【导读】作为计算机视觉领域的三大国际顶会之一,IEEE国际计算机视觉与模式识别会议 CVPR 每年都会吸引全球领域众多专业人士参与。由于受COVID-19疫情影响,原定于6月16日至20日在华盛顿州西雅图举行的CVPR 2020将全部改为线上举行。今年的CVPR有6656篇有效投稿,最终有1470篇论文被接收,接收率为22%左右。之前小编为大家整理过CVPR 2020 GNN 相关论文,这周小编继续为大家整理了五篇CVPR 2020 图神经网络(GNN)相关论文,供大家参考——行为识别、少样本学习、仿射跳跃连接、多层GCN、3D视频目标检测。
CVPR2020SGNN、CVPR2020GNN_Part2、CVPR2020GNN_Part1、WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN
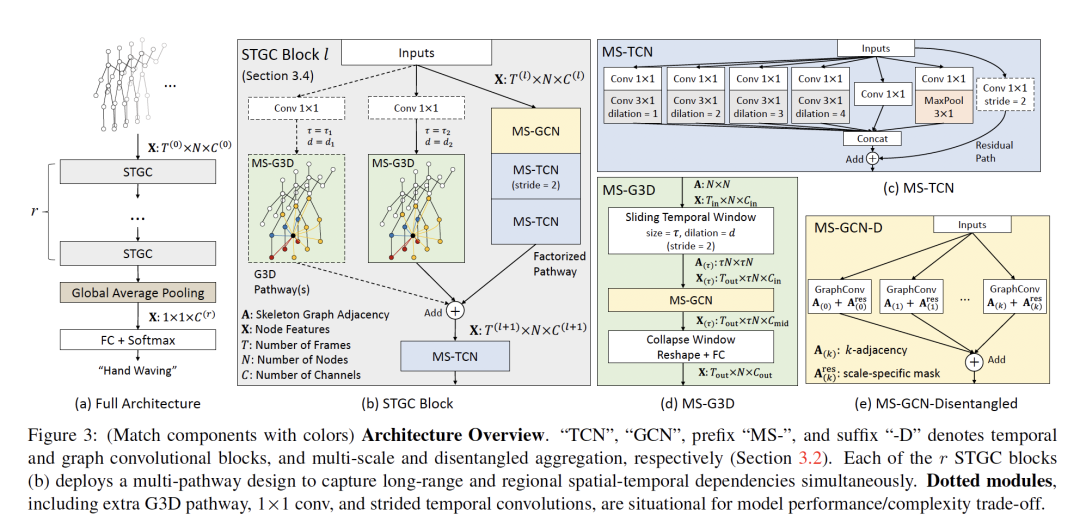
1. Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition
作者:Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, Wanli Ouyang
摘要:基于骨架的动作识别算法广泛使用时空图对人体动作动态进行建模。为了从这些图中捕获鲁棒的运动模式,长范围和多尺度的上下文聚合与时空依赖建模是一个强大的特征提取器的关键方面。然而,现有的方法在实现(1)多尺度算子下的无偏差长范围联合关系建模和(2)用于捕捉复杂时空依赖的通畅的跨时空信息流方面存在局限性。在这项工作中,我们提出了(1)一种简单的分解(disentangle)多尺度图卷积的方法和(2)一种统一的时空图卷积算子G3D。所提出的多尺度聚合方法理清了不同邻域中节点对于有效的远程建模的重要性。所提出的G3D模块利用密集的跨时空边作为跳过连接(skip connections),用于在时空图中直接传播信息。通过耦合上述提议,我们开发了一个名为MS-G3D的强大的特征提取器,在此基础上,我们的模型在三个大规模数据集NTU RGB+D60,NTU RGB+D120和Kinetics Skeleton 400上的性能优于以前的最先进方法。
