GBDT是如何成为推荐系统顶级工具人的?

文 | 水哥
源 | 知乎
Saying
1. 集成学习的ensemble注意一定要读作昂三姆包而不是印三姆包,一天一个算法工程师装x小技巧
2. 区别bagging和boosting的准则是,先训练的模型对于后训练的模型是否有影响
3. GBDT中,B(boosting)组成头部,这是该方法的核心,G(Gradient)组成躯干,决定大方向上的选型,DT(Decision Tree)组成腿部,想换就可以换掉
4. Facebook把GBDT用在推荐里的重点是为了自动地找出特征的归类方式,并没有说明树模型在推荐中优于LR,但是说明树模型是顶级工具人
这是 从零单排推荐系统 系列的第14讲,这一讲和下一讲我们合起来把树模型在推荐中的使用讲清楚。在推荐领域里,树模型属于是来得快,去得也快。Facebook最开始发表Practical Lessons from Predicting Clicks on Ads at Facebook[1]的时候,大家都觉得很新奇很有意思,但是这个时间点DNN已经开始攻城略地了。到了embedding+DNN称霸的现在,还没有什么特别好的方案能把树模型和DNN结合在一起。时至今日,GBDT还可以作为一个很好的分桶工具,而它的升级版XGBoost和LightGBM则是以另一个形式活在推荐系统中。
如果是一个没有背景知识的同学,面对GBDT这四个字母可能有点懵,我们首先来拆解一下这四个字母都代表什么:
DT:Decision Tree
就是决策树,具体来说,Facebook的论文里面使用CART作为决策树。决策树的内容比较基础这里就不赘述了。但是它完成了两件事:(1)非线性的分类,(2)分桶。分桶的这个性质非常重要,属于是无心插柳式的点了。
B:Boosting
Boosting和树模型总是一起出现的,本质原因是树模型往往比较弱,而当我们不满足一个模型的能力,想要用多个模型来融合达到最佳结果,这种方法就是集成学习,即ensemble learning。而ensemble learning又可以分为两种:bagging和boosting,如下图所示:
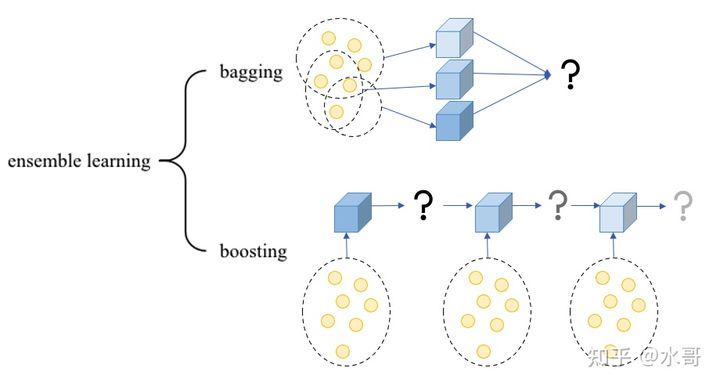
黄色的圆表示数据点,蓝色立方体是模型,而问号则是目标。问号的深浅表示这步需要拟合的难度。
-
bagging:使用多个模型来共同完成目标。目标不会拆解,在训练时,每一个模型的任务都是拟合目标,在部署时,可以简单把决策加起来或者投票。数据上,有时候为了让模型的侧重点不同,每个模型用的特征或数据不一样。前面讲过的MoE可以算是bagging,而random forest就算是典型的bagging了。 -
boosting:使用多个模型来拟合目标,目标是循序渐进的,即后面的模型学习前面模型没学到的部分。数据上可以做区分。这一族的算法比较著名的是AdaBoost,还有这一讲要讲的Gradient Boosting Machine(GBM)。
如果对于第 个样本,模型的输出和真实label分别是 和 ,我们把损失函数表示为 。最终的决策可以表示为:
一共有 个模型,模型用 来表示。从部署上来看,boosting和bagging没有区别,都是一堆弱分类器决策加起来形成更强的结果。但是对于boosting,前面出错的样本在后面会增大权重,即前后是互相影响的,而bagging的各个模型几乎是独立的。
GB:Gradient Boosting (Machine)
对于Gradient Boosting来说,每一步中,都新训练一个模型,而这个模型学习的是之前所有结果综合后,仍然距离目标的误差:
其中之前模型的结果合起来就是 ,所以其实等价于让 学习 和 之间相差的部分,也可称之为残差。公式最后的 表示正则部分。
简单起见(也符合这部分技术发展的历史)我们用MSE loss来代入 ,那么忽略掉正则项之后,loss就变成了 ,前面括号里的计算结果就是残差了,可见这个loss实际上就是希望 。另一方面,如果对 求导,则有:
所以这么看下来就要求 ,我们似乎可以得到结论:后面加的每一个函数,就是拟合在前一步的时候的负梯度。 但是要注意的是,上面的推导其实是省略了正则项的,如果加上正则项,希望的 的结果一定会变,不会再次严格等于负梯度。
那为什么后续的方法还是按照负梯度来呢?
