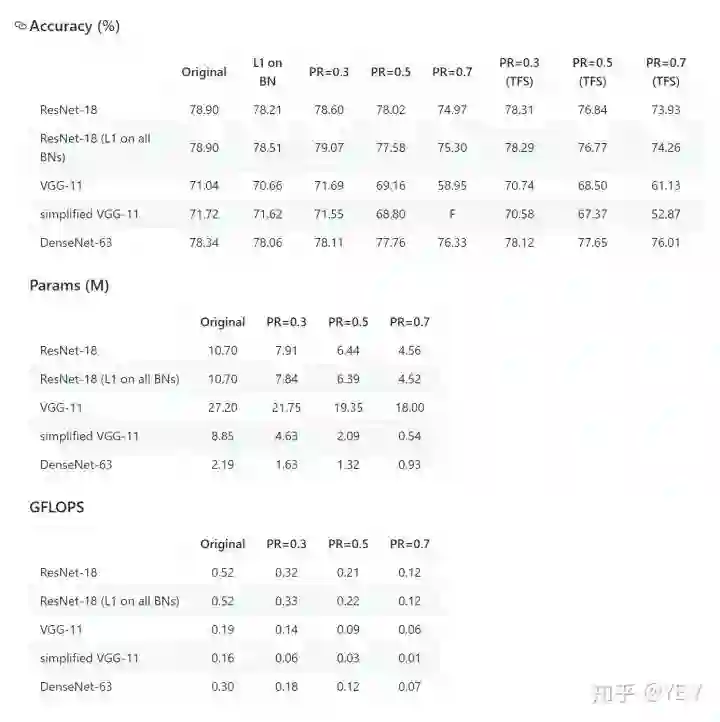
其中TFS总体并没有复现Rethinking文章的结果,不过也很接近finetune,我想主要原因可能因为finetune的运行成本低,所以我做了一点点weight decay的调参。而因为贫穷,TFS就直接用默认的weight decay了。说到这里,根据我的实验,weight decay对剪枝后的模型,尤其是sparsity较高的模型影响挺大的,但似乎并没有发现有剪枝的文章专门讨论过这个问题。
如果是在CPU上部署,或者是一些Intel的处理器/加速器支持的低功耗硬件上,剪枝后模型可以无差别地在OpenVINO中获得进一步加速,简化版VGG-11在Xeon 8160上的测试结果如下:

比起原始的模型直接在CPU上运行的结果,有~10X的提速。相关测试脚本和例子也都包含在了文章末尾的Github Repo里,事实上只要支持ONNX的加速部署框架,应该都能支持netslim剪枝之后的模型。
目前测了基于finetune的one-shot pruning,如果有时间可能会补充上iterative pruning的结果。欢迎试用~只进行了比较简单的几个测试,估计还有很多bug,请留言或提issue :)
yeyun11/pytorch-network-slimmin
链接:
https://github.com/yeyun11/pytorch-network-slimming
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割、姿态估计、超分辨率、嵌入式视觉、OCR 等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~





