干货——图像分类(下)
用于超参数调优的验证集
首先,来介绍参数和超参数的基本知识。
在机器学习或者深度学习领域,参数和超参数是一个常见的问题,个人根据经验给出了一个很狭隘的区分这两种参数的方法。
参数:就是模型可以根据数据可以自动学习出的变量,应该就是参数。比如,深度学习的权重,偏差等
超参数:就是用来确定模型的一些参数,超参数不同,模型是不同的(这个模型不同的意思就是有微小的区别,比如假设都是CNN模型,如果层数不同,模型不一样,虽然都是CNN模型哈。),超参数一般就是根据经验确定的变量。在深度学习中,超参数有:学习速率,迭代次数,层数,每层神经元的个数等等。
在选择模型算法的同时,会有很多选择,比如K-NN中k的选择等案例。所有这些选择,被称为超参数(hyperparameter)。在基于数据进行学习的机器学习算法设计中,超参数是很常见的。一般说来,这些超参数具体怎么设置或取值并不是显而易见的。
主要是通知实验来决定选择哪个值。我们就是这么做的,但这样做的时候要非常细心。特别注意:决不能使用测试集来进行调优。如果你这样实施后,你会发现效果特征好,但是算法在实际运行的时候,遇到新来的特征,你会发现效果特别差,远远低于你之前的预期,这种情况在该领域也有专有的称呼——过拟合。
所以,最终测试的时候再使用测试集,可以很好地近似度量你所设计的分类器的泛化性能。
测试数据只用一次,在模型训练和验证结束后,最终才会使用该数据,主要为了评价模型的好坏。
针对这,其实有很多调优的方法。我们可以从训练集中取出一部分数据用来调优,称之为验证集(validation set)。最后,会作图分析哪个k值表现最好,然后用这个k值来运行测试集,并作出对算法的评价。
交叉验证。是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。常见CV的方法如下:
Hold-Out Method
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。 此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关 系,所以这种方法得到的结果其实并不具有说服性。
Double Cross Validation(2-fold Cross Validation,记为2-CV)
做法是将数据集分成两个相等大小的子集,进行两回合的分类器训练。在第一回合中,一个子集作为training set,另一个便作为testing set;在第二回合中,则将training set与testing set对换后,再次训练分类器,而其中我们比较关心的是两次testing sets的辨识率。不过在实务上2-CV并不常用,主要原因是training set样本数太少,通常不足以代表母体样本的分布,导致testing阶段辨识率容易出现明显落差。此外,2-CV中分子集的变异度大,往往无法达到“实 验过程必须可以被复制”的要求。
K-fold Cross Validation(K-折交叉验证,记为K-CV)
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证 集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取 2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
Leave-One-Out Cross Validation(记为LOO-CV)
如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模 型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。相比于前面的K-CV,LOO-CV有两个明显的优点:
(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。
—————————————————
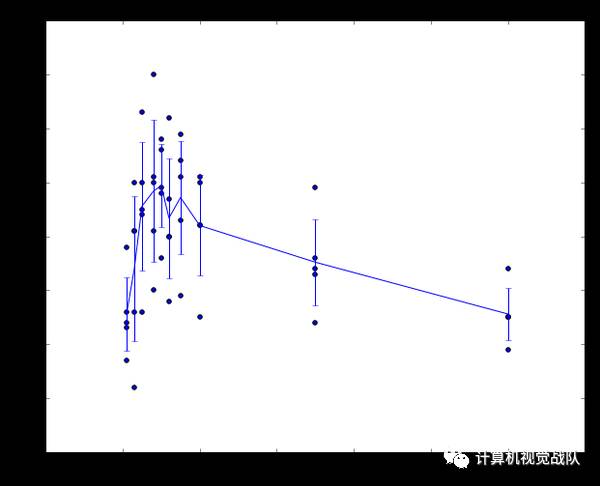
这就是5份交叉验证对k值调优的例子。针对每个k值,得到5个准确率结果,取其平均值,然后对不同k值的平均表现画线连接。本例中,当k=7的时算法表现最好(对应图中的准确率峰值)。如果我们将训练集分成更多份数,直线一般会更加平滑(噪音更少)。
—————————————————
实际应用。在实际情况下,人们不是很喜欢用交叉验证,主要是因为它会耗费较多的计算资源。一般直接把训练集按照50%-90%的比例分成训练集和验证集。但这也是根据具体情况来定的:如果超参数数量多,你可能就想用更大的验证集,而验证集的数量不够,那么最好还是用交叉验证吧。至于分成几份比较好,一般都是分成3、5和10份。
—————————————————

常用的数据分割模式。给出训练集和测试集后,训练集一般会被均分。这里是分成5份。前面4份用来训练,黄色那份用作验证集调优。如果采取交叉验证,那就各份轮流作为验证集。最后模型训练完毕,超参数都定好了,让模型跑一次(而且只跑一次)测试集,以此测试结果评价算法。
—————————————————
Nearest Neighbor分类器的优劣
现在对Nearest Neighbor分类器的优缺点进行思考。首先,Nearest Neighbor分类器易于理解,实现简单。其次,算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。然而测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较,这显然是一个缺点。在实际应用中,我们关注测试效率远远高于训练效率。其实,我们后续要学习的卷积神经网络在这个权衡上走到了另一个极端:虽然训练花费很多时间,但是一旦训练完成,对新的测试数据进行分类非常快。这样的模式就符合实际使用需求。
Nearest Neighbor分类器的计算复杂度研究是一个活跃的研究领域,若干Approximate Nearest Neighbor (ANN)算法和库的使用可以提升Nearest Neighbor分类器在数据上的计算速度(比如:FLANN)。这些算法可以在准确率和时空复杂度之间进行权衡,并通常依赖一个预处理/索引过程,这个过程中一般包含kd树的创建和k-means算法的运用。
Nearest Neighbor分类器在某些特定情况(比如数据维度较低)下,可能是不错的选择。但是在实际的图像分类工作中,很少使用。因为图像都是高维度数据(他们通常包含很多像素),而高维度向量之间的距离通常是反直觉的。下面的图片展示了基于像素的相似和基于感官的相似是有很大不同的:
—————————————————
在高维度数据上,基于像素的的距离和感官上的非常不同。上图中,右边3张图片和左边第1张原始图片的L2距离是一样的。很显然,基于像素比较的相似和感官上以及语义上的相似是不同的。
 在高维度数据上,基于像素的的距离和感官上的非常不同。上图中,右边3张图片和左边第1张原始图片的L2距离是一样的。很显然,基于像素比较的相似和感官上以及语义上的相似是不同的。
在高维度数据上,基于像素的的距离和感官上的非常不同。上图中,右边3张图片和左边第1张原始图片的L2距离是一样的。很显然,基于像素比较的相似和感官上以及语义上的相似是不同的。—————————————————
这里还有个视觉化证据,可以证明使用像素差异来比较图像是不够的。z这是一个叫做t-SNE的可视化技术,它将CIFAR-10中的图片按照二维方式排布,这样能很好展示图片之间的像素差异值。在这张图片中,排列相邻的图片L2距离就小。
—————————————————
上图使用t-SNE的可视化技术将CIFAR-10的图片进行了二维排列。排列相近的图片L2距离小。可以看出,图片的排列是被背景主导而不是图片语义内容本身主导。
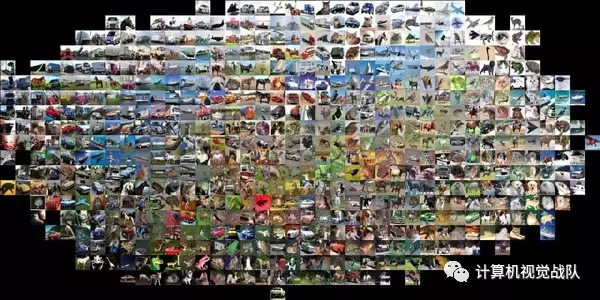 上图使用t-SNE的可视化技术将CIFAR-10的图片进行了二维排列。排列相近的图片L2距离小。可以看出,图片的排列是被背景主导而不是图片语义内容本身主导。
上图使用t-SNE的可视化技术将CIFAR-10的图片进行了二维排列。排列相近的图片L2距离小。可以看出,图片的排列是被背景主导而不是图片语义内容本身主导。—————————————————
具体说来,这些图片的排布更像是一种颜色分布函数,或者说是基于背景的,而不是图片的语义主体。比如,狗的图片可能和青蛙的图片非常接近,这是因为两张图片都是白色背景。从理想效果上来说,我们肯定是希望同类的图片能够聚集在一起,而不被背景或其他不相关因素干扰。为了达到这个目的,我们不能止步于原始像素比较,得继续前进。
小结
简要说来:
介绍了图像分类问题。在该问题中,给出一个由被标注了分类标签的图像组成的集合,要求算法能预测没有标签的图像的分类标签,并根据算法预测准确率进行评价。
介绍了一个简单的图像分类器:最近邻分类器(Nearest Neighbor classifier)。分类器中存在不同的超参数(比如k值或距离类型的选取),要想选取好的超参数不是一件轻而易举的事。
选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好那个。
如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最优超参数的时候减少噪音。
一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于耗费计算能力。
最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体分身。
在接下来的课程中,我们将专注于解决这些问题和挑战,并最终能够得到超过90%准确率的解决方案。该方案能够在完成学习就丢掉训练集,并在一毫秒之内就完成一张图片的分类。
小结:实际应用k-NN
如果你希望将k-NN分类器用到实处(最好别用到图像上,若是仅仅作为练手还可以接受),那么可以按照以下流程:
预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。在后面的小节我们会讨论这些细节。本小节不讨论,是因为图像中的像素都是同质的,不会表现出较大的差异分布,也就不需要标准化处理了。
如果数据是高维数据,考虑使用降维方法,比如PCA(wiki ref, CS229ref, blog ref)或随机投影。
将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集。这个比例根据算法中有多少超参数,以及这些超参数对于算法的预期影响来决定。如果需要预测的超参数很多,那么就应该使用更大的验证集来有效地估计它们。如果担心验证集数量不够,那么就尝试交叉验证方法。如果计算资源足够,使用交叉验证总是更加安全的(份数越多,效果越好,也更耗费计算资源)。
在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
如果分类器跑得太慢,尝试使用Approximate Nearest Neighbor库(比如FLANN)来加速这个过程,其代价是降低一些准确率。
对最优的超参数做记录。记录最优参数后,是否应该让使用最优参数的算法在完整的训练集上运行并再次训练呢?因为如果把验证集重新放回到训练集中(自然训练集的数据量就又变大了),有可能最优参数又会有所变化。在实践中,不要这样做。千万不要在最终的分类器中使用验证集数据,这样做会破坏对于最优参数的估计。直接使用测试集来测试用最优参数设置好的最优模型,得到测试集数据的分类准确率,并以此作为你的kNN分类器在该数据上的性能表现。
拓展阅读
下面是一些你可能感兴趣的拓展阅读链接:
A Few Useful Things to Know about Machine Learning,文中第6节与本节相关,但是整篇文章都强烈推荐。
Recognizing and Learning Object Categories,ICCV 2005上的一节关于物体分类的课程。
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!