GBM中Gradient的含义
这个问题在知乎上也有一些争论:gbdt的残差为什么用负梯度代替?(https://www.zhihu.com/question/63560633)
有一部分人认为负梯度是下降方向,所以一定是对的,另一部分人认为和泰勒展开有关系
其实《Gradient boosting machines, a tutorial》[2]这篇文章就明确说了:In practice, given some specific loss function and/or a custom base-learner , the solution to the parameter estimates can be difficult to obtain. To deal with this, it was proposed to choose a new function to be the most parallel to the negative gradient along the observed data.
所以说白了就一句话,也没想那么多,就是负梯度简单好用,而且也不差。
其实在XGBoost[3]这篇文章其实还给出了一个理由:每次计算新的结果的时候,上一步的结果和梯度是可以提前算好的,那岂不是不用白不用?
GBDT:组装积木
所以知道了DT,B,GB分别是什么之后,GBDT就好理解了:就是在GBM中吧模型换成决策树就好了。
但是这一讲得重点是我们要理解,为什么Facebook使用了GBDT?
要理解这一点,我们要从特征的处理来讲起。在一个推荐模型中,特征最方便的用法是给一个ID,或者用One-hot来表示,这样可以很容易和前面讲的逻辑回归(LR)结合使用。但是对于连续值特征(比如这个用户已经累计登陆了多少天),值是不可以穷举的,要把它们加入到模型中去,比较常见的做法是分桶(bucketize)。例如对与用户累计登录的天数,划分0-1天是一档,1-7是一档,7-30,30-180,180-365,365+各有一档。这样这个特征就一定可以表示为这六者之一。但是问题是这个桶的边如何才能切的很好呢?可能有同学说,我可以做个统计,选择最有信息量的切法。但是这个分布其实是动态变化的,又保证能够跟得上呢?
不只是连续特征有问题,离散的特征也有问题。比如item ID,可能有很多商品长得都没啥差距,仅仅是代理商换了一下,ID就不一样。这些ID可能出现的次数还很稀疏,如果给这些ID都分配空间也是比较占空间且低效的,我可不可以做一些压缩,一堆弟弟ID就放到一个ID的桶里面好了呢?
