自动机器学习:团队如何在自动学习项目中一起工作?(附链接)

翻译:王琦
校对:冯羽
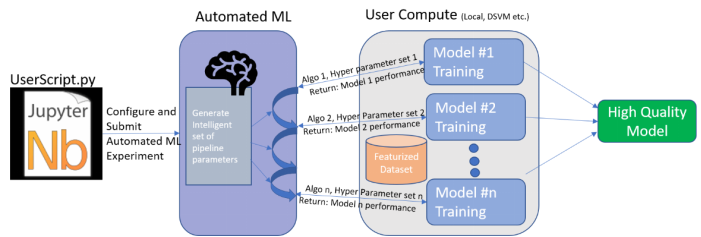
去年11月,我写了一篇关于使用自动机器学习来进行AI民主化(democratization)的文章(见下面链接)。
附链接:
https://medium.com/microsoftazure/democratize-artificial-intelligence-with-automated-machine-learning-169b348a9509
在今天这篇文章中,我将会向你展示自动机器学习的用例(发布在Github上了,见下面链接)。
附链接:
https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/automated-machine-learning/forecasting-orange-juice-sales/auto-ml-forecasting-orange-juice-sales.ipynb?WT.mc_id=azuremedium-blog-lazzeri
此外,本文还介绍了数据科学家、项目经理和业务主管各自如何使用自动机器学习来改进团队合作和学习,并促进数据科学新方案的成功实现。
当谈到在组织里执行机器学习项目时,数据科学家、项目经理和业务主管需要一起工作来部署最好的模型,从而满足特定的业务目标。这一步的中心目标就是识别出需要在分析中预测的关键业务变量。我们将这些变量看成模型的目标,然后使用和它们相关的指标来确保项目的成功。
在这个用例中(该用例对公众开放,发布在GitHub上),我们将会看到在零售商工作的数据科学家、项目经理和业务主管如何利用自动机器学习和Azure机器学习服务来减少商品的库存过剩。Azure机器学习服务是一个你可以用来训练、部署、自动化和管理机器学习模型的云服务,所有这些都可以在云提供的范围内进行。Azure机器学习服务中的自动机器学习是获取已定义目标特征的训练数据,并通过算法组合和特征选择进行迭代,从而基于训练分数来为你的数据自动选择最好模型的过程。
多余的库存很快就变成了一个流动性问题,除非我们通过折扣和促销来减少利润,否则它就不能转换成现金。或者更糟糕的是,当其累计到一定程度被送到其他渠道比如经销店,这会延迟其销售。提前确定哪些产品不会达到他们期望的周转水平,并通过与销售预测相符的库存补给来控制补货,这是帮助零售商实现投资回报率(ROI)的关键因素。让我们看看团队如何着手解决这个问题以及自动机器学习如何使整个公司的AI民主化。
为公司确定正确的业务目标
正确的产品组合和库存水平可以取得丰厚的销售额和利润。要实现这一理想组合,就需要拥有最近的、准确的库存信息。手动处理不仅花费时间,导致当前的、准确的库存信息的延迟,而且增加了出错的可能性。这些延迟和错误很可能会由于库存过剩、库存不足和缺货而导致收入损失。
库存过剩也可能占用宝贵的仓库空间,并占用本应用于购买新库存的现金。但以清算模式出售过剩的库存可能会引起一系列问题,例如损害声誉和冲击其他现有同类产品的销售。
作为数据科学家与业务运营之间桥梁的项目经理,与业务主管联系,讨论使用其内部的、以往的销售额中的一部分来解决其库存过剩问题的可能性。项目经理和业务主管通过询问和完善与业务目标相关的具体问题来定义项目目标。
此阶段主要有两个任务:
定义目标:项目经理和业务主管需要识别业务问题,最重要的是,提出问题以定义数据科学技术可以针对的业务目标;
识别数据源:项目经理和数据科学家需要找到相关数据来帮助回答定义项目目标的问题。
寻找正确的数据和流水线
这一切都要从找数据开始。项目经理和数据科学家需要识别包含业务问题答案的已知示例的数据源。 他们寻找以下类型的数据:
与问题相关的数据。 他们是否有针对目标的指标以及与目标相关的特征?
可以准确衡量其模型目标和感兴趣特征的数据。
在此阶段,数据科学家需要解决三个主要的任务:
将数据应用到目标的分析环境中;
探索数据以确定数据质量是否足以回答问题;
建立数据流水线以对新数据或定期刷新的数据进行评分。
在将数据从源位置移动到可以运行分析操作的目标位置之后,数据科学家开始处理原始数据来产生干净的、高质量的数据集,该数据集与目标变量的关系是被充分理解的。在训练机器学习模型之前,数据科学家需要对数据有充分的了解,通过创建数据摘要和可视化来审核数据的质量,并在准备好建模之前提供处理数据所需的信息。
最后,数据科学家还负责开发数据流水线解决方案的架构,该架构会定期对数据进行刷新和评分。
通过自动机器学习预测橙汁的销售
数据科学家和项目经理决定使用自动机器学习有以下几个原因:自动机器学习让有或没有数据科学专业知识的客户都能针对任何问题来确定端到端机器学习的流水线,从而在花费更少时间的同时来取得更高的准确性。 而且,它还可以运行大量实验,从而加快了面向生产就绪型的智能经验的迭代。
让我们看看使用自动机器学习进行橙汁销售预测的过程如何实现这些好处。
在对业务目标以及应使用哪种类型的内部的以往数据来达成目标达成一致后,数据科学家将创建一个工作区。该工作区是该服务的顶级资源,为数据科学家提供了一个集中的地方来处理他们需要创建的所有工件。在Azure机器学习服务中创建工作区时,会自动添加以下Azure资源(如果它们在区域中可用):
Azure容器注册表
Azure存储
Azure应用程序洞见
Azure密钥保管库
要运行自动机器学习,数据科学家还需要做一个实验。实验是工作区中的一个命名对象,它代表一个预测性任务,该任务的输出是经过训练的模型和该模型的一组评估指标。
数据科学家现在已经准备好加载以往的橙汁销售数据,并将CSV文件加载到简单的pandas 中的DataFrame类型中。CSV中的时间列称为WeekStarting ,因此它会被专门地解析为日期时间类型。
DataFrame中的每一行表示某个商店中某个橙汁品牌的每周销售量。数据还包括销售价格、用来显示橙汁品牌每周是否在商店中做广告的标记以及基于商店位置的一些客户人口统计信息。由于历史原因,该数据还包括销售数量的对数。
我们目前的任务是为“数量”列构建时间序列模型。重要的是我们要注意到该数据集由许多单独的时间序列组成;每个时间序列都是针对商店和品牌的唯一组合。 为了区分各个时间序列,我们定义了grain,grain是其值能够确定时间序列之间边界的列。
为了以后的预测效果评估,我们将数据分为训练集和测试集。在这之后,数据科学家开始建模来执行预测任务,并且自动机器学习使用针对时间序列的预处理和估计步骤。自动机器学习将执行以下预处理步骤:
检测时间序列样本的频率(例如每小时、每天、每周),并为不存在的时间点创建新记录来让序列变得有规律。 有规律的时间序列具有定义明确的频率,并且在连续的时间间隔中的每个采样点都有一个值;
通过正向填充(forward-fill)和特征列的列中位数来估算目标中的缺失值;
创建基于grain的特征来实现不同序列之间的固定效应;
创建基于时间的特征来协助季节性模式的学习;
将分类变量编码为数字量。
对于一个自动机器学习训练任务,AutoMLConfig对象定义了设置和数据。以下是用于训练橙汁销售预测模型的自动机器学习配置参数的概要:

访问GitHub以获取有关预测的更多信息(见下面链接)。每次迭代都在实验中运行,并存储来自自动机器学习迭代的序列化的流水线,直到它们找到在验证集上表现最佳的流水线为止。
附链接:
https://github.com/Azure/MachineLearningNotebooks/blob/master/how-to-use-azureml/automated-machine-learning/forecasting-orange-juice-sales/auto-ml-forecasting-orange-juice-sales.ipynb?WT.mc_id=azuremedium-blog-lazzeri
评估完成后,数据科学家、项目经理和业务主管再次会面以检查预测结果。项目经理和业务主管的工作是了解输出并根据这些结果选择实际步骤。 业务主管需要确认最佳模型和流水线以满足业务目标。此外,机器学习解决方案以可接受的准确性回答了把系统部署到生产中的各种问题,以供内部销售的预测应用程序使用。
微软在自动机器学习上的投资
自动机器学习基于Microsoft Research部门的一项突破。该方法结合了协同过滤和贝叶斯优化的思想,可以智能、高效地搜索可能的机器学习流水线的巨大空间。
现在,它作为Azure机器学习服务的一部分提供给你。正如你在此处所看到的,无论有无数据科学专业知识,自动机器学习都可以使客户确定端到端机器学习流水线,以解决任何问题,并在提高准确性的同时节省时间。它还可以运行大量实验并加快迭代速度。自动机器学习如何使你的组织受益?你的团队如何使用机器学习来更紧密地合作从而达到业务目标?
资源
-
了解有关Azure机器学习服务的更多信息: https://docs.microsoft.com/en-us/azure/machine-learning/service/?WT.mc_id=azuremedium-blog-lazzeri -
了解有关自动机器学习的更多信息: https://docs.microsoft.com/en-us/azure/machine-learning/concept-automated-ml -
开始免费试用Azure机器学习服务: https://azure.microsoft.com/en-us/trial/get-started-machine-learning/?WT.mc_id=azuremedium-blog-lazzeri
作者简介:
Francesca Lazzeri是一位机器学习科学家、作家和演讲者。她领导着一支由微软的云倡导者、数据科学家和开发人员组成的国际团队。加入微软之前,她是哈佛大学技术与运营管理部门的研究员。她还是微软“Women@NERD”协会的董事会成员、麻省理工学院和哥伦比亚大学的数据科学导师以及AI社区的活跃成员。
译者简介

王琦,中国科学院大学研一在读,研究方向是机器学习与数据挖掘。喜欢探索新事物,是一个热爱学习的人。
——END——
