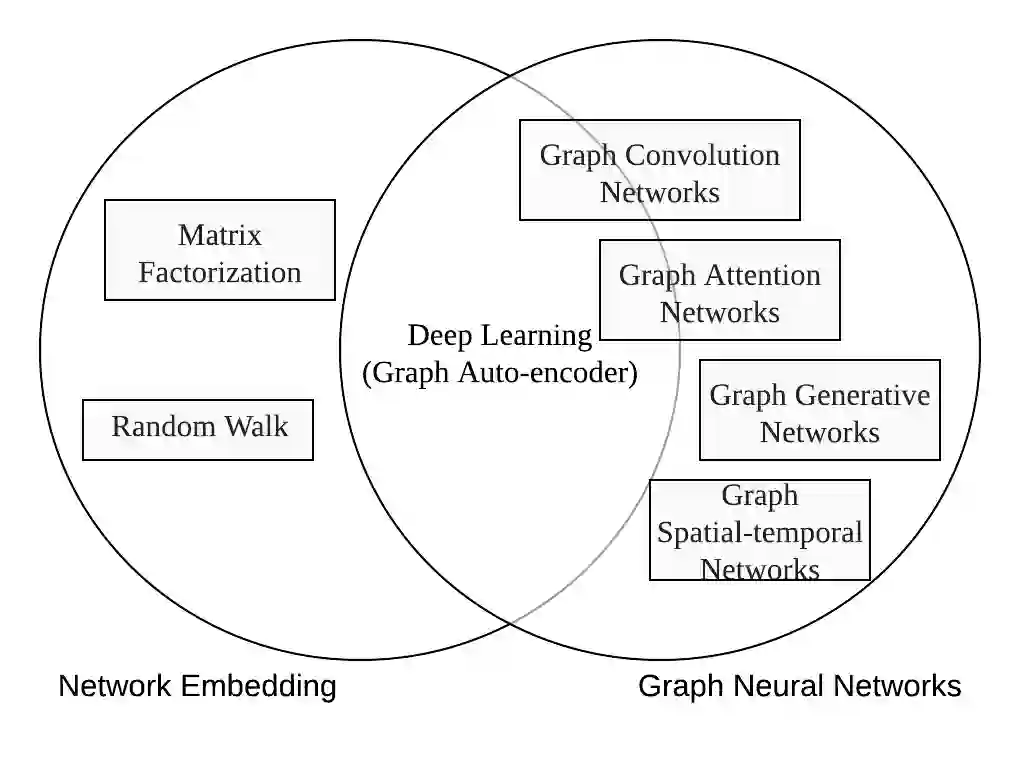
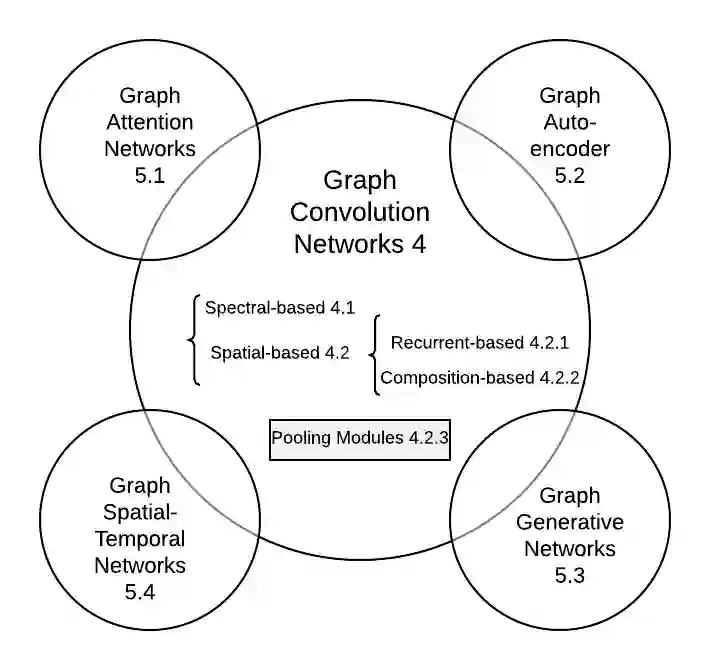
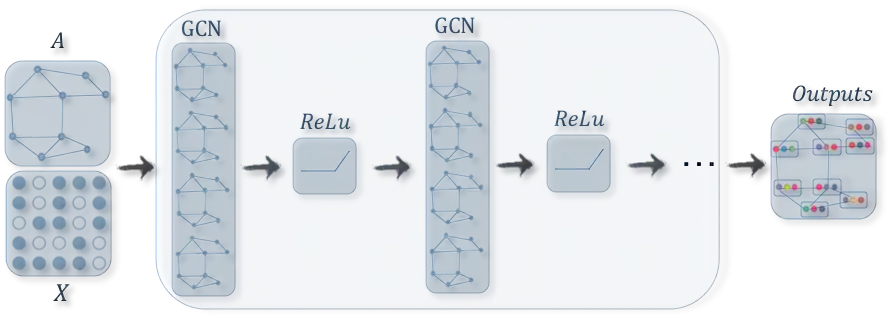
Deep learning has revolutionized many machine learning tasks in recent years, ranging from image classification and video processing to speech recognition and natural language understanding. The data in these tasks are typically represented in the Euclidean space. However, there is an increasing number of applications where data are generated from non-Euclidean domains and are represented as graphs with complex relationships and interdependency between objects. The complexity of graph data has imposed significant challenges on existing machine learning algorithms. Recently, many studies on extending deep learning approaches for graph data have emerged. In this survey, we provide a comprehensive overview of graph neural networks (GNNs) in data mining and machine learning fields. We propose a new taxonomy to divide the state-of-the-art graph neural networks into different categories. With a focus on graph convolutional networks, we review alternative architectures that have recently been developed; these learning paradigms include graph attention networks, graph autoencoders, graph generative networks, and graph spatial-temporal networks. We further discuss the applications of graph neural networks across various domains and summarize the open source codes and benchmarks of the existing algorithms on different learning tasks. Finally, we propose potential research directions in this fast-growing field.
翻译:近年来,深层学习使许多机器学习任务发生了革命性的变化,从图像分类和视频处理到语音识别和自然语言理解等,从图像分类和视频处理到语音识别和自然语言理解等,这些任务中的数据通常在欧几里德空间中呈现。然而,越来越多的应用应用中,数据来自非欧几里德域,并被作为具有复杂关系和天体间相互依存关系的图表来呈现。图表数据的复杂性给现有机器学习算法带来了重大挑战。最近,出现了许多关于扩大图形数据深度学习方法的研究。在本次调查中,我们提供了数据挖掘和机器学习领域的图形神经网络(GNN)的全面概览。我们提出了将最新图形神经网络分为不同类别的新分类学。我们以图形革命网络为重点,审查了最近开发的替代结构;这些学习范式包括图形关注网络、图形自动显示器、图形组合组合网络和图表空间时空网络。我们进一步讨论了各个域的图形神经网络应用,并总结了当前快速研究方向的开放源代码和基准。最后,我们提出了关于快速研究的实地研究方向。