CVPR 2020 | 腾讯和南京大学提出:轻量级行为识别模型TEA
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文作者:木石
https://zhuanlan.zhihu.com/p/129282832
本文已由原作者授权,不得擅自二次转载

南京大学MCG group/腾讯PCG 提出可以进行用于时序建模的轻量级行为识别模型TEA
论文:https://arxiv.org/abs/2004.01398
代码(截至2020年4月19日,代码还没有挂出来):https://github.com/Phoenix1327/tea-action-recognition
Motivation
Motion feature 学习过程中存在的问题:
利用 optical flow 存储和计算的开销太大
现阶段的网络设计,spatio-temporal 建模 和Motion feature 建模分离
比如STM 直接 Add spatio temporal feature 和 motion encoding feature
TEA 的 ME 则利用了 Motion feature 做 channeI attention
过去的建模都 focus 在 frame-level motion,更好的建模方式 feature-level motion
长时建模存在的问题:
单帧过backbone,最后的feature 进行 temporal max/average pooling 做late fusion
stack Local 3D/(2+1)D 通过网络深度增加感受野来构建时序关系——会造成优化的困难
网络结构
TEA 由 ME和MTA两个模块构成:
motion excitation (ME) module
用于建模feature level的时序变化 short-range motion
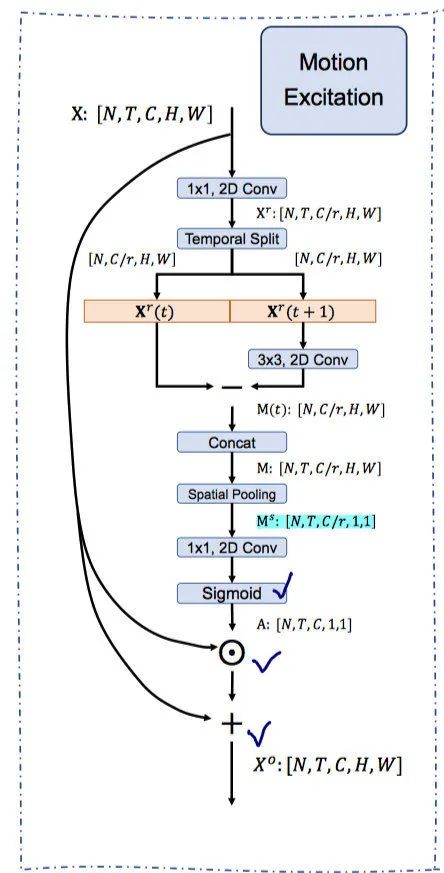
设计细节:
引入 reduction radio
,利用
卷积降低channel数量
参考STM,feature在时序上进行diff(相减)建模motion信息,其中利用了一个channel-wise的
卷积,可以match regions of the same object from contexts ,避免直接相减造成feature的dispalce,也可以理解为一种修正或者平滑的操作。
 ,利用
,利用  卷积降低channel数量
卷积降低channel数量 
 卷积,可以match regions of the same object from contexts ,避免直接相减造成feature的dispalce,也可以理解为一种修正或者平滑的操作。
卷积,可以match regions of the same object from contexts ,避免直接相减造成feature的dispalce,也可以理解为一种修正或者平滑的操作。 
When calculating feature-level motion representations in the ME module, we first apply a channel-wise transformation convolution on features at the time step t + 1. The reason is that motions will cause spatial displacements for the same objects between two frames, and it will result in mismatched motion representation to directly compute differences between displaced features. To address this issue, we add a 3×3 convolution at time step t + 1 attempting to capture the matched regions of the same object from contexts.
Moreover, we found that conducting transformation on both t and t + 1 time steps does not improve the performance but introduces more operations.
利用 motion-attentive weights A 对原始feature进行channel-attention,这里使用sigmoid function 作为激活函数。
相比于 SENet 增加一个residual connection 增强 motion information 同时保持 scene information(背景信息)不丢失,
表示 channel-wise multiplication.

 表示 channel-wise multiplication.
表示 channel-wise multiplication.
The useless channels will be completely suppressed in SENet, but the static background information can be preserved in our module by introducing a residual connection.