网址: https://arxiv.org/pdf/2003.14111.pdf
代码链接: github.com/kenziyuliu/ms-g3d
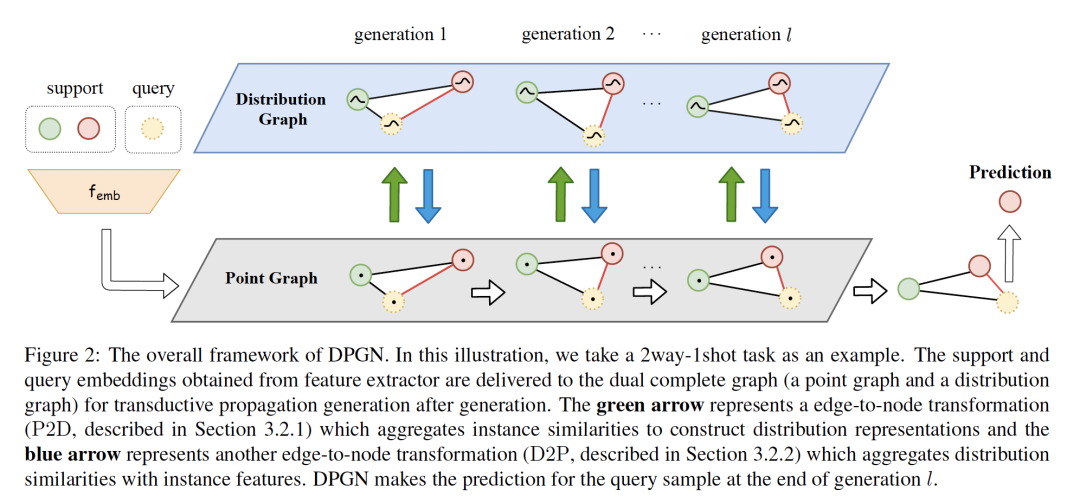
2. DPGN: Distribution Propagation Graph Network for Few-shot Learning
作者:Ling Yang, Liangliang Li, Zilun Zhang, Xinyu Zhou, Erjin Zhou, Yu Liu
摘要:大多数基于图网络的元学习方法都是为实例的instance-level关系进行建模。我们进一步扩展了此思想,以1-vs-N的方式将一个实例与所有其他实例的分布级关系明确建模。我们提出了一种新的少样本学习方法--分布传播图网络(DPGN)。它既表达了每个少样本学习任务中的分布层次关系,又表达了实例层次关系。为了将所有实例的分布层关系和实例层关系结合起来,我们构造了一个由点图和分布图组成的对偶全图网络,其中每个节点代表一个实例。DPGN采用双图结构,在更新时间内将标签信息从带标签的实例传播到未带标签的实例。在少样本学习的大量基准实验中,DPGN在监督设置下以5%∼12%和在半监督设置下以7%∼13%的优势大大超过了最新的结果。
网址: https://arxiv.org/pdf/2003.14247.pdf
代码链接: https://github.com/megvii-research/DPGN
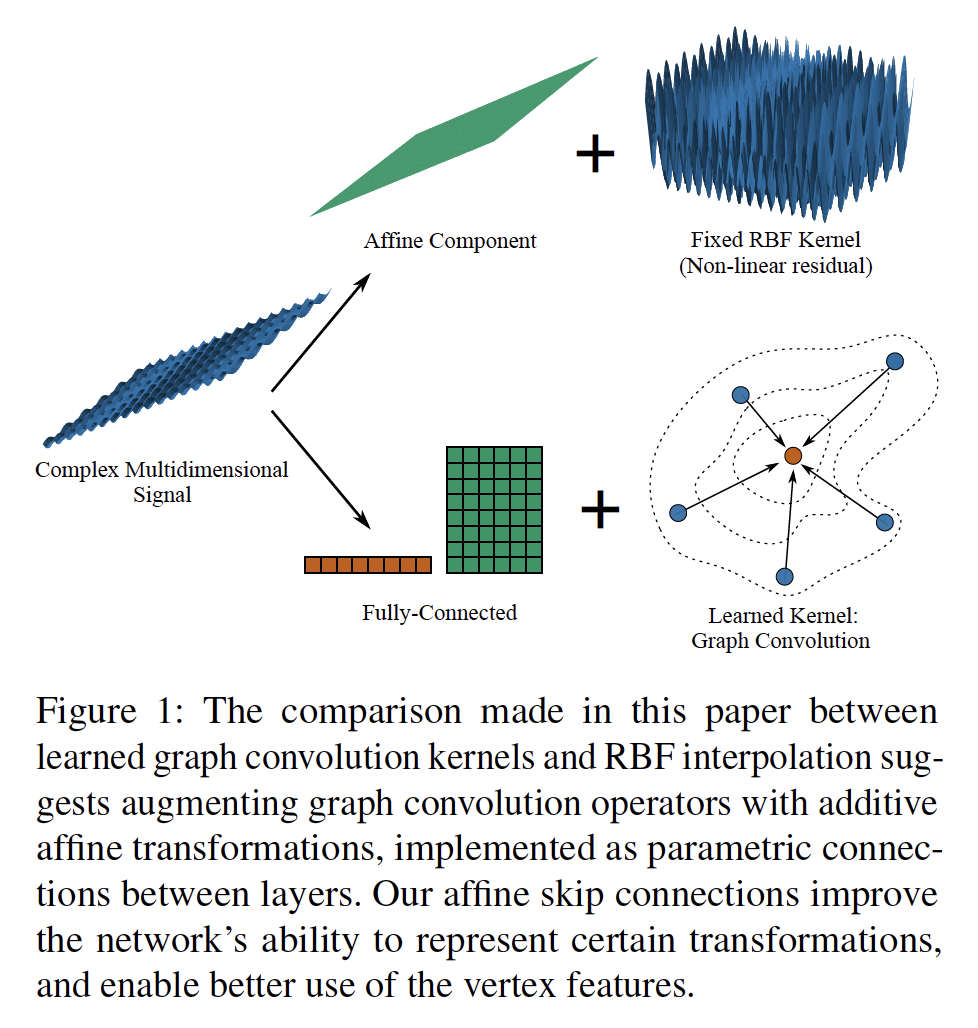
3. Geometrically Principled Connections in Graph Neural Networks
作者:Shunwang Gong, Mehdi Bahri, Michael M. Bronstein, Stefanos Zafeiriou
