自然语言处理领域的数据增广方法

作者:哈工大SCIR 李博涵
1.摘要
本文介绍自然语言处理领域的数据增广方法。数据增广(Data Augmentation,也有人将Data Augmentation翻译为“数据增强”,然而“数据增强”有将数据进行强化之意,而不仅是数量扩充。因此我们将其翻译为“数据增广”,单纯表示扩大数据规模。)是自动扩充训练数据的一种技术。如今深度学习取得了令人瞩目的成功,但是深度学习模型需要有大量的标注数据进行支撑。真实应用情景中,经常会出现缺乏标注数据、数据分布不均衡导致模型鲁棒性差、模型性能不佳的问题,而数据增广能在一定程度上解决这些问题。
为什么数据增广会为模型带来性能提升呢?在扩大数据的数量使模型能够充分训练的表象之下,主要包含以下几个原因:
1、数据增广引入了外部知识
-
人工的先验知识,如将图片翻转之后图片类别不变,句子中动词的缩写展开变为原型语义不变等。 -
领域外知识,如使用预训练的生成器生成新的样例时,引入了预训练模型中丰富的知识。
2、防止过拟合
-
通过向数据中加入随机噪声,提升模型鲁棒性。 -
通过扩大数据的数量,使其更加平滑。
2.方法综述
数据增广最早应用在CV领域,如对图片进行翻转、旋转、缩放、平移等。近年来,出现了更为复杂的CV数据增广方法,如图片风格迁移Luan et al.(2017)[1](如图1)。

相较于数据增广在CV领域的广泛应用,其在NLP领域的应用较少。这是因为与图片的连续性表示不同,自然语言的表示是离散的、符号化的。这导致如翻转等简单的数据增广操作在NLP中失效。同时,自然语言中顺序信息十分关键,比如“小博吃了苹果”与“苹果吃了小博”是完全不同的含义。因此NLP领域中,需要尝试更复杂、更有挑战性的方法进行数据增广。
NLP领域中短文本常见的数据增广方法包括两大类(如图2):
-
标签无关的通用增广方法不需要提供数据标签、任务需求等信息,只基于无标签的训练数据即可按照规则实现数据增广。 -
标签相关的特定增广方法则利用标签信息、按照任务需求进行增广,且需要考虑增广数据的标签相比于原数据标签是否变化的问题。
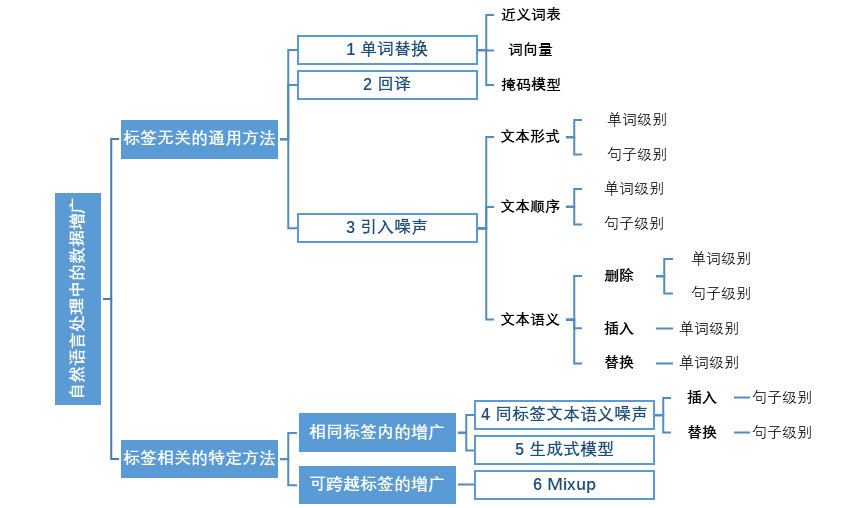
以下对各类数据增广方法进行介绍:
2.1单词替换
该方法通常利用近义词替换文本中的原始单词,从而在保持文本语义尽量不发生改变的前提下,得到新的表述方式。
2.1.1基于近义词表的替换
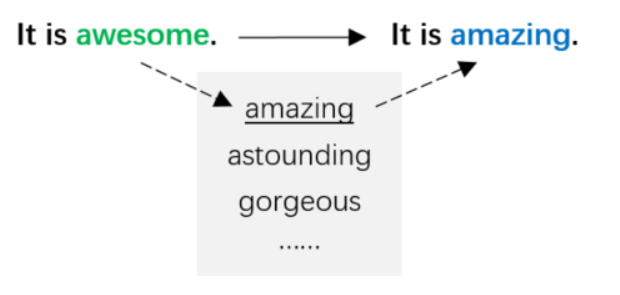
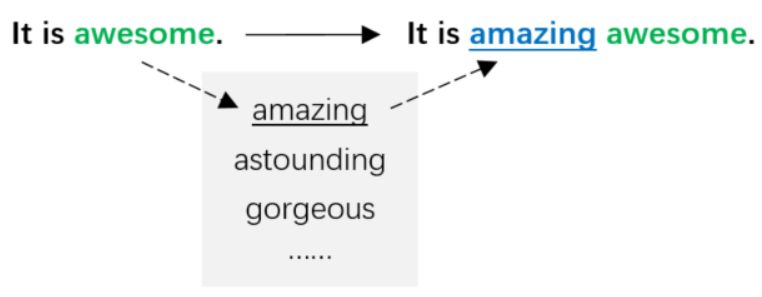
这种方法使用近义词表,将句子中的部分单词利用其近义词替代,使增广数据尽量贴合原始语义。Zhang et al.(2015)[2] 和Jonas et al.(2016)[3] 使用来源于WordNet[4]的英语词库mytheas来自动进行近义词替换,该词库将单词的近义词按照相似度进行排序。对于每个句子,检索出该句中拥有近义词的所有单词,按照几何分布P [r] ~ pr采样其中的r个,并分别用其第s个近义词替换,s也由几何分布决定:P [s] ~ ps 。这种方法保证了用更大的概率选中与原始单词更相似的近义词。Wei et al.(2019)[5]同样使用WordNet作为近义词表,从句子中随机选择N个非停用词,N的大小与句子长度成正比,在它们的近义词中分别随机选择一个替换对应的原始单词。以下图3为基于近义词表进行单词替换的例子。
-
近义词表的规模有限,因此句子中能够利用近义词表进行替换的单词范围同样有限。 -
近义词表包含的单词词性有限,如WordNet中只包括名词、动词、形容词、副词四类,其他词性的单词无法通过近义词表进行替换。 -
近义词表中存在一词多义的情况,但是替换时难以判断原始单词在句中对应哪个词义,因此随机选择的新单词词义有可能与原始词义不符,使得增广数据的句义发生改变。 -
该方法以单词为单位进行替换,不同单词的替换过程相互独立。因此当一个句子的替换次数过多时,有可能损害语义流畅度。
2.1.2基于词向量的替换
