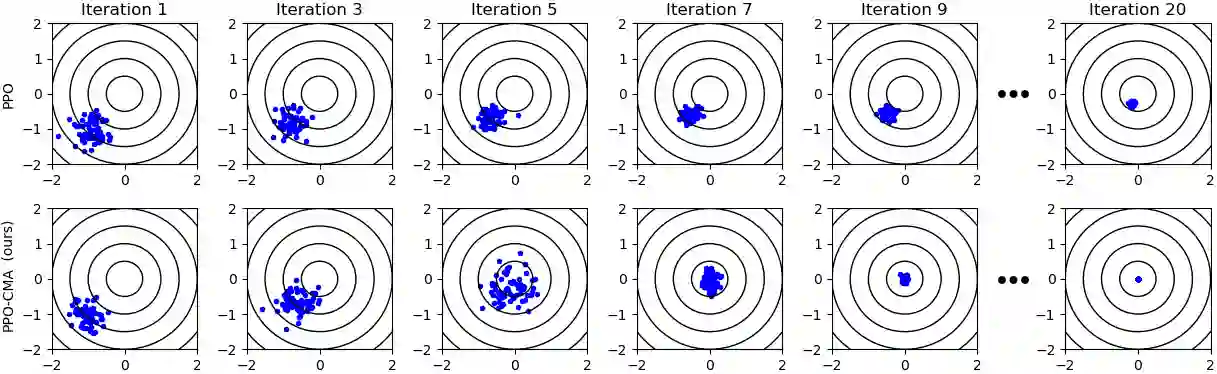
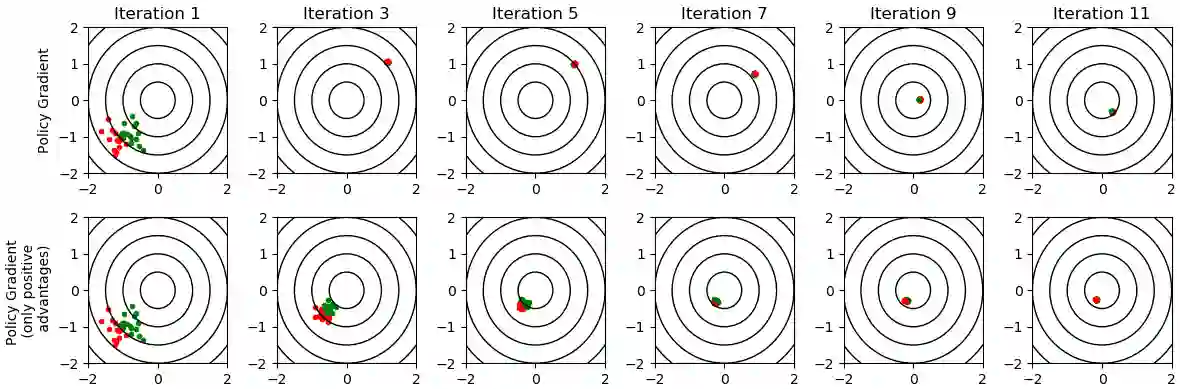
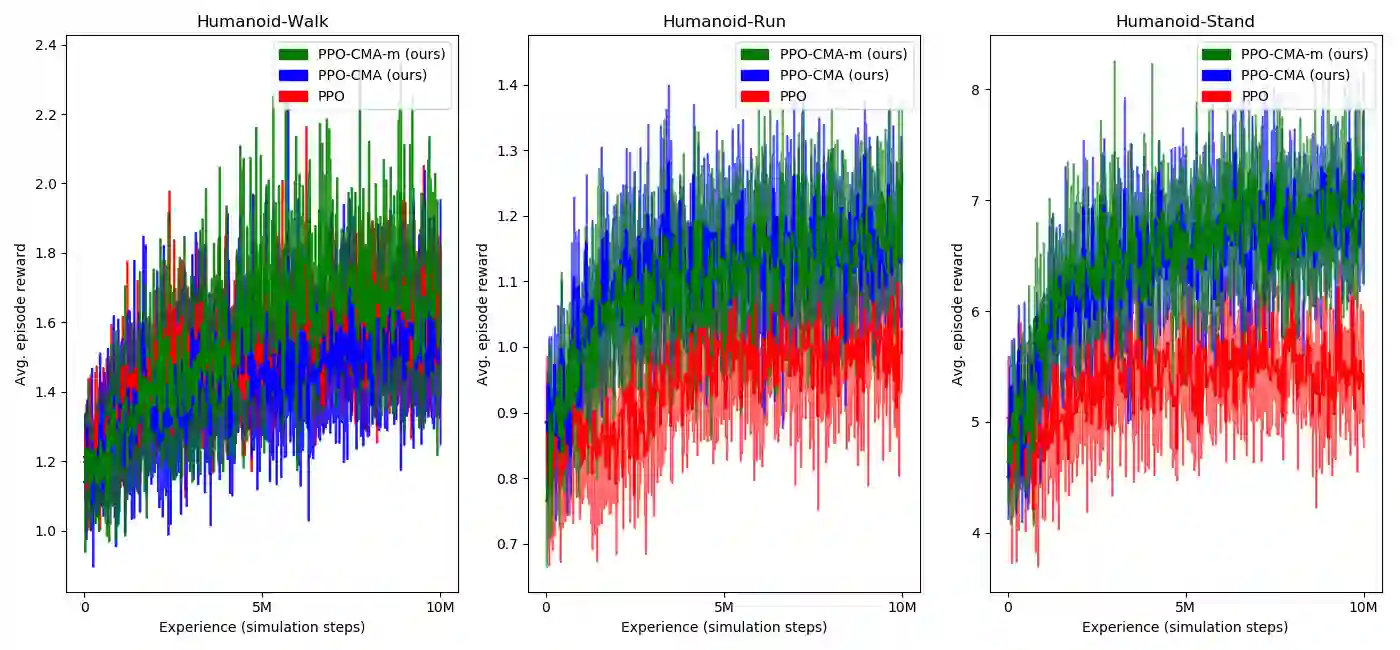
Proximal Policy Optimization (PPO) is a highly popular model-free reinforcement learning (RL) approach. However, in continuous state and actions spaces and a Gaussian policy -- common in computer animation and robotics -- PPO is prone to getting stuck in local optima. In this paper, we observe a tendency of PPO to prematurely shrink the exploration variance, which naturally leads to slow progress. Motivated by this, we borrow ideas from CMA-ES, a black-box optimization method designed for intelligent adaptive Gaussian exploration, to derive PPO-CMA, a novel proximal policy optimization approach that can expand the exploration variance on objective function slopes and shrink the variance when close to the optimum. This is implemented by using separate neural networks for policy mean and variance and training the mean and variance in separate passes. Our experiments demonstrate a clear improvement over vanilla PPO in many difficult OpenAI Gym MuJoCo tasks.
翻译:最佳政策优化(PPO)是一种高度流行的无模型强化学习(RL)方法。然而,在持续的状态和行动空间和高斯政策(计算机动画和机器人中常见的)中,PPO很容易被卡在本地的奥地马。在本文中,我们观察到PPO过早缩小勘探差异的倾向,这自然会缓慢进步。我们为此向CMA-ES(一种为智能适应性高斯探索设计的黑盒优化方法)借了想法,以产生PPPO-CMA(一种新颖的准政策优化方法),可以扩大目标功能坡度上的勘探差异,并在接近最佳时缩小差异。这是通过使用不同的神经网络来应用政策平均值和差异,并在不同的路段上培训平均值和差异。我们实验表明,在OpenAI Gym MuJoCo许多困难的任务中,Vanilla PPOBO有明显的改进。