由上图可知,不同 channel的feature不同,motion-attention的操作会使用a large attention weight加强motion channel ,lower attention weight抑制background channel,
multiple temporal aggregation (MTA) module
用于进行 long-range temporal aggregation
stack Local 3D/(2+1)D 通过网络深度增加感受野来构建时序关系——会造成优化的困难
optimization message delivered from distant frames has been dramatically weakened and cannot be well handled.
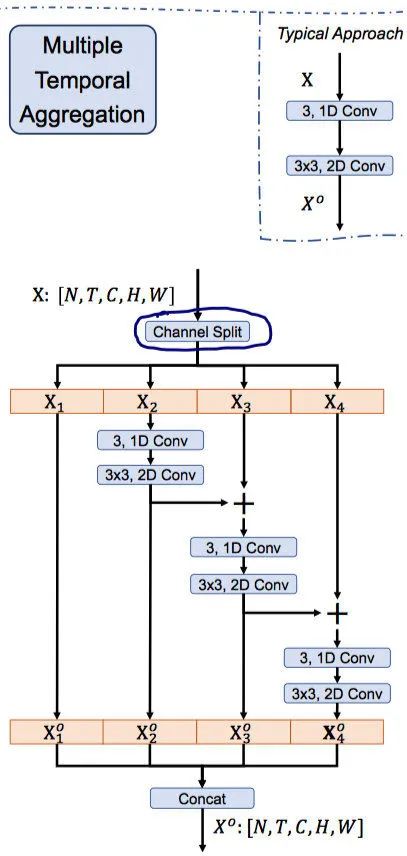
设计细节:
参考 Res2Net 进行设计,增加 group 、hierachical residual architecture 、cascade.
不增加参数、增加少量时间——来自于cascade结构,这种multiple stage的融合需要sequentially process
根据ablation study,纯Res2Net结构,只能对spatial的feature 进行建模,缺少temporal modeling,所以split the feature into four fragments along the channel dimension后,额外增加了一个 channel-wise 的