这种方法克服了基于近义词表的替换方法中对替换范围和单词词性的限制,采用预训练好的词向量,如Glove、Word2Vec、FastText等,用向量空间中距离原始单词最近的词将其代替。
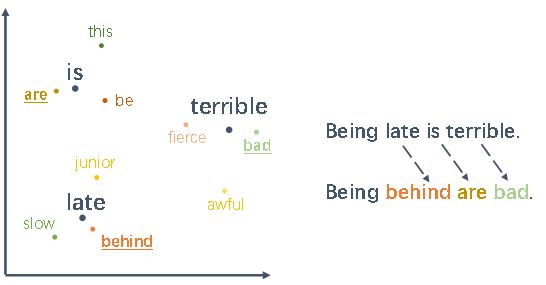
在推文的文本分类任务中,由于Twitter的消息通常简短且噪声较多,同时每个类别的训练数据都相对匮乏,因此Wang et al.(2015)[6]引入连续的词向量来增强文本的多分类任务,来保证增广数据的多样性。如图4,对原始单词用余弦相似度最高的K个单词(k nearest neighbors)代替,如“Being late is terrible”变为“Being behind are bad”。同时类别标签不变。
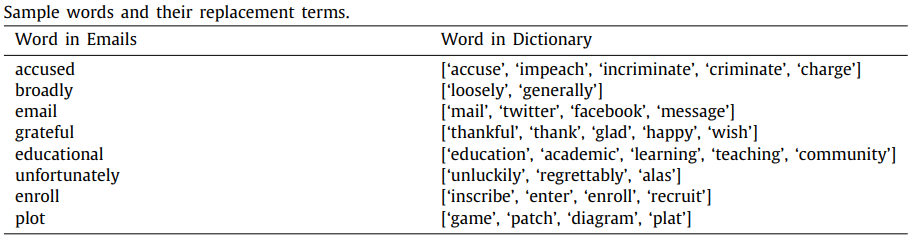
Liu et al.(2020)[7]在邮件分类任务中结合了基于近义词表和基于词向量的单词替换方法。首先基于词向量的相似度,为词表中的每个单词建立其最相关单词的字典。之后根据WordNet对这个字典进行修正或补充,如删除掉字典中不合理的缩略词,和添加字典中不存在的近义词。最后对句子中每个单词按照0.5的概率替换为它的近义词,同时每个近义词被选择的概率为0.2,以此得到该电子邮件的增广数据。图5为单词及其替换词字典的示例,图6为使用单词替换方法对邮件中数据进行增广的示例。
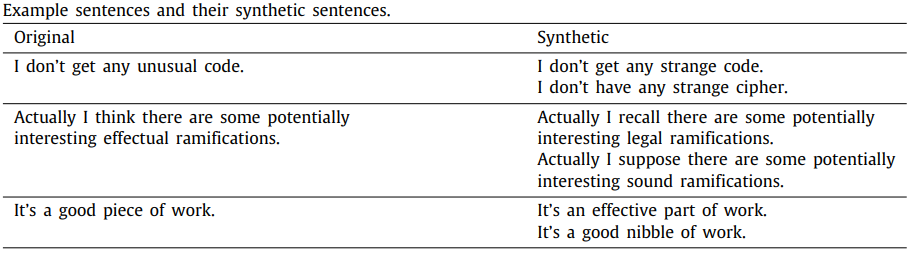
基于词向量的替换方法无需额外训练,且解决了近义词表只能应用于特定范围内单词的问题。但是,该方法同样面临一些问题:
-
Wrod2Vec等静态的词向量对于每个单词只有一种表示方式,无法解决一词多义的情况。 -
该替换方法同样以单词为单位,与基于近义词表的方法类似,当一个句子的替换次数过多时,仍有可能损害语义流畅度。
2.1.3基于掩码语言模型的替换
预训练语言模型凭借其出色的性能,成为近年来的主流模型。BERT、BoBERTa等掩码语言模型通过预训练的方式,获得了根据上下文预测文本中被mask的词语的能力,可用于文本的数据增广。具体来说,将文本中的部分单词用[MASK]替换,用训练好的掩码语言模型对该位置的单词进行预测,补全句子信息。
Jiao et al.(2019)[8]先对每一条原始数据使用BERT自带的分词器进行分词,得到若干word piece,为每一个word piece构建其替换词的候选集合,其中构建替换词集合的过程包括前文的基于词向量的方法,以及基于掩码模型的方法。具体来说,如果该word piece不是完整单词,则利用Glove检索与其相似度最高的K个单词组成候选集合;如果该word piece是完整单词,则用[MASK]将它代替并用BERT预测出K个单词组成候选集合;最后以0.4的概率决定每个word piece是否被候选集合中随机一个词替换。下图7为基于掩码模型进行单词替换的示例。

整体来说,单词替换是单词级别的增广方法,着重对单个单词的独立更改。这种方法的优点包括操作简单、适用性强,不需要通过模型学习和大规模训练数据就可进行增广。缺点包括这种方法通常基于近义词进行增广,得到的增广数据丰富度有限;增广语句的语义可能不流畅或相对原始数据发生变化。
2.2回译(Back translation)
这种方法是指原始文档通过翻译变为其他语言的文本,然后再被翻译回来得到原语言的新文本。与单词替换的方法类似,回译产生的增广数据与原始数据的语义尽量相同。不同的是,回译不直接基于同义词关系对单个单词逐一替换,而是通过生成的方式复述句子,达到了数据扩充的目的。
Xie et al.(2019)[9]使用WMT'14的英语-法语翻译模型(双向)对句子进行回译。Luque et al.(2019)[10]则在英语、法语、葡萄牙语和阿拉伯语之间进行翻译。Zhang et al.(2020)[11]在风格迁移任务中引入数据增广,将非正式的原始英语数据翻译成法语,再重新翻译成英语,得到原始数据的正式表达。图8为“英-中-英”的回译示例。

