R-Drop:填补Dropout缺陷,简单又有效的正则方法

深度神经网络(DNN)近来已经在各个领域都取得了令人瞩目的成功。在训练这些大规模的 DNN 模型时,正则化(regularization)技术,如 L2 Normalization、Batch Normalization、Dropout 等是不可缺少的模块,以防止模型过拟合(over-fitting),同时提升模型的泛化(generalization)能力。在这其中,Dropout 技术由于只需要简单地在训练过程中丢弃一部分的神经元,而成为了被最广为使用的正则化技术。
近日,微软亚洲研究院与苏州大学在 Dropout [1] 的基础上提出了进一步的正则方法:Regularized Dropout,简称R-Drop。与传统作用于神经元(Dropout)或者模型参数(DropConnect [2])上的约束方法不同,R-Drop 作用于模型的输出层,弥补了 Dropout 在训练和测试时的不一致性。简单来说就是在每个 mini-batch 中,每个数据样本过两次带有 Dropout 的同一个模型,R-Drop 再使用 KL-divergence 约束两次的输出一致。所以,R-Drop 约束了由于 Dropout 带来的两个随机子模型的输出一致性。
与传统的训练方法相比,R- Drop 只是简单增加了一个 KL-divergence 损失函数项,并没有其他任何改动。虽然该方法看起来很简单,但实验表明,在5个常用的包含 NLP 和 CV 的任务中(一共18个数据集),R-Drop 都取得了非常不错的结果提升,并且在机器翻译、文本摘要等任务上取得了当前最优的结果。

论文链接:https://arxiv.org/abs/2106.14448
GitHub 链接:https://github.com/dropreg/R-Drop

