神经网络加上注意力机制,为什么精度反而下降?

极市导读
问题来自于知乎:"神经网络加上注意力机制,精度反而下降,为什么会这样呢?" 作者对该问题从两个角度对其进行了解释。>>加入极市CV技术交流群,走在计算机视觉的最前沿
因为之前写过Attention+YOLOv3的文章,做过相关实验,所以被问过很多问题,举几个典型的问题:
-
我应该在哪里添加注意力模块? -
我应该使用那种注意力模块? -
为什么我添加了注意力模块以后精度反而下降了? -
你添加注意力模块以后有提升吗? -
注意力模块的参数如何设置? -
添加注意力模块以后如何使用预训练模型?
周末的时候看到了这个问题,也看到了各位的解答,感觉也非常有道理,萌生出用实验来证明的想法,于是花了一点时间测试了题目中提到的CBAM模块。一个模型精度是否提高会受到非常多因素影响,需要考虑的因素包括模型的参数量、训练策略、用到的超参数、网络架构设计、硬件以及软件使用(甚至pytorch版本都会有影响,之前在某个版本卡了半天,换了版本问题就解决了)等等。注意力机制到底work不work,我觉得可以从两个角度来解释。
第一个角度是模型的欠拟合与过拟合
大部分注意力模块是有参数的,添加注意力模块会导致模型的复杂度增加。
-
如果添加attention前模型处于欠拟合状态,那么增加参数是有利于模型学习的,性能会提高。 -
如果添加attention前模型处于过拟合状态,那么增加参数可能加剧过拟合问题,性能可能保持不变或者下降。
为了验证以上猜想,使用cifar10数据集中10%的数据进行验证,模型方面选择的是wideresnet,该模型可以通过调整模型的宽度来灵活调整模型的容量。
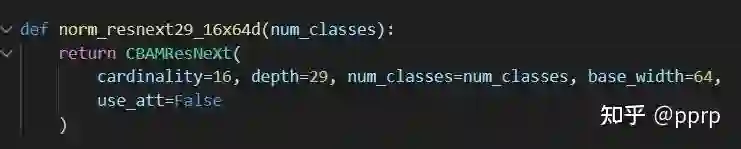
构建了模型族:
| Norm系列表示没有使用注意力,nd代表宽度 | CBAM系列表示在ResBlock中使用了注意力 |
|---|---|
| norm_8d | cbam_8d |
| norm_32d | cbam_32d |
| norm_64d | cbam_64d |
具体来说,从上到下模型容量越来越高,下图展示了各个模型在训练集和验证集上的收敛结果。
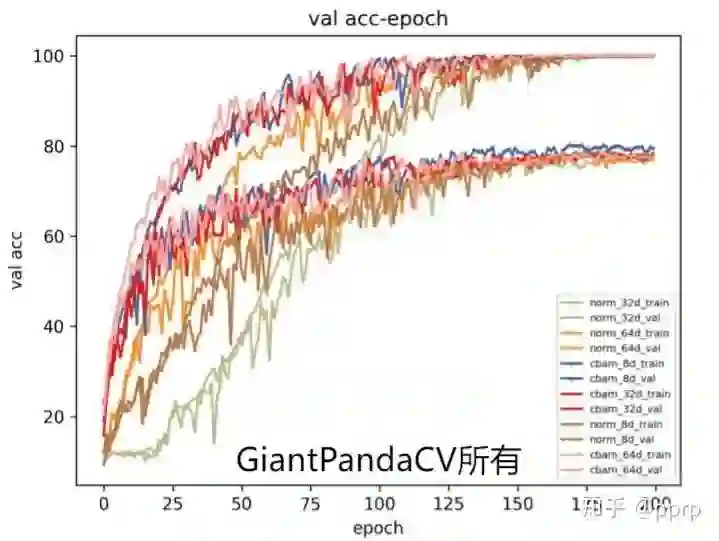
可以发现一下几个现象:
-
随着宽度增加,模型过拟合现象会加剧,具体来说是验证集准确率变低。 -
cbam与norm进行比较可以发现,在8d(可能还处于欠拟合)基础上使用cbam可以取得验证集目前最高的结果,而在64d(可能出现过拟合)基础上使用cbam后准确率几乎持平。 -
还有一个有趣的现象,就是收敛速度方面,大体符合越宽的模型,收敛速度越快的趋势(和我们已知结论是相符的,宽的模型loss landscape更加平滑,更容易收敛)
以上是第一个角度,另外一个角度可能没那么准确,仅提供一种直觉。
第二个角度是从模型感受野来分析
我们知道CNN是一个局部性很强的模型,通常使用的是3x3卷积进行扫描整张图片,一层层抽取信息。而感受野叠加也是通过多层叠加的方式构建,比如两个3x3卷积的理论感受野就是5x5, 但是其实际感受野并没有那么大。
各种注意力模块的作用是什么呢?他们能够弥补cnn局部性过强,全局性不足的问题,从而获取全局的上下文信息,为什么上下文信息重要呢?可以看一张图来自CoConv。

单纯看图a可能完全不知道该目标是什么,但是有了图b的时候,知道这是厨房以后,就可以识别出该目标是厨房用手套。因此注意力模块具有让模型看的更广的能力,近期vision transformer的出现和注意力也有一定关联,比如Non Local Block模块就与ViT中的self-attention非常类似。vision transformer在小数据集上性能不好的也可以从这个角度解释,因为太关注于全局性(并且参数量比较大),非常容易过拟合,其记忆数据集的能力也非常强,所以只有大规模数据集预训练下才能取得更好的成绩。(感谢李沐老师出的系列视频!)再回到这个问题,注意力模块对感受野的影响,直观上来讲是会增加模型的感受野大小。理论上最好的情况应该是模型的实际感受野(不是理论感受野)和目标的尺寸大小相符。
-
如果添加注意力模块之前,模型的感受野已经足够拟合数据集中目标,那么如果再添加注意力模块有些画蛇添足。但是由于实际感受野是会变化的,所以可能即便加了注意力模块也可以自调节实际感受野在目标大小附近,这样模型可能保持性能不变。 -
如果添加注意力模块之前,模型的感受野是不足的,甚至理论感受野都达不到目标的大小(实际感受野大小<理论感受野大小),那么这个时候添加注意力模块就可以起到非常好的作用,性能可能会有一定幅度提升。
从这个角度来分析,题主只用了两个卷积层,然后就开始使用CBAM模块,很有可能是感受野不足的情况。但是为什么性能会下降呢,可能有其他方面因素影响,可以考虑先构建一个差不多的baseline,比如带残差的ResNet20,或者更小的网络,然后再在其基础上进行添加注意力模块。以上结论并不严谨,欢迎评论探讨。
笔者开源了注意力模块库,欢迎提issue贡献!https://github.com/pprp/awesome-attention-mechanism-in-cv对文中实验源码感兴趣可以访问这个链接:https://github.com/pprp/pytorch-cifar-model-zoo
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





