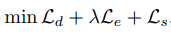人工智能模型的安全问题一直令人担忧,通过设计好的汽车涂装或许就能令模型失效。
人工智能技术日新月异,极大地推动了计算机视觉、自然语言处理等领域的进步。近年来,视觉应用安全成为大家关心的热门,特别是,在公共安全、自动驾驶等领域中,亟待回答这一问题。
![]()
例如,一辆特殊涂装的车辆可能骗过智能监控摄像头混入特定区域,或者导致车祸,这听起来不可思议,但是却可能成为事实。
![]()
上图是一种生成的应用于车辆的对抗伪装,它们看起来像一个涂装上的笑脸装饰,看起来没什么问题,但却会引起深度神经网络模型分类或者识别错误。如果这种车辆出现在自动驾驶的路段中,那么毫无疑问会导致交通危险事件。此外,这种纹理还可能被不法分子用于恐怖袭击等,这需要我们关注和警惕。
来自北京航空航天大学的刘祥龙教授团队的一篇论文为我们展示了对抗伪装在自动驾驶领域的危险性。该论文提出了一种双重注意力抑制攻击算法,通过分散模型注意力,可以生成物理世界中攻击性较强的对抗伪装,能够在黑盒设置下,对数字世界和物理世界的多种模型产生攻击效果(例如 Inception、VGG、ResNet、DenseNet 等分类模型和 Yolo-V5、SSD、Faster-RCNN、Mask-RCNN 等检测模型),在具备强大攻击力的同时,该算法能够规避人类的视觉注意力机制,在视觉上更加自然,具有一定的伪装效果。该论文已被全球计算机视觉顶级会议 CVPR-2021(Oral)接收。
![]()
该论文提出的双重注意力抑制攻击框架,能够在 3D 仿真环境中生成具有欺骗效应的可迁移对抗伪装,在黑盒设置下,有较好的攻击效果。通过在数字世界和物理世界进行测试和验证,证明了较好的攻击性,同时经过人类实验验证了在视觉欺骗方面的效果。其主要框架如下图所示,一方面,通过引入注意力模块获得模型内在注意力模式,并利用损失函数分散不同模型之间共享的注意力模式来进行对抗攻击。另一方面,为了提升视觉自然程度,本文提出通过保留边缘信息提升上下文的语义相关程度,从而规避了人类视觉自下而上的注意力特征,使得生成的对抗纹理具有欺骗人类的能力。
![]()
生物学研究指出,刺激特征 (即选择性注意) 在不同的个体中会产生相似的大脑活动模式,卷积神经网络是以生物神经网络为蓝本的。该研究认为 DNNs 或许也拥有同样的特征,即在做出决策时,不同的深度模型可能对同一类对象有相似的注意力模式。基于此,该研究希望通过捕捉这种模型共有的注意力结构来提高对抗伪装的可迁移性,以增强融合样本的泛化攻击能力。
为了实现这一目的,受视觉注意力技术(如 CAM、Grad-Cam、和 Grad-CAM++ 等)的启发,该论文通过引入此类注意力模型来获取模型共享的相似注意图并将其从显著区域强制转移到其他区域,也就是“分散模型的注意力”。因此,模型可能无法聚焦于目标对象,从而做出错误的预测。
给定一个 3D 真实对象(M,T),待优化对抗纹理张量 Tadv,和指定的标签 y,则一个对抗样本 I_adv 可以表示为:
![]()
其中,R 是一个渲染器,c 代表环境参数。与之对应的注意力图 S^y 为:
![]()
![]()
在得到注意力图后,研究者希望通过损失函数约束伪装纹理变化,使得注意力图中的显著区域能够趋于分散。直观上,注意力图的像素值代表该位置像素对模型预测值的贡献,为了减少显著区域的注意力权重和分散模型对该区域的关注,研究者利用联通图思想来设计损失函数。在某一张注意力图中,该研究将注意力权重大于阈值的区域看作是连通区域。因此该研究考虑了以下问题:(1)将联通区域分割为子联通区域,减少注意力区域的完整性;(2)减少每个子联通区域中的节点(像素点)的注意力权重,进而该研究提出的注意力分散损失如下:
![]()