整体来说,回译方法产生的增广数据要尽量与原始数据语义相同,该方法具有以下优点:
操作简单,适用性强。
可直接调用现有的翻译模型,无需进行训练。
相比于单词替换的方法,回译直接用模型生成增广数据,保证了增广数据的语法正确、语义流畅,且不偏离原始句义。
相比于单词替换的方法,回译除了利用近义词进行增广以外,还可通过翻译模型引入其他信息,如句式变换、单词缩写、行文风格等,提升增广数据的多样性。
同时,该方法同样存在一定缺点:
受到翻译模型和输入语句的影响,少数条件下回译的结果与原始句子相同(相当于未进行增广)。
由于这种方法依赖固定的端到端翻译模型,导致其增广结果的可控性较差,无法根据任务需求进行调整、提供有针对性的输出,如保留原始数据中某一单词不变。
由于回译的本质是复述,因此增广数据相比于原始数据的内容变化有限,在对训练数据多样性要求较高的场景中,不能很好地满足需求。
2.3加入噪声
单词替换、回译方法的重点是使增广数据尽量与原始数据相似,构造更多类似于原始数据的新数据。与之相比,加入噪声的方法则为文本添加不太影响语义的微弱噪声,使之适当偏离原始数据,在扩大训练数据量的同时,提高模型的鲁棒性。人类通过对语言现象及先验知识的掌握,可以大大降低微弱噪声对语义理解的影响,但这种噪声可能为模型带来挑战。以下将对该方法以文本形式、顺序、语义三个方面进行介绍。
2.3.1文本形式相关的噪声
单词级别的缩写还原、句子级别的句式转换(如主动变被动)虽然给语句的形式带来一定改变,但未对语义产生影响。将原始数据按照规则进行合理的形式变换,得到的增广数据将带有形式变化的噪声,提升模型对句式的把握。
(1)单词级别的简单模式匹配变换
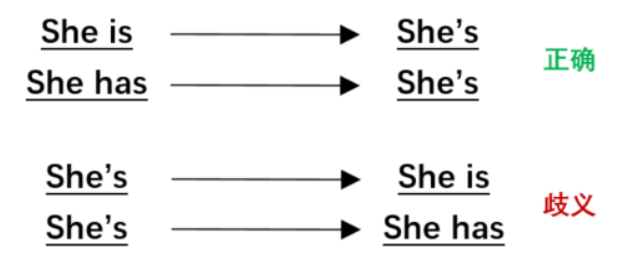
Be动词、情态动词、否定等缩写和原型间的转换属于简单模式匹配变换(text surface transformation),这种单词级别的语言现象虽然在形式上发生变化,却不改变语义。Coulombe et al.(2018)[12]介绍了使用正则表达式对英语中的简单模型进行变换,如通过一些固定的规则在be动词、情态动词和否定等的缩写和原型之间变换。图9为be动词的缩写、原型间的变换示例。

(2)句子级别的语法树变换
该方法首先得到整个原始句子的依存树,并基于依存树使用规则对句子进行转换,来得到语法正确、语义不变的增广数据。相比于原始数据,该方法产生的增广数据携带有句式相关的噪声。
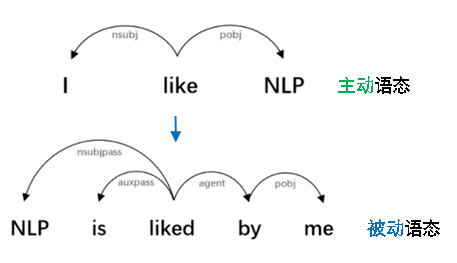
Coulombe et al.(2018)[12]介绍了这种通过依存树进行数据增广的方法:基于一个句子的依存树,按照规则进行转换,能够保持新句子的语法正确(如图11)。Min et al.(2020)[13] 借鉴了这种思想,如利用规则替换原句的主语宾语、将主动语态变为被动语态等。
引入文本形式相关的噪声,即进行单词级别的简单模式匹配变换或句子级别的句式变换。它能够保证数据的语义不发生改变,同时增加模型对文本相应形式的鲁棒性。这种方法通常需要人为设计转换的规则,可控性强,同时增广过程直接可靠。
2.3.2文本顺序相关的噪声
自然语言的语义对文本顺序信息敏感,如句子内不同单词的顺序和篇章内不同句子的顺序决定了句子或篇章的语义。但同时,如果在合理的范围内对文本顺序进行少量的调换[14],其结果对于人类而言仍然是可读的,即可通过阅读调换了语序的文本来理解原始文本的语义(如图12)。因此,少量的顺序调换可作为数据增广的方法,向模型引入文本顺序相关的噪声。

(1)单词级别的文本顺序交换
该方法是指句子中不同单词之间进行顺序交换,如Wei et al.(2019)[5]提出了名为EDA的文本分类任务数据增广工具包,除了包括前文提到的近义词替换方式,也包括单词随机交换的方法,如图13。该工作在句子中随机选择两个单词并交换位置,重复n次。其中,随机交换的次数n与句子长度l成正比,即n=αl。

(2)句子级别的文本顺序交换
该方法是指篇章中不同句子之间进行顺序交换,如Yan et al.(2019)[15]使用随机排序的方法对法律文书进行句子级别的操作,如图14。由于句子独立地包含了相对完整的语义,且文书中句子的顺序对原始文本的含义影响不大,因此将句子打乱顺序进行随机排列,从而得到增广文本。
引入文本顺序相关的噪声,对句子和篇章分别进行适量的单词级别、句子级别的顺序调换,对语义的影响有限。使用这种方法需要合理设置顺序交换的次数和对象,保证增广数据的语义不过分偏离原始数据。
2.3.3文本语义相关的噪声
这类方法通常指通过单词或句子级别的删除、插入、替换等操作,为原始语料带入语义相关的噪声。
(1)基于随机删除的文本语义噪声
该方法包括“单词级”和“句子级”两种层次的删除操作,分别表示在句子中随机删除单词和在篇章中随机删除句子。
在单词级别的方法中,Wei et al.(2019)[5]按照概率p随机删除原始句子中的每个单词(如图15)。Xie et al.(2017)[16]借鉴了“word-dropout”的思想,随机删减句子中的部分单词避免模型过拟合,但与Wei et al.(2019)[5]不同的是,该工作用“_”作为占位符替换被删除单词的位置,表示该位置的信息为空。Yu et al.(2019)[17]包括单词、句子两种层次的删减,在单词级别上,首先对一条语句做attention,来衡量句子中不同单词的重要程度。根据该重要程度对句子中的单词进行删减:将重要性低于一定阈值的单词按照0.5的概率随机删除,剩下的单词互相拼接作为单词级别的增广数据(WordSet)。

在句子级别的方法中,与前文单词级别的随机删除类似,Yu et al.(2019)[17]在句子级别同样使用attention来衡量篇章中每个语句的重要性:对于包括10个及以上句子的篇章,首先对其做句子级别的attention,之后直接抽取出最重要的若干条语句,互相拼接作为句子级别的增广结果(SentSet)。同时,该工作随机抽取相同数量的WordSet和SentSet得到包含两种增广层次的HybirdSet。Yan et al.(2019)[15]在法律文书分类任务中同样运用随机删除的方法:由于文书包含许多不相关的陈述,删除它们不会影响对案例的理解,因此该方法按照一定概率随机删除原始文书中的一个句子(如图14);如果原始文书仅包含一个句子,则不进行任何处理。
(2)基于随机插入的文本语义噪声
此处仅对单词级别的随机插入方法进行介绍,由于句子级别的随机插入需要提供标签信息,因此将其划入另一种类别的增广方法,并在后文介绍。
Wei et al.(2019)[5] 的EDA工具包中包括单词级别随机插入的方法,如图16。给定一条语句,选择其中一个非停用词,通过WordNet得到该单词的任意一个近义词,并将近义词插入句子中的任意位置,重复n次。其中,次数n与句子长度l成正比,即n=αl。
(3)基于随机替换的文本语义噪声
此处仅对单词级别的随机替换方法进行介绍,由于句子级别的随机替换需要提供标签信息,因此将其划入另一种类别的增广方法,并在后文介绍。
Coulombe et al.(2018)[12]介绍了引入常见拼写错误的文本作为增广数据,来模拟真实文本中包含此类噪声的情况,从而使模型对这种特殊类型的文本噪声变得更加鲁棒。英语中常见的拼写错误列表可以通过 Oxford Dictionaries的在线资源得到:https://en.oxforddictionaries.com/spelling/common-misspellings
文本分类任务中,不同单词对分类预测的贡献不同,为了避免增广数据干扰分类准确性,Xie et al.(2019)[9]保留句中对分类结果影响较大的keywords,同时将其他普通单词随机替换为整个词表中的非keywords单词。该工作使用TF-IDF值评估单词重要性,该单词被替换的概率与其重要性负相关。在替换过程中,使用整个词表中的非keywords单词替换该原始单词:使用频率和IDF值计算词表中每一个单词的重要性,归一化后作为使用该单词替换的概率。
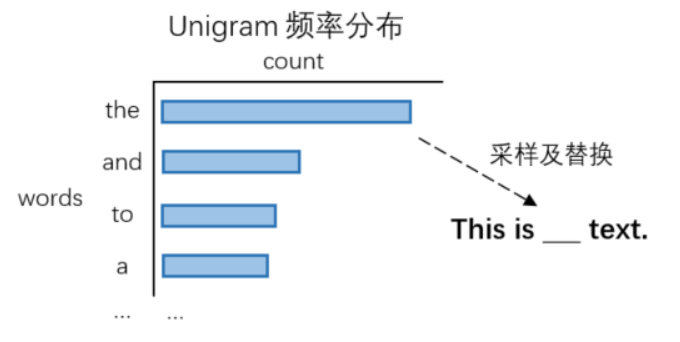