由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。
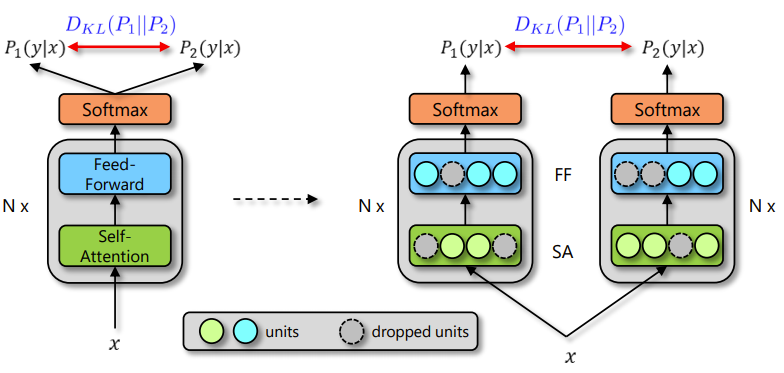
图1:R-Drop 框架,在训练时由 Dropout 带来的两次概率 P_1 和 P_2 的不同
具体来说,当给定训练数据 D={x_i,y_i }_(i=1)^n 后,对于每个训练样本 x_i,会经过两次网络的前向传播,从而得到两次输出预测:P_1 (y_i│x_i ), P_2 (y_i |x_i)。由于 Dropout 每次会随机丢弃部分神经元,因此 P_1 和 P_2 是经过两个不同的子网络(来源于同一个模型)得到的不同的两个预测概率(如图1所示)。R-Drop 利用这两个预测概率的不同,采用了对称的 Kullback-Leibler (KL) divergence 来对 P_1 和 P_2 进行约束:
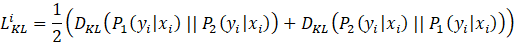
再加上传统的最大似然损失函数:
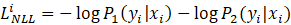
最终的训练损失函数即为:
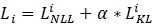
其中 α 是用来控制 L_KL^i 的系数,因此整个模型的训练非常简单。在实际实现中,数据 x_i 不需要过两次模型,而只需要把 x_i 在同一个 batch 中复制一份即可。直观地说,在训练时,Dropout 希望每一个子模型的输出都接近真实的分布,然而在测试时,Dropout 关闭使得模型仅在参数空间上进行了平均,因此训练和测试存在不一致性。而 R-Drop 则在训练过程中通过刻意对于子模型之间的输出进行约束,来约束参数空间,让不同的输出都能一致,从而降低了训练和测试的不一致性。另外,研究员们还从理论的角度出发,阐述了 R-Drop 的约束项对于模型自由度的控制,从而更好地提升模型的泛化性能。
为了验证 R-Drop 的作用,研究员们在5个不同的 NLP 以及 CV 的任务:机器翻译、文本摘要、语言模型、语言理解、图像分类,总计包含18个数据集上,进行了实验验证。
1. 在机器翻译任务上,基于最基础的Transformer [3]模型,R-Drop 的训练在 WMT14英语->德语以及英语->法语的任务上取得了最优的 BLEU 分数(30.91/43.95),超过了其他各类复杂、结合预训练模型、或更大规模模型的结果:
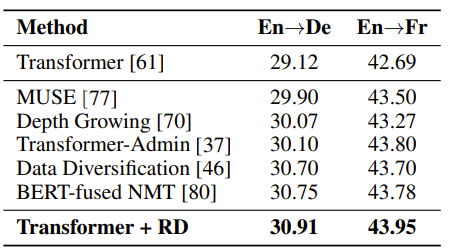
表1:R-Drop 在 WMT14 英语->德语与英语->法语机器翻译上的结果
2. 在图像分类任务上,基于预训练好的 Vision Transformer(ViT)[4] 为骨架网络,R-Drop 在 CIFAR-100 数据集以及 ImageNet 数据集上微调之后,ViT-B/16 和 ViT-L/16 的模型均取得了明显的效果提升:
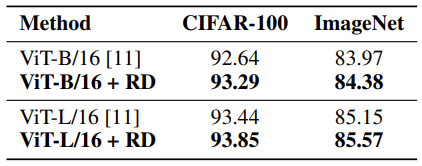
表2:R-Drop 基于 Vision Transformer 在 CIFAR-100、ImageNet 微调后图像分类的结果
3. 在NLU 语言理解任务上,R-Drop 在预训练 BERT-base [5] 以及 RoBERTa-large [6] 的骨架网络上进行微调之后,在 GLEU 基础数据集上轻松取得了超过1.2和0.8个点的平均分数提升:
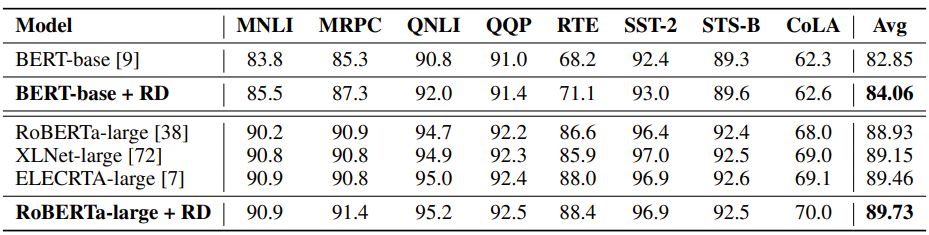
表3:R-Drop 在 GLUE 语言理解的验证集上的微调结果
4. 在文本摘要任务上,R-Drop 基于 BART [7] 的预训练模型,在 CNN/Daily Mail 数据上微调之后也取得了当前最优的结果:
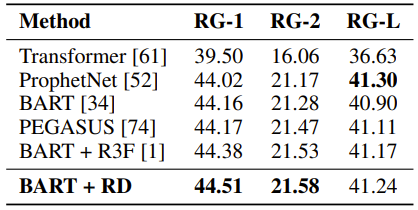
表4:R-Drop 基于 BART 模型在 CNN/Daily Mail 文本摘要上微调的结果
5. 在语言模型任务上,基于原始 Transformer 以及 Adaptive Transformer [8],R-Drop 的训练在 Wikitext-103 数据集上取得了1.79和0.80的 ppl 提升:
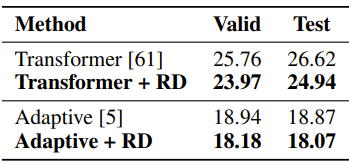
表5:R-Drop 在 Wikitext-103 数据上的语言模型结果
可以看到,R-Drop 虽然很简单,但效果非常出众,取得了很多任务上的最优结果,并且在文本、图像等不同的领域都能通用。除此之外,研究员们还进行了各类的分析实验,包括训练复杂度,k 步的 R-Drop、m 次的 R-Drop 等等,更进一步对 R-Drop 进行了全面的剖析。
R-Drop 的提出基于 Dropout 的随机性,简单有效。在该工作中,目前只对于有监督的任务进行了研究,未来在无监督、半监督学习中,以及更多不同数据类型的任务中,也值得更为深入地探索。欢迎大家使用 R-Drop 训练技术在各类实际的场景中进行应用。期待 R-Drop 的思想能启发更多好的工作。
相关分享:
又是Dropout两次!这次它做到了有监督任务的SOTA
https://kexue.fm/archives/8496
参考文献:
[1] Srivastava, Nitish, et al. "Dropout: a simple way to prevent neural networks from overfitting." The journal of machine learning research 15.1 (2014): 1929-1958.
[2] Wan, Li, et al. "Regularization of neural networks using dropconnect." International conference on machine learning. PMLR, 2013.
[3] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[4] Dosovitskiy, Alexey, et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale." International Conference on Learning Representations. 2020.
[5] Kenton, Jacob Devlin Ming-Wei Chang, and Lee Kristina Toutanova. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." Proceedings of NAACL-HLT. 2019.
[6] Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
[7] Lewis, Mike, et al. "BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
[8] Baevski, Alexei, and Michael Auli. "Adaptive Input Representations for Neural Language Modeling." International Conference on Learning Representations. 2018.
你也许还想看:









