MM'21 | 基于图卷积网络的视频人物社交关系图生成方法
01
引言
视频中人物的社交关系是视频理解的重要基础之一,它既可以帮助观众更好地理解视频内涵,也将支撑许多视频相关的应用,如视频标注、视频检索和视觉问答等。传统的方法主要分析可由视觉内容直接体现的空间或动作关系等,很少涉及到更高层的语义信息,如视频中人物社交关系图的生成。与此同时,现有的视频分析工作主要针对人工剪裁的富含语义的图片或短视频,但是在现实场景的长视频中,往往却包含着大量与人物关系无关的信息,不仅场景和人物频繁切换,社交关系的呈现方式也更为复杂。
先前,我们曾经讨论过视频人物对的关系识别问题(详见“让视频讲点儿“社交”:基于多模态协同表征的视频人物社交关系识别”一文)。然而众所周知,人物关系事实上并不是相互独立的,而是彼此关联并形成完整的社交关系网络的,而网络中的关系往往通过“三元闭包”关系而存在着相互佐证、相互强化的作用,但现有技术并没有充分利用这一信息。,因此往往难以取得令人满意的效果。
为此,我们提出基于图卷积网络的视频人物社交关系图生成方法,具体来说,我们首先整合了短期的多模态线索,包括视觉、文本和音频信息,通过图卷积技术为人物生成帧级子图。在处理视频级的聚合任务时,我们设计了一个端到端的框架,沿着时间轨迹聚合所有的帧级子图,形成一个全局的视频级人物社交关系图,其中包括多角色之间的各种社交关系。
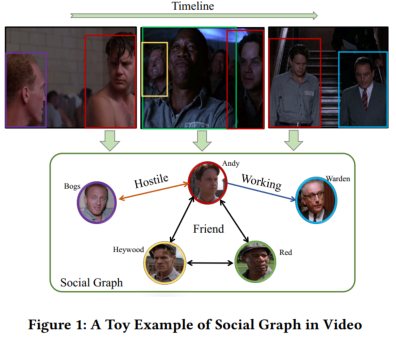
图1 视频社交关系图示例
本文工作由中国科学技术大学、优酷和京东硅谷研究中心三方联合完成。相关成果已被中国计算机学会推荐A类国际会议ACM MM 2021录用,论文信息如下:
论文标题:
Linking the Characters: Video-oriented Social Graph Generation via Hierarchical-cumulative GCN
论文作者:
Shiwei Wu, Joya Chen, Tong Xu, Liyi Chen, Lingfei Wu, Yao Hu, Enhong Chen
02
技术细节
2.1 问题描述
给定视频集
2.2 模型整体框架
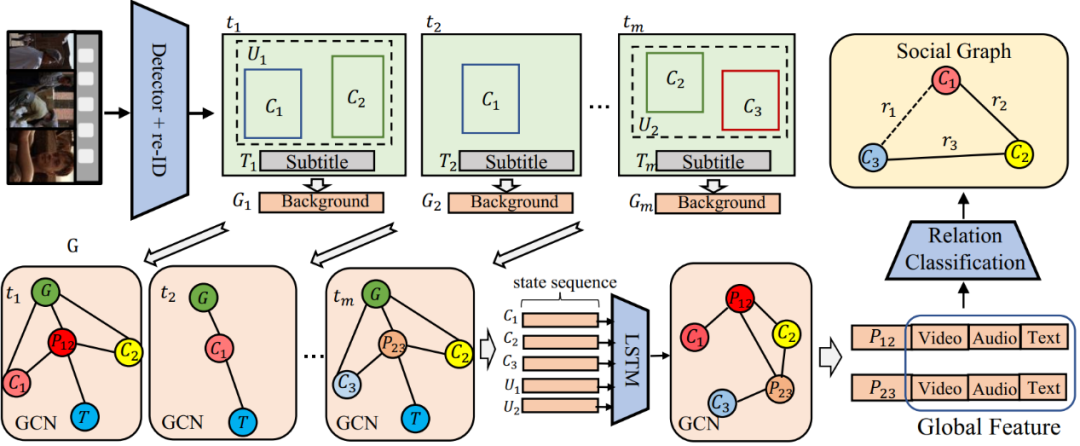
图2 模型整体框架
我们提出的人物社交关系图生成模型主要包括:帧级别的图卷积网络模块、多通道时序累积模块以及片段级别的图卷积网络模块。
2.3 帧级别的图卷积网络模块
在帧级别的图卷积网络模块中,目标是生成一个帧级别的子图,用来提供当前帧的人物社交关系图。主要过程如下:
首先,检测定位和重识别视频中的所有人物,我们使用人物角色框和联合框的视觉特征分别作为人物和人物对的表征。具体而言,采用预训练的残差网络从人物角色框和联合框的视觉特征中分别提取人物角色特征
其次,使用图卷积神经网络来相互传播节点的信息,从而在帧级别的子图上丰富人物和人物对之间的表征,单层的图卷积层的操作表示为:
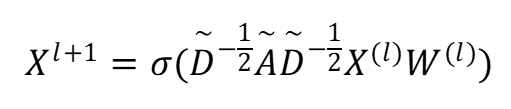
其中,
子图的邻接矩阵定义为:
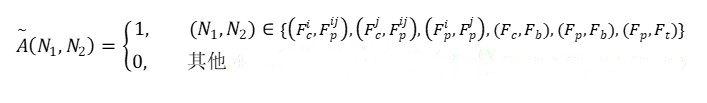
其中
最终,结合多视角的视觉特征
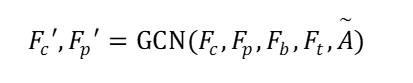
其中
2.4 多通道时序累积模块
对于每个人物特征
2.5 片段级别的图卷积网络模块
为了描述单个子视频帧序列(片段)
值得注意的是,片段级别的人物社交关系图
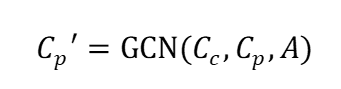
其中
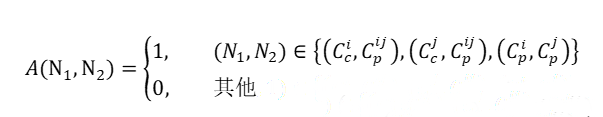
其中
2.6 基于弱监督学习的训练和测试方案。
对于一个视频来说,很难获得每一帧的人物级别标注。在这种情况下,我们应该只利用片段级别的社交关系标注来预测人物对的社交关系。为此,我们提出一个弱监督损失函数来解决这个具有挑战性的任务。
将片段级别的增强表征后的人物对特征输入至分类器,预测得到相应人物对在每个社交关系类别上的置信度向量,将所有人物对的置信度向量拼接起来组成分数矩阵Q;假设具有K对社交关系分数,R种社交关系以及P对人物,预测得到的分数矩阵Q形状为
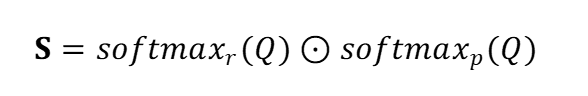
其中,
上式能够评估每个人物对关于每种社交关系的贡献。之后,可以累积每个人物对的置信度分数,用交叉熵准则来计算弱监督损失函数:
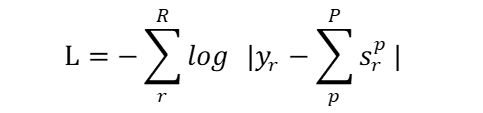
其中,
如上述介绍,在训练阶段,我们利用片段级别的增强表征后的人物对特征
在推理阶段,通过之前介绍的方式,得到片段级别的增强表征后的人物对特征
为了得到全局的人物社交关系图
03
实验
3.1 数据集
在数据方面,我们从BiliBili视频网站获取了70部电影,平均时长约1.9小时,我们选择了电影中的376个主要人物,进行了社交关系的标注。同时,还在基于视频的社交关系研究中常用的ViSR数据集上进行了实验。
3.2 实验结果
在自建的BiliBili电影数据集上,我们计算五分类的Recall、Precision和F1值来评估模型;在ViSR数据集上,根据每个社交关系的Top-1 Accuracy和整体的mAP来衡量模型的性能,整体实验结果如下表所示。可以发现,基于时序建模的模型(TSN-ST,MSTR,HC-GCN)结果显然好于基于图片的模型(GRM,DSC,MSFM,TEFM),这说明视频中人物社交关系的识别在很大程度上取决于时序信息。同时,我们的模型综合考虑了多种模态的信息,取得了比仅依赖视觉信息的模型更好的效果。
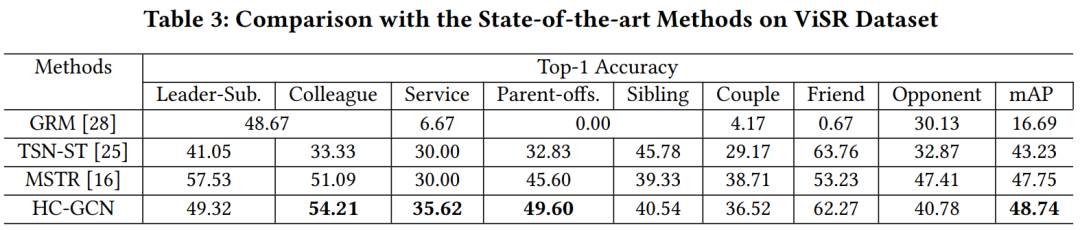
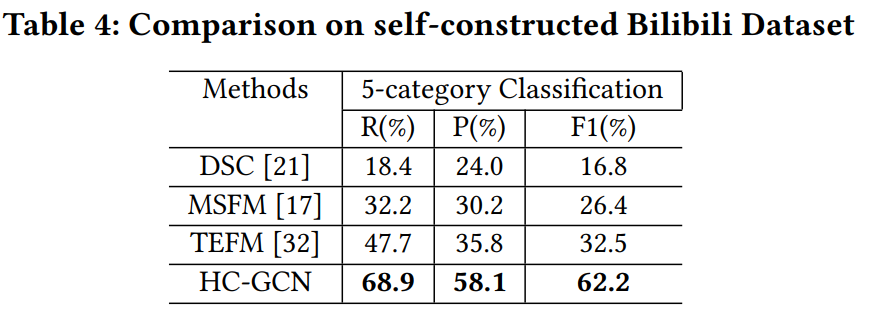
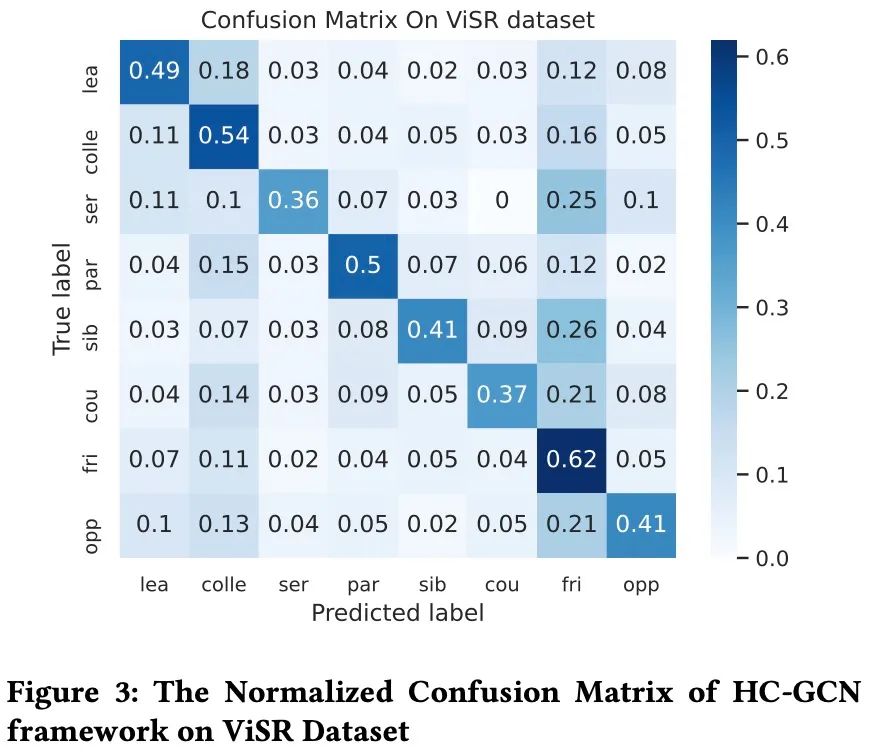
从实验结果中可以发现,我们的模型在敌对关系类别的Top1-准确率指标上并没有明显优势,这可能是因为敌对关系中的角色在电影中没有太多的互动和交流,从而影响了模型性能。相反,我们的方法在亲密的关系中表现得很好,例如,Colleague,Service,Parent-offs,Sibling,Couple和Friend。此外,我们在ViSR数据集上的实验混淆矩阵表明,模型可能会在亲密关系(如Friend、Sibling和Couple)之间判断出错。这是因为属于这些社交关系的角色在他们的活动和对话中往往有相似之处。
3.3 消融实验
同时,为了进一步检验我们模型图网络建模部分的有效性,我们做了如下对比实验,包括仅用视频(Global Video)和仅利用多模态信息(Global(Video+Text+Audio))进行社交关系分类,实验结果如下表所示。
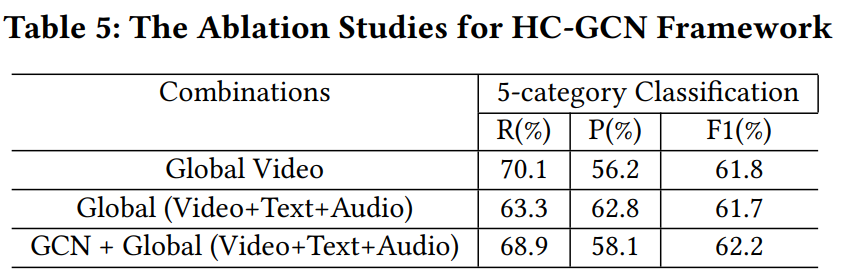
实验结果证明了我们的HC-GCN模型的有效性,同时,也印证了通过社交关系图生成方式来建模社交关系识别任务是一条可以探索的途径。