为了克服复杂环境带来的影响,大部分物理攻击方法生成的对抗扰动量级较大,往往形成明显不自然的畸变。由于人类自底向上的视觉注意力机制往往会使得个体更容易关注到此类可疑的畸变,不利于物理世界对抗样本的隐藏和欺骗。因此该论文提出了视觉注意力规避以使得生成的对抗纹理更加自然,具有更好的伪装性。
直觉上,研究者期望生成的对抗伪装与被攻击的上下文具有相近的视觉语义(例如,汽车上美丽的涂装比无意义的畸变更容易被人类感知接受)。已有研究表明,人类在做出判断时会更注意形状信息,因此,我们通过更好地保留种子内容补丁的形状来进一步提高与人类注意力的相关性。给定种子内容补丁 P0,通过边缘提取器Ф将种子内容补丁 P0 转换为轮廓补丁 Pedge,其中 Pedge=Ф(P0),然后获取对应的种子纹理张量 T0 和掩码张量 E,人类注意力规避损失为:
![]()
为了进一步提高对抗伪装的自然程度,论文还引入了平滑损失来约束相邻像素之间的变化差值,对于一个渲染好的对抗样本 I_adv,其平滑损失为:
![]()
![]()
![]()
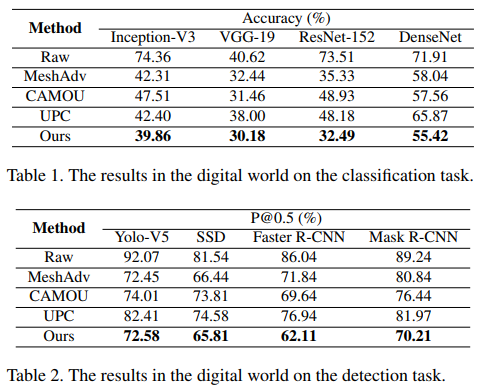
该论文在 CARLA 仿真环境下采样了 155 个位置,并采用不同参数在每个位置生成了 100 张图片,其中 12500 张作为训练集,3000 张作为测试集。考虑到物理场景中,攻击者对目标模型的了解是非常有限的,因此所有的实验是在黑盒条件下进行的。具体地,在分类任务和检测任务上的实验结果如下表所示:
![]()
可以看到,该研究提出的方法在分类任务和检测任务上都表现出较强的攻击能力。
在物理攻击实验中,由于实验条件的限制,研究者购买了一些玩具汽车,并通过分别打印对抗纹理的并贴片的方式实现物理攻击。在实验中,研究者从多个角度和距离拍摄了 144 张图片,并用四种模型进行了实验,其结果如下表所示:
![]()
由上表可知,该研究提出的双重注意力抑制攻击(DAS)显示出了良好的可迁移性和攻击能力,明显优于比较基线。不过,值得注意的是,Yolo-V5 在物理攻击实验中展现出了惊人的鲁棒性和识别能力,但该研究的方法依然对其识别造成了比对比方法更大的影响。
除了进行攻击能力验证之外,该研究还进行了模型注意力的分析以验证其假设。从下图的分析可以看到,虽然不同模型的结构不同,但是其注意力图具有比较高的相似性,对注意力图进行的 SSIM 分析支撑了该研究的观点。
![]()
而在对同一模型的不同类别进行注意力分析时,模型的关注点也有所变化。
![]()
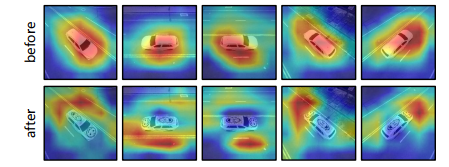
此外,该研究对经过攻击前后的样本同样进行了注意力图分析,也体现了所提方法的合理性(分散模型注意力)。
![]()
为了验证该研究所提方法生成的对抗纹理的自然程度,该研究进行了人类实验。通过众包平台,该研究的方法在两个任务上都取得了更好的分数。
![]()
人工智能技术的进步给社会发展带来了巨大的便利,但随着近年来对抗样本的研究,人们越来越意识到人工智能安全的重大意义。当前的种种工作都证明了目前的人工智能应用可能并没有我们想象的可靠,人工智能安全相关的研究和标准亟待进一步推进和落实。本篇论文提出的双重注意力抑制攻击方法,从攻击者的角度向人工智能应用提出了尖锐的质疑,如何在发展人工智能技术的同时保证其安全可靠可控是我们正面对的极大挑战和高危风险,避免人工智能应用产生危害也需要政策制定者的重视和关切。我们相信,未来是人工智能的时代,但如何更快、更稳、更好的走进它,需要我们一起给出答案。
最佳技术实践:CV+联邦学习怎么搞?
FedVision是首个轻量级、模型可复用、架构可扩展的视觉横向联邦开源框架,基于Python 实现,内置PaddleFL/PaddleDetection插件,支持多种常用的视觉检测模型, 助力视觉联邦场景快速落地。
3月11日,微众银行联合飞桨带来实战公开课,聊聊FedVision实战与技术展望。
识别海报二维码,加入直播群。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com