理解了上面的两个问题,就可以理解GBDT用在这里的动机:对于item ID这个特征,就单独对它用决策树训练一下点击率,在决策树分裂的过程中自动地就会决定一些ID是不是在同一个叶子节点中,做到某个深度之后就停止,然后这个叶子节点的序号就成为新的ID。也就是说,在这里使用GBDT,其实只是当做一个更高级一点的分桶的工具。
补充一下原论文的图来举一个例子:
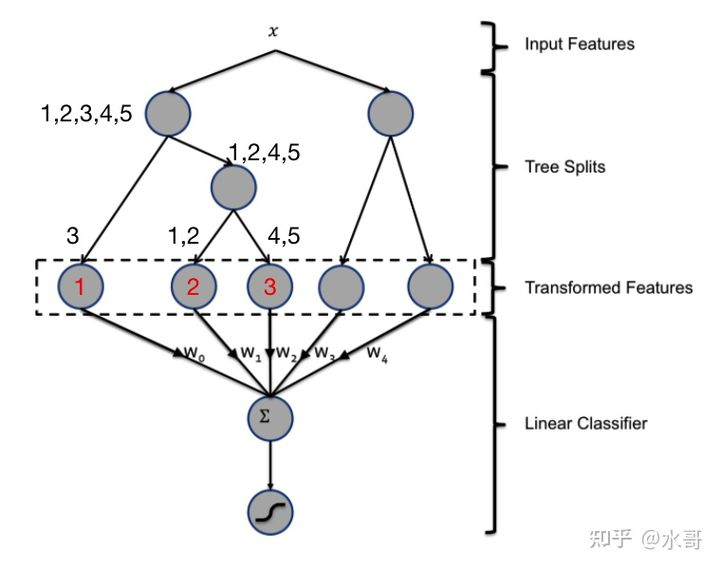
item ID现在有5个,第一棵树用来转换这个特征,在做决策的过程中,3号落入第一个叶子节点,1,2落入第二个叶子节点,4,5在第三个里面。那么输入3之后,压缩后的item ID现在是1了,同理,1,2现在都是2,4,5变为3.
接下来每一棵树处理一种特征,以此类推,刚好就有了boosting的过程。在这个算法中,分为两个步骤,训练好的GBDT仅仅用来转换特征。转换完成的特征仍然使用LR来进行分类,GBDT只是一个变换/压缩特征的工具人罢了。文章中也给出了比较,直接使用GBDT来分类效果并不会更好。
其实我们也不用在GBDT上面扣得太细,归纳一下就是GBDT是学过的决策树的升级版本,而更进一步的版本是XGBoost和LightGBM,如果我们在哪个环节需要一个树模型,直接调用它们就好了。
延迟转化初窥
Practical Lessons from Predicting Clicks on Ads at Facebook 还讨论了一个问题,所有样本一曝光的时候都只能默认是负样本,只有点击了发生,才能变成正样本。我们就有一个难点:一方面,我们是一个online learning的系统,为了能做更好的预估,我们希望样本马上反馈到训练环节上;但是另一方面,等待有可能的样本变成正样本是需要时间的,如果等的时间太短就发送,可能会把正样本误判成负样本。
这个问题在转化(CVR)预估的时候非常常见,比如游戏下载,下载完了才算转化,但是下载的时间可能会非常长,你不能等到几个小时之后才发送样本吧?这就是延迟转化的问题,具体我们留到难点篇来讲。
在本文中是简单的用一个时间窗来记录,在这个窗口之内转变的正样本才记录。所以这也是比较直接的一个做法。如果等待的窗口时间设的特别长,那么我们的online learning就会越来越向线下退化,极端情况下,可能第二天才能学习第一天完整的结果。但是根据我们的复读机理论,没有快速把能点击的ID记下来,一定会在性能表现上吃亏。反之,如果时间窗口设定的太小,在模型看来,有些本来应该是正样本的现在都是负样本了,负样本比例升高,模型输出的CTR,CVR就会变低,造成低估。
下期预告
推荐系统精排之锋(9):embedding亦福亦祸,XGBoost与LightGBM的新机遇
往期回顾
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Practical Lessons from Predicting Clicks on Ads at Facebook,ADKDD,2014
https://research.fb.com/wp-content/uploads/2016/11/practical-lessons-from-predicting-clicks-on-ads-at-facebook.pdf[2] Gradient boosting machines, a tutorial
https://www.frontiersin.org/articles/10.3389/fnbot.2013.00021/full[3] XGBoost: A Scalable Tree Boosting System,KDD,2016
https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
 后台回复关键词【
后台回复关键词【




