【精选】卡尔曼滤波及其在配对交易中的应用

——人工智能与量化交易公众号——
前沿
听过卡尔曼滤波的差不多有两年的时间了,虽然大致上明白其原理,但是也是直到现在才能够彻底掌握下来。主要是卡尔曼滤波算法涉及到比较复杂的数学公式推导。在很多博客上都有写卡尔曼滤波的相关文章,但都是花非常大的篇幅来通过一些例子来通俗地讲解卡尔曼滤波,对于不知道其数学原理的读者来说,看完之后依然是一知半解。
本文会先讲解最简单的单变量卡尔曼滤波,让大家知道卡尔曼滤波大致是什么样的,然后再详细地给出公式的推导过程,最后展示卡尔曼滤波在配对交易中的应用。
卡尔曼滤波
卡尔曼滤波(Kalman filtering)一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
最简单的单变量卡尔曼滤波,可以认为,我们观测的时间序列是存在噪声的,而我们可以通过卡尔曼滤波,过滤掉噪声,而得到了去除噪声之后的状态序列。
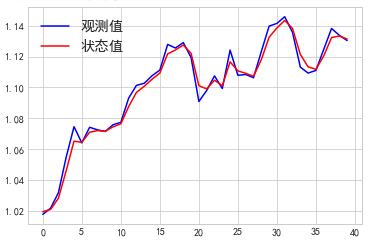














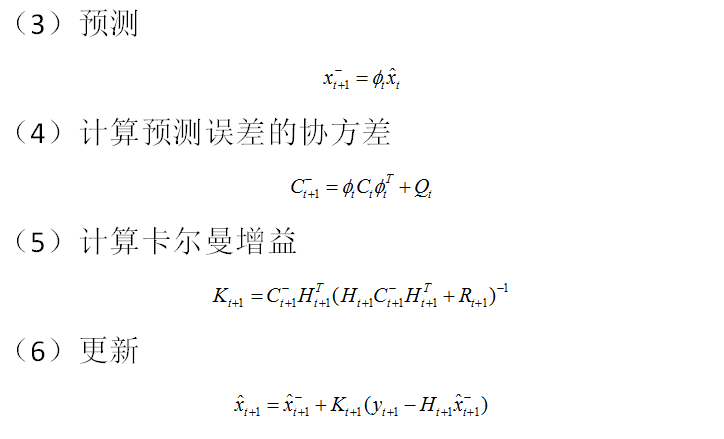
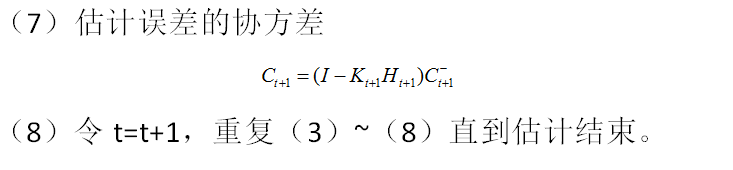
卡尔曼滤波在配对交易的应用
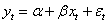
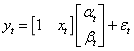
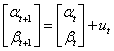

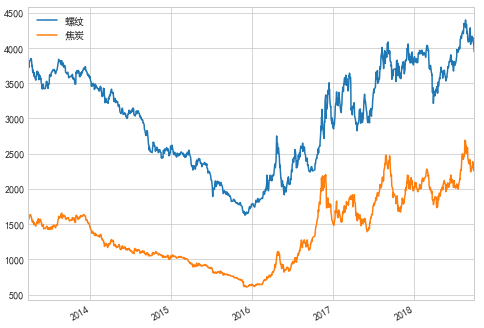
# 以焦炭的收盘价数据作为x,螺纹的收盘价数据作为y
# 螺纹价格 = alpha + beta * 焦炭价格 + 随机误差
from pykalman import KalmanFilter
#建立观测矩阵
observation_matrices = np.vstack(( np.ones(len(df[:'2013'])),
df.loc[:'2013','焦炭'].values )).T
Shape = observation_matrices.shape
observation_matrices = observation_matrices.reshape(Shape[0],1,Shape[1])
#定义卡尔曼滤波的方程
kf = KalmanFilter(transition_matrices=np.array([[1,0],[0,1]]), #转移矩阵为单位阵
observation_matrices=observation_matrices)
np.random.seed(0)
# 使用2013年以前的数据,采用EM算法,估计出初始状态,
# 初始状态的协方差,观测方程和状态方程误差的协方差
kf.em(df.loc[:'2013','螺纹'])
#对2013年的数据做滤波
filter_mean,filter_cov = kf.filter(df.loc[:'2013','螺纹'])#观测值为螺纹
#从2014年开始滚动
start_index = np.where(df.index.year==2014)[0][0]
for i in range(start_index,len(df)):
observation_matrix = np.array([[1,df['焦炭'].values[i]]])
observation = df['螺纹'].values[i]
#以上一个时刻的状态,状态的协方差以及当前的观测值,得到当前状态的估计
next_filter_mean,next_filter_cov = kf.filter_update(
filtered_state_mean = filter_mean[-1],
filtered_state_covariance = filter_cov[-1],
observation = observation,
observation_matrix = observation_matrix)
filter_mean = np.vstack((filter_mean,next_filter_mean))
filter_cov = np.vstack((filter_cov,next_filter_cov.reshape(1,2,2)))
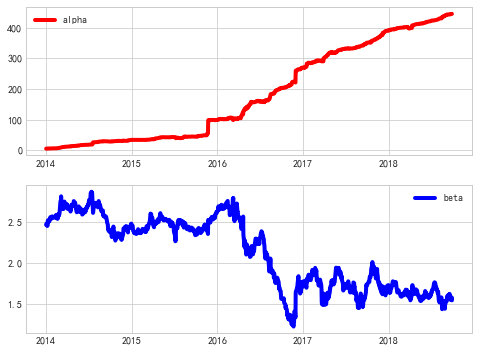
#得到alpha和beta
alpha = pd.Series(filter_mean[start_index:,0], index = df.index[start_index:])
beta = pd.Series(filter_mean[start_index:,1], index = df.index[start_index:])
本文来自:人工智能与量化交易
推荐阅读
知识在于分享
在量化投资的道路上
你不是一个人在战斗
登录查看更多
相关内容

专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
77+阅读 · 2020年2月8日
Arxiv
7+阅读 · 2019年2月8日
Arxiv
15+阅读 · 2018年5月24日
Arxiv
4+阅读 · 2018年5月24日


相关VIP内容
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
77+阅读 · 2020年2月8日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月8日
Arxiv
15+阅读 · 2018年5月24日
Arxiv
4+阅读 · 2018年5月24日