端到端语音翻译的课程预训练
Curriculum Pre-training for End-to-End Speech Translation
链接:https://arxiv.org/abs/2004.10093
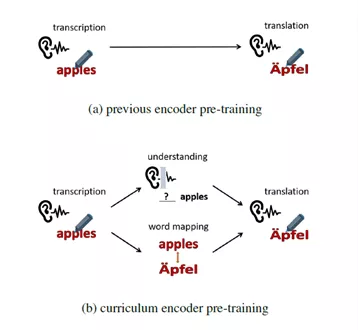
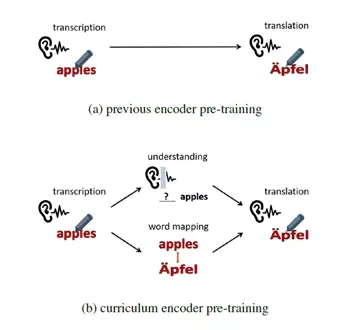
图1:课程预训练方法与其他预训练方法对比
端到端语音翻译(Speech Translation, ST)利用一个神经网络模型将一段源语言语音直接翻译为目标语言的文本。这个任务对模型编码器带来很大负担,因为它需要同时学习语音转录(transcription)、语义理解(understanding)和跨语言语义匹配(mapping)。已有工作利用语音识别(Automatic Speech Recognition, ASR)数据上进行预训练以获得更强大的编码器。然而,这种预训练方式无法学习翻译任务所需要的语义知识。受到人类学习过程的启发,本文提出了一种课程预训练(Curriculum Pretraining)的方式。如图1所示,在学习语音翻译之前,模型首先学习一门基础课程用于语音转录,随后学习两门用于语义理解和单词映射的高级课程,这些课程的难度逐渐增加。
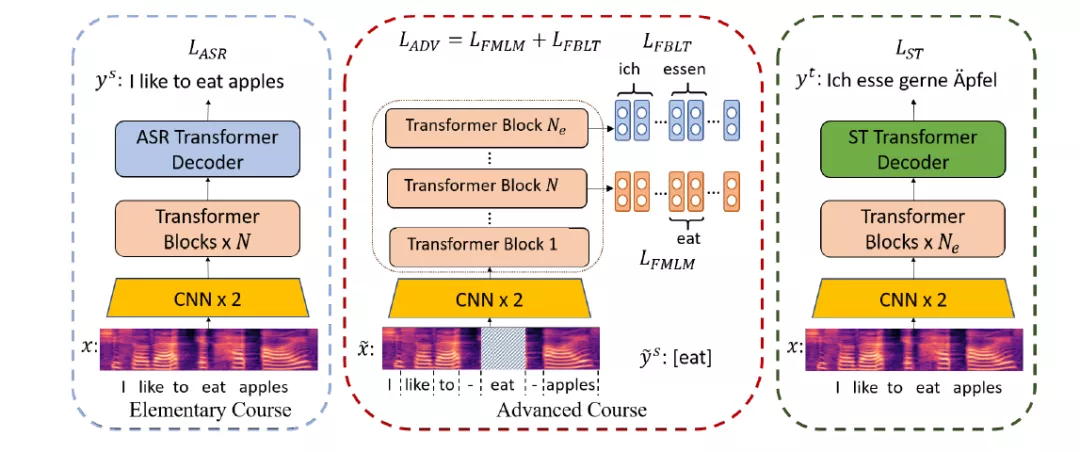
图2:训练过程
如图2所示,训练过程分为三个阶段:首先利用语音识别任务作为基础课程;然后在高级课程中,我们提出了两种任务,分别命名为 Frame-based Masked Language Model (FMLM) 和 Frame-based Bilingual Lexicon Translation (FBLT)。在 FMLM 任务中,首先将源语言语音和单词做对齐,然后随机遮蔽部分单词对应的语音片段,并令模型预测正确的单词。在 FBLT 任务中,我们使模型预测每个语音片段所对应的目标语言单词。这两个任务在编码器的不同层进行;最终,将模型在语音翻译数据上进行微调。实验表明,课程预训练的方法在英德和英法语音翻译数据集上都取得了明显改进。