与Xie et al.(2019)[9]类似,Xie et al.(2017)[16]同样使用词表中的其他单词替换原始单词。该工作通过unigram 频率分布采样得到其他单词(如图17),将新单词作为噪声替换原始单词,产生增广数据。其中,unigram频率可通过单词在训练语料中的出现次数得到。
引入文本语义相关的噪声可通过随机删除、插入、替换的方式完成。与引入文本顺序的噪声类似,少量的语义噪声不会对数据语义造成严重干扰。
其中,随机删除不涉及标签信息,因此可分为单词级别和句子级别的操作。而随机插入和随机替换的方法引入了新的信息,为了保证标签不变,单词级别的插入和替换可利用标签无关的外部词表和语料词表;句子级别的插入和替换则需要对相同标签的其他样本句子进行操作。由于句子级别的随机插入和替换方法考虑了数据的标签,我们将其单独作为一个增广类别(下文介绍),以区分不考虑标签信息的引入噪声方法。
加入噪声的方法为文本添加不太影响语义的微弱噪声,使之适当偏离原始数据,该方法有以下优点:
引入人类的语言学先验知识,提升模型的鲁棒性。
该方法灵活、可控,可根据任务需求、数据集的情况选择适合的噪声种类。
无需训练,不需要考虑标签信息,简单方便。
同时,该方法有以下缺点:
需要人为合理选择噪声的种类、来源,控制噪声的比例,否则会对增广数据的质量造成影响。
该方法对文本的改动较为局限,得到的增广数据多样性不足。
2.4基于同标签样本的句子级文本语义噪声
如前文所述,通过“随机插入”和“随机替换”方法引入文本语义噪声时需要保证噪声不改变数据标签。在单词级别上,通常使用标签无关的外部词表或语料词表;在句子级别上,通常使用相同标签的其他样本句子。由于句子级别的随机插入和随机替换方法考虑了数据的标签,我们将其单独作为一个增广类别,以区分上文不考虑标签信息的引入噪声方法。
2.4.1基于随机插入的文本语义噪声
由于具有相同指控的案件在其文书中有很多相似的句子,Yan et al.(2019)[15]在法律文书分类的任务中使用句子级随机插入的方法,即随机选择带有相同标签的其他样本中的句子插入原始样本,得到新的数据(如图14)。
2.4.2基于随机替换的文本语义噪声
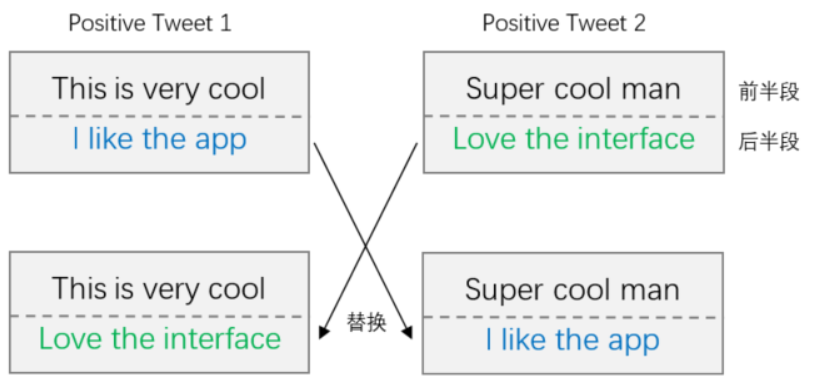
Luque et al.(2019)[10]在推文情感分析的任务中,将标签相同的推文分别分成两半,给定一个原始的前半段推文,在后半段推文的集合中随机采样,并与该原始前半段推文拼接,得到新数据。虽然这样产生的数据可能包括不完整的句子,相比于单个单词,它仍携带相对完整的语义和情感极性(如图18)。
整体来说,加入基于同标签样本的句子级文本语义噪声比较简单,无需训练,只需要找到合适的相同标签其他样例即可操作。
2.5生成式模型
与前文利用掩码语言模型进行单词替换的方法和回译方法不同,生成式模型并非直接使用已有的模型补全被mask的单词或生成增广语句,而是根据任务相关的启发式信息训练模型,再有针对性地生成增广数据。与基于同标签样本的句子级文本语义噪声方法类似的是,生成式模型同样引入标签信息,来保证生成的增广数据的标签不变。
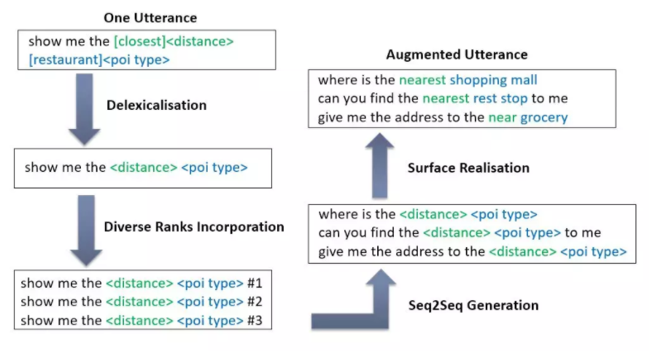
Hou et al.(2018)[18]针对任务型对话系统的语言理解模块,提出了seq2aeq的数据增广模型。给定一条原始样例,首先通过抽槽对句子进行去多样化操作,将目标多样化等级(如1,2,3)以token的形式加入语句表示。将原句及多样化等级共同作为输入送入Seq2Seq模型中,生成新的语句,最后对其进行填槽操作从而得到增强数据。该增广方法的流程如图19所示:
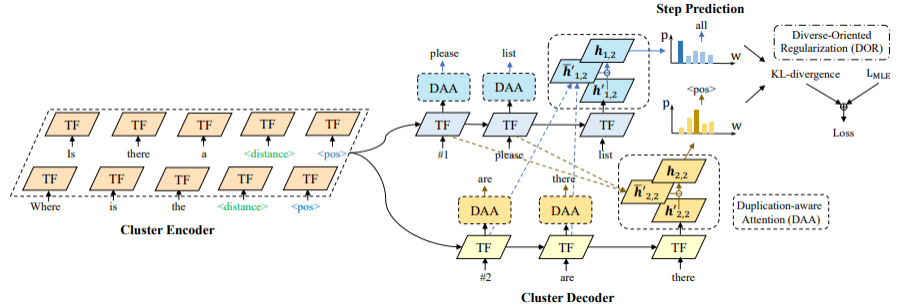
大多Seq2Seq增广方法的输入与输出序列都是单一的句子,因此倾向于生成重复的增广数据,限制了数据增广的有效性。针对这个问题,Hou et al.(2020)[19]在槽位填充任务中提出了C2C-GenDA模型(如图20),给定具有相同语义框架的一组句子(input cluster),模型一次性生成多个新句子(output cluster),从而解决前人工作的多样性不足问题。该方法的生成模型基于Transformer的编码器和解码器,在编码时采用特殊符号拼接输入中的句子;在解码时使用多个共享参数的解码器同步生成多个新句子。同时,通过注意力机制为模型提供编码器及解码器的表达方式信息,对重复的生成进行惩罚,并通过损失函数鼓励模型生成更多样的句子。
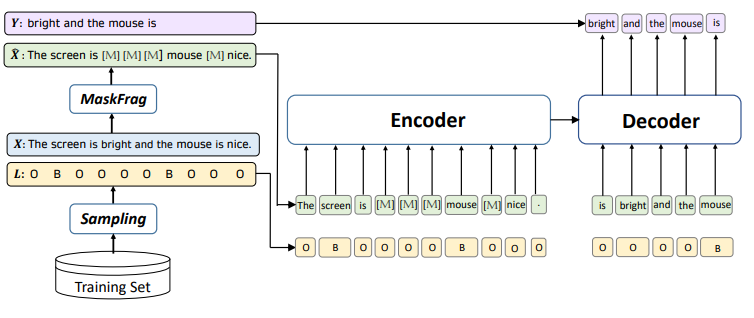
Li et al.(2020)[22]在序列标注任务中使用掩码语言模型进行数据增广,如图21。该方法克服了前人工作中增广数据的序列标签与原始数据序列标签不匹配的问题,以及增广数据丧失原始数据包含的情感、观点而变为普通陈述句的问题。该工作随机增广长度大于5的训练数据,数据被采样的概率与其长度正相关。每条原始数据中,数量为句子长度一半的连续单词被[MASK]替换,但是保持序列标签中非O标签对应的单词不变。将这些被mask的句子与其序列标签一起作为模型的输入,训练模型重建这些被mask掉的内容。训练完成后,将该模型作为增广数据的生成模型,输入被mask的训练样本及其序列标签,利用模型补全被mask的单词得到完整句子,作为增广后的新数据。通过这种方法,能够利用无限的领域外表述方式和知识,在保证新数据序列标签有效性的同时,得到表达方式更多样的新数据。
整体来说,生成式模型包括以下优点:
相比于单词替换、加入噪声等方法只能对数据进行局部的调整,生成式模型可以通过训练直接按照需求生成或补全完整句子。
相比于回译,生成式模型更为可控。
通过设计优化目标和利用预训练模型本身具有的丰富知识可以保证增广文本的多样化。
同时,它也具有一些缺点:
该方法需要一定量的数据保证模型的训练。
由于需要人为设计优化目标,以引导模型生成有效的增广数据,因此该方法不如单词替换等方法操作简单。
2.6Mixup方法
运用前面5种方法进行数据增广并投入任务训练可分为三步:(1)人为指定增广规则或通过训练得到增广模型;(2)利用固定的规则或模型对原始文本做数据增广,得到自然语言形式的增广数据;(3)将原始数据和增广数据一起输入任务模型进行训练。与之不同的是,Mixup方法可以将三个步骤合在一起:直接将原始数据输入任务模型,增广步骤随着训练过程同步进行,得到的词向量形式的增广数据直接与原始数据一起参与模型的训练。
整体来说,Mixup方法与之前的方法有三点不同:(1)Mixup的增广过程与任务模型的训练不是独立的,而是包含并贯穿在任务模型训练过程中。因此按照增广过程与任务模型训练的相对关系, Mixup的增广方法是在线的(online),而前面的生成式模型方法是离线的(offline);(2)Mixup方法不会显示地得到自然语言形式的增广数据,而是在模型中隐式地得到词向量形式的增广数据;(3)Mixup方法不局限于增广某一特定标签的数据,而是能生成跨标签的增广数据。
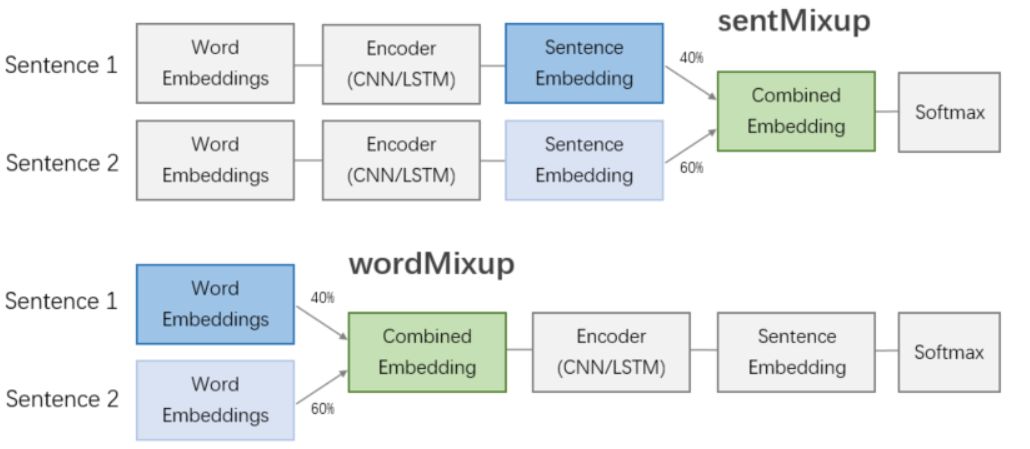
Mixup的思想首先出现于图像领域。Zhang et al.(2017)[23]在图像分类任务中提出了简单有效的Mixup增广方法,将两张图片及其标签的向量表示分别进行混合得到新样本,该方法能够提升模型的鲁棒性。受到该工作的启发,Guo et al.(2019)[24]将Mixup思想引入NLP领域,根据插值位置的不同,提出了两种方法(如图22):wordMixup直接对输入的词向量进行插值混合,而sentMixup在对输入句子进行编码得到句子embedding之后,才进行插值混合。
值得注意的是,wordMixup和sentMixup两种方法的预测阶段同样将两条原始数据的标签进行插值混合后再计算损失:
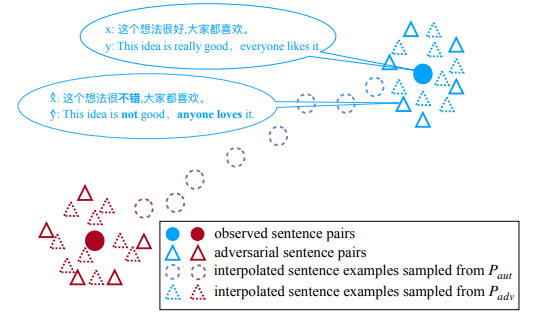
Cheng et al.(2020)[25]在机器翻译任务中,将两条样例先按照单词替换的方法得到对抗样例,之后提出两种mixup方法(如图23):在同一条原始数据的对抗样本之间进行插值(通过下图直线三角插值得到虚线三角),和在两条原始文本之间进行插值(通过下图实心圆圈插值得到虚线圆圈),以此得到新的数据。
Mixup的方法是一种较新的增广方式。这种方法有以下优点:
通过细粒度的词向量对输入数据甚至标签进行插值混合,能够得到更为平滑的增广数据。
该方法不受数据标签的限制,可跨标签增广。
同时,它也具有一定缺点:
Mixup方法需要对模型进行训练,且其增广数据不是直观的自然语言形式,因此该方法的难度高于单词替换、回译、加入噪声等方法。
对被插值数据之间的相似度等有一定的要求,因此需要人为预先设定。
3.分析
3.1效果分析
尽管近些年自然语言处理领域出现了多种数据增广方法,但是很难直接比较它们的性能。这是因为不同的任务类型适合不同的增广方法,同时不同的工作常常在不同的数据集上验证自己的表现,这导致它们的任务类型、评价指标、数据集大小、数据集标签等难以统一。另外,有些工作仅仅利用数据增广来进一步提升性能,数据增广并非它们的核心贡献。此时模型性能的提升也要考虑到不同的模型设计和超参数配置,不能直接用于数据增广方法效果的比较。因此,我们基于上文介绍的工作,通过不同的任务类型来对数据增广方法进行分析(以各类任务可使用增广方法的数量排序)。
文本分类: 已有的所有6类数据增广方法广泛应用于文本分类任务中,且文本分类任务在绝大部分增广方法对应的工作中数量都是最多的。常见的任务及数据集包括:综合文本分类数据集GLUE,普通文本分类数据集IMDb、TREC、Sub,自然语言推理数据集SICK、MNLI,情感分析数据集TASS 2019、推特语料,等等。文本分类任务通常直接考察模型对语义的理解,同时其重点在于文本中影响分类的核心单词。而现有的大多数增广方法(单词替换、回译、生成式模型、Mixup)都能尽量控制增广数据的语义贴近原始数据。即便是加入噪声的方法也可通过人为控制,使新数据的语义变化在合理范围内。
文本生成: 文本生成任务通常使用回译、引入噪声、Mixup的方法。在文本风格迁移任务中,Zhang et al.(2020)[11]面临GYAFC数据集(在正式及非正式文本间迁移)样例不足的问题,因此该工作收集推特语料作为非正式文本,利用机器翻译模型生成对应的正式文本。在机器翻译任务中,Xie et al.(2017)[16]和Cheng et al.(2020)[25]分别使用文本语义噪声和Mixup的方法使IWSLT、NIST和WMT等数据集中的数据更加平滑。
序列标注: 本文所介绍的序列标注任务只应用了生成式模型的方法,这是因为序列标注任务的标签是token而非句子级别的,因此单词替换、回译等其他方法不适用于该任务。生成式模型的可控性较强,可通过人为规定的优化目标输出满足需求的增广数据。常见的序列标注任务及其数据集包括:任务型对话系统任务中语言理解模块的ATIS和SNIPS数据集,和细粒度情感分析的子任务Aspect Term Extraction的SemEval-2014 Task 4数据集。
语言建模: 语言建模基于给定的部分句子预测下一个单词,是自然语言处理的基础任务之一。Xie et al.(2017)[16]构建了基于文本语义噪声数据的递归神经网络语言模型,证明了噪声能带来平滑的效果。其中空白噪声包含的mask思想对语言建模的提升,在BERT中也得到类似的印证。
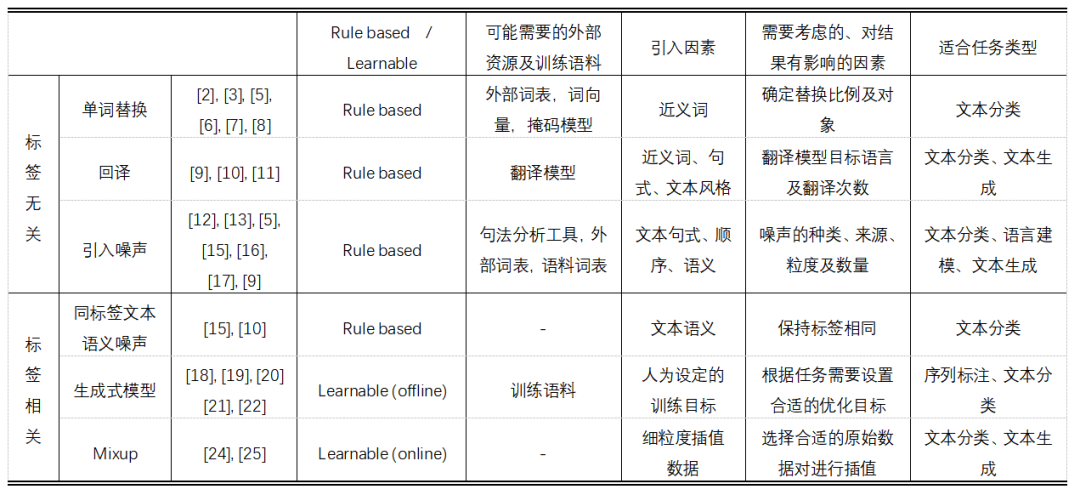
3.2方法比较
表1 自然语言数据增广方法总结
4.总结
数据增广方法通过扩大训练数据的数据量,能有效提升模型的性能和鲁棒性。本文介绍了6类NLP中的数据增广方法,它们又可分为两大类,包括标签无关的通用方法(单词替换、回译、引入噪声)和标签相关的特定方法(同标签文本语义噪声、生成式模型、Mixup方法)。未来NLP领域的数据增广将变得更复杂,加入外部知识[21]、使用更复杂的方法[25]、生成模型[18] ,甚至元学习等[26][27] 都将成为潜在趋势。
参考资料
Luan F, Paris S, Shechtman E, et al. Deep photo style transfer[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4990-4998.