的时序卷积。注意进行 temporal convolution之前要先reshape
最后 concat feature

 的时序卷积。注意进行 temporal convolution之前要先reshape
的时序卷积。注意进行 temporal convolution之前要先reshape

TEA block
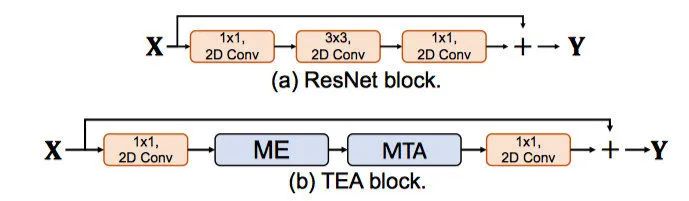
TEA block 放在 later stage 效果更好,更能有效进行long-range temporal aggregation
Train/Test 细节
训练参数初始化:
2D spatial CNN kernel 采用 pre-trained on ImageNet dataset weight 进行初始化
1D temporal convolution 使用 pre-designed 的 part shift initialization strategy进行初始化:
shift 操作 参考TSM TSM中shift操作可以认为是一种特殊的1D conv 

FC 层的 lr 和 weight decay 设置为其他layer的5倍
HMDB-51 UCF-101 中的 BN 层除了第一层之外全部frozen
两种Inference模式:
1.efficient protocol:
1 clip with T frames is evenly sampled from the video,
resize to 256×256 ,
corner crop 224×224
2.accuracy protocol:
10 different clips are randomly sampled from the video
resize the shorter size to 256 with maintaining the aspect ratio
3 crops of 256×256
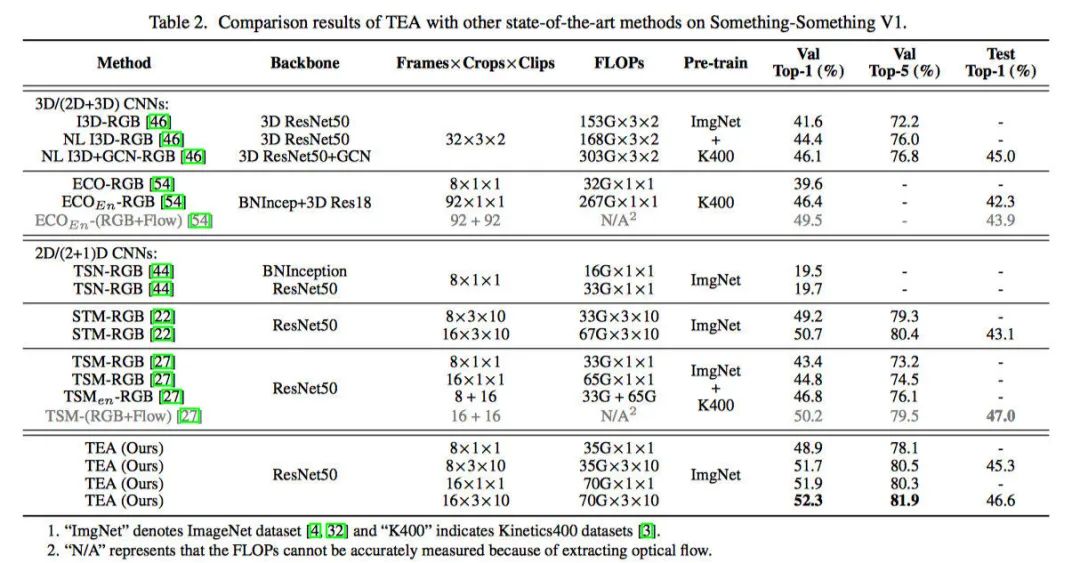
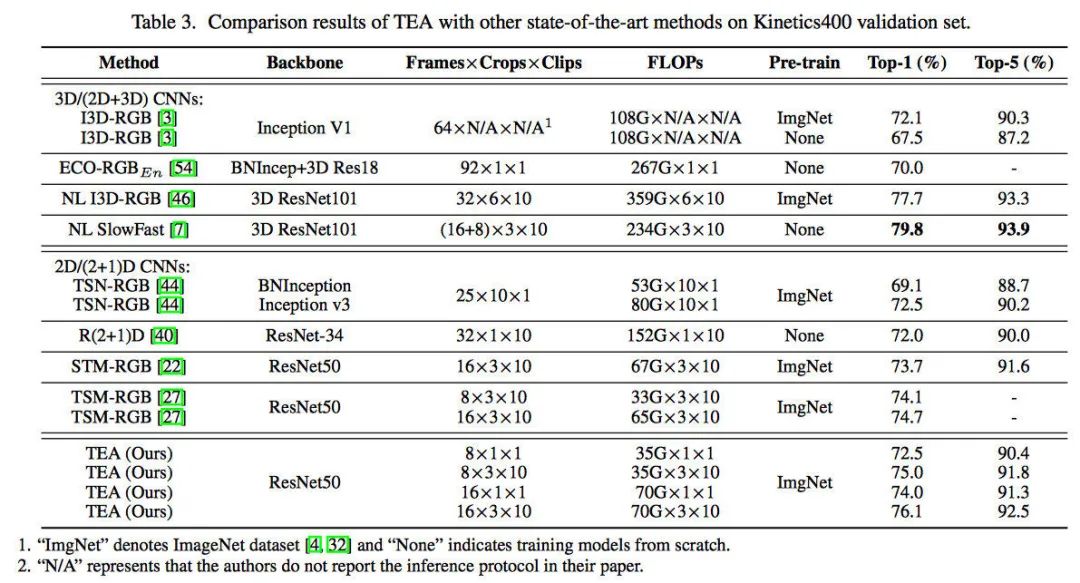
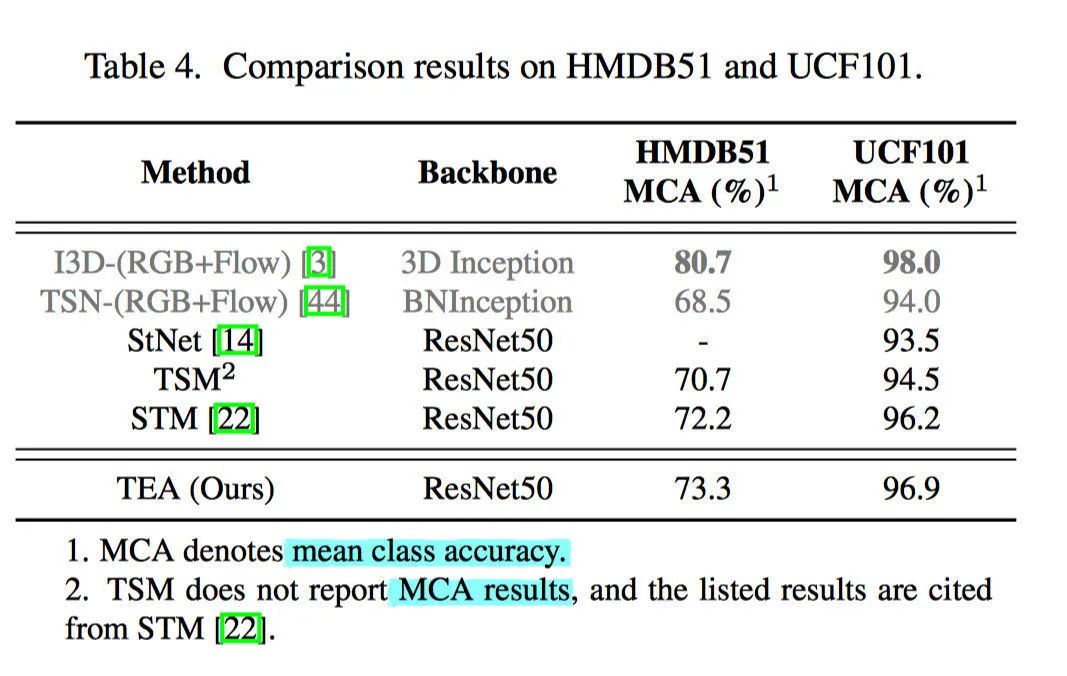
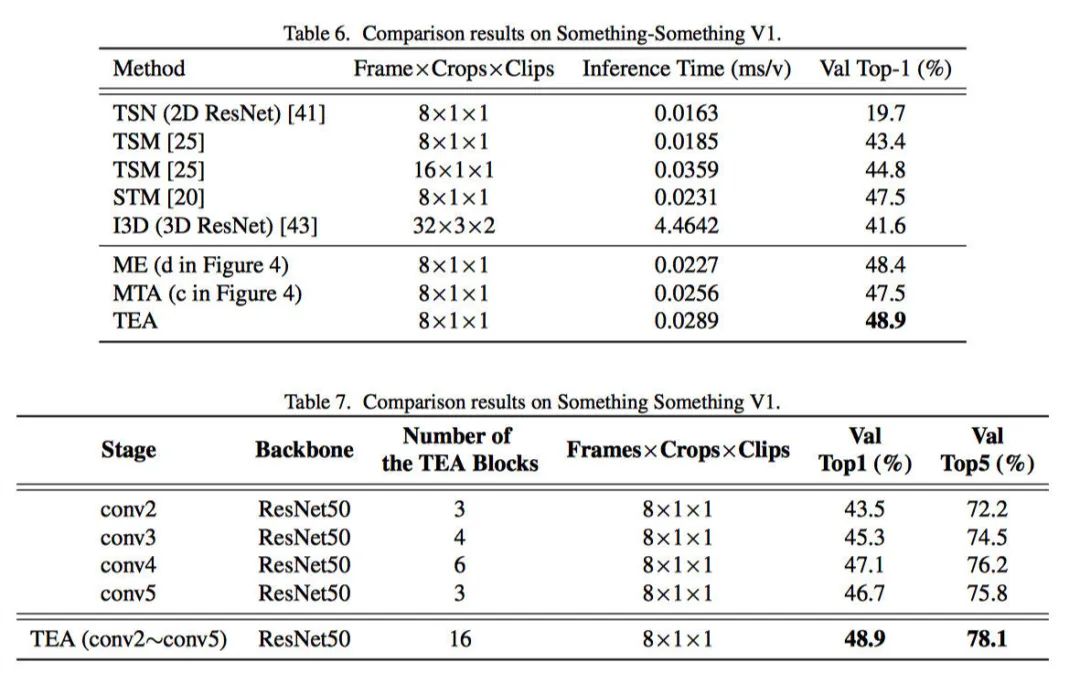
实验结果
论文下载
在CVer公众号后台回复:TEA,即可下载本论文
重磅!CVer-行为识别 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-行为识别 微信交流群
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如行为识别+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