摘要:图卷积操作为以前认为遥不可及的各种图形和网格处理任务带来了深度学习的优势。随着他们的持续成功,人们希望设计更强大的体系结构,这通常是将现有的深度学习技术应用于非欧几里得数据。在这篇文章中,我们认为几何应该仍然是几何深度学习这一新兴领域创新的主要驱动力。我们将图神经网络与广泛成功的计算机图形和数据近似模型(径向基函数(RBF))相关联。我们推测,与RBF一样,图卷积层将从向功能强大的卷积核中添加简单函数中受益。我们引入了仿射跳跃连接 (affine skip connections),这是一种通过将全连接层与任意图卷积算子相结合而形成的一种新的构建块。通过实验证明了我们的技术的有效性,并表明性能的提高是参数数量增加的结果。采用仿射跳跃连接的算子在形状重建、密集形状对应和图形分类等每一项任务上的表现都明显优于它们的基本性能。我们希望我们简单有效的方法将成为坚实的基准,并有助于简化图神经网络未来的研究。
网址: https://arxiv.org/pdf/2004.02658.pdf
4. L^2-GCN: Layer-Wise and Learned Efficient Training of Graph Convolutional Networks
作者:Yuning You, Tianlong Chen, Zhangyang Wang, Yang Shen
摘要:图卷积网络(GCN)在许多应用中越来越受欢迎,但在大型图形数据集上的训练仍然是出了名的困难。它们需要递归地计算邻居的节点表示。当前的GCN训练算法要么存在随层数呈指数增长的高计算成本,要么存在加载整个图和节点嵌入的高内存使用率问题。本文提出了一种新的高效的GCN分层训练框架(L-GCN),该框架将训练过程中的特征聚合和特征变换分离开来,从而大大降低了时间和存储复杂度。我们在图同构框架下给出了L-GCN的理论分析,在温和的条件下,与代价更高的传统训练算法相比L-GCN可以产生同样强大的GCN。我们进一步提出了L2-GCN,它为每一层学习一个控制器,该控制器可以自动调整L-GCN中每一层的训练周期。实验表明,L-GCN比现有技术快至少一个数量级,内存使用量的一致性不依赖于数据集的大小,同时保持了还不错的预测性能。通过学习控制器,L2-GCN可以将训练时间进一步减少一半。