[2]Zhang X, Zhao J, LeCun Y. Character-level convolutional networks for text classification[J]. Advances in neural information processing systems, 2015, 28: 649-657.
[3]Mueller J, Thyagarajan A. Siamese recurrent architectures for learning sentence similarity[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2016, 30(1).
[4]Miller G A. WordNet: a lexical database for English[J]. Communications of the ACM, 1995, 38(11): 39-41.
[5]Wei J, Zou K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks[J]. arXiv preprint arXiv:1901.11196, 2019.
[6]Wang W Y, Yang D. That’s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using# petpeeve tweets[C]//Proceedings of the 2015 conference on empirical methods in natural language processing. 2015: 2557-2563.
[7]Liu S, Lee K, Lee I. Document-level multi-topic sentiment classification of Email data with BiLSTM and data augmentation[J]. Knowledge-Based Systems, 2020: 105918.
[8]Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural language understanding[J]. arXiv preprint arXiv:1909.10351, 2019.
[9]Xie Q, Dai Z, Hovy E, et al. Unsupervised data augmentation for consistency training[J]. arXiv preprint arXiv:1904.12848, 2019.
[10]Luque F M. Atalaya at tass 2019: Data augmentation and robust embeddings for sentiment analysis[J]. arXiv preprint arXiv:1909.11241, 2019.
[11]Zhang Y, Ge T, Sun X. Parallel Data Augmentation for Formality Style Transfer[J]. arXiv preprint arXiv:2005.07522, 2020.
[12]Coulombe C. Text data augmentation made simple by leveraging NLP cloud APIs[J]. arXiv preprint arXiv:1812.04718, 2018.
[13]Min J, McCoy R T, Das D, et al. Syntactic data augmentation increases robustness to inference heuristics[J]. arXiv preprint arXiv:2004.11999, 2020.
[14]Reading Chinese script: A cognitive analysis[M]. Psychology Press, 1999.
[15]Yan G, Li Y, Zhang S, et al. Data Augmentation for Deep Learning of Judgment Documents[C]//International Conference on Intelligent Science and Big Data Engineering. Springer, Cham, 2019: 232-242.
[16]Xie Z, Wang S I, Li J, et al. Data noising as smoothing in neural network language models[J]. arXiv preprint arXiv:1703.02573, 2017.
[17]Yu S, Yang J, Liu D, et al. Hierarchical Data Augmentation and the Application in Text Classification[J]. IEEE Access, 2019, 7: 185476-185485.
[18]Hou Y, Liu Y, Che W, et al. Sequence-to-sequence data augmentation for dialogue language understanding[J]. arXiv preprint arXiv:1807.01554, 2018.
[19]Hou Y, Chen S, Che W, et al. C2C-GenDA: Cluster-to-Cluster Generation for Data Augmentation of Slot Filling[J]. arXiv preprint arXiv:2012.07004, 2020.
[20]Anaby-Tavor A, Carmeli B, Goldbraich E, et al. Do Not Have Enough Data? Deep Learning to the Rescue![C]//AAAI. 2020: 7383-7390.
[21]Kumar V, Choudhary A, Cho E. Data augmentation using pre-trained transformer models[J]. arXiv preprint arXiv:2003.02245, 2020.
[22]Li K, Chen C, Quan X, et al. Conditional Augmentation for Aspect Term Extraction via Masked Sequence-to-Sequence Generation[J]. arXiv preprint arXiv:2004.14769, 2020.
[23]Zhang H, Cisse M, Dauphin Y N, et al. mixup: Beyond empirical risk minimization[J]. arXiv preprint arXiv:1710.09412, 2017.
[24]Guo H, Mao Y, Zhang R. Augmenting data with mixup for sentence classification: An empirical study[J]. arXiv preprint arXiv:1905.08941, 2019.
[25]Cheng Y, Jiang L, Macherey W, et al. Advaug: Robust adversarial augmentation for neural machine translation[J]. arXiv preprint arXiv:2006.11834, 2020.
[26]Hu Z, Tan B, Salakhutdinov R R, et al. Learning data manipulation for augmentation and weighting[C]//Advances in Neural Information Processing Systems. 2019: 15764-15775.
[27]Cai J, Shen S M. Cross-Domain Few-Shot Learning with Meta Fine-Tuning[J]. arXiv preprint arXiv:2005.10544, 2020.
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