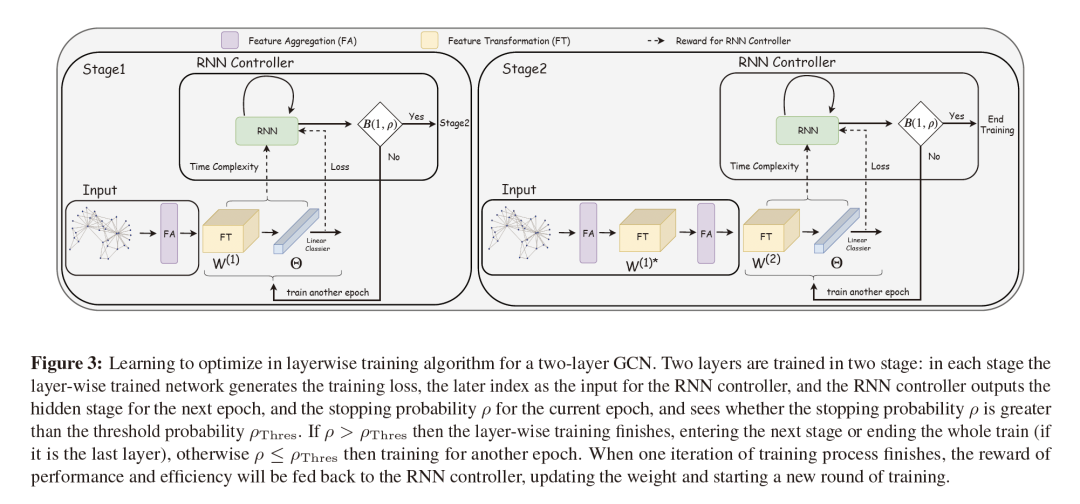
网址: https://arxiv.org/pdf/2003.13606.pdf
代码链接: https://github.com/Shen-Lab/L2-GCN
补充材料:
https://slack-files.com/TC7R2EBMJ-F012C60T335-281aabd097
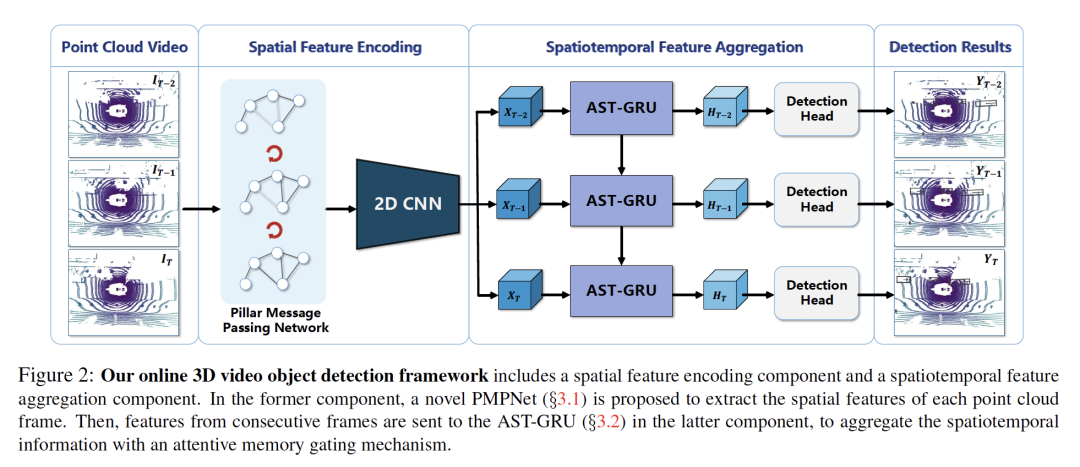
5. LiDAR-based Online 3D Video Object Detection with Graph-based Message Passing and Spatiotemporal Transformer Attention
作者:Junbo Yin, Jianbing Shen, Chenye Guan, Dingfu Zhou, Ruigang Yang
摘要:现有的基于LiDAR的3D目标检测算法通常侧重于单帧检测,而忽略了连续点云帧中的时空信息。本文提出了一种基于点云序列的端到端在线3D视频对象检测器。该模型包括空间特征编码部分和时空特征聚合部分。在前一个组件中,我们提出了一种新的柱状消息传递网络(Pillar Message Passing Network,PMPNet)来对每个离散点云帧进行编码。它通过迭代信息传递的方式自适应地从相邻节点收集柱节点的信息,有效地扩大了柱节点特征的感受野。在后一组件中,我们提出了一种注意力时空转换GRU(AST-GRU)来聚合时空信息,通过注意力记忆门控机制增强了传统的ConvGRU。AST-GRU包含一个空间Transformer Attention(STA)模块和一个时间Transformer Attention(TTA)模块,分别用于强调前景对象和对齐动态对象。实验结果表明,所提出的3D视频目标检测器在大规模的nuScenes基准测试中达到了最先进的性能。