
【导读】计算机视觉顶会CVPR 2020在不久前公布了论文接收列表。本届CVPR共收到了6656篇有效投稿,接收1470篇,其接受率在逐年下降,今年接受率仅为22%。近期,一些Paper放出来,专知小编整理了CVPR 2020 图神经网络(GNN)相关的比较有意思的值得阅读的五篇论文,供大家参考—点云分析、视频描述生成、轨迹预测、场景图生成、视频理解等。
1. Grid-GCN for Fast and Scalable Point Cloud Learning
作者:Qiangeng Xu, Xudong Sun, Cho-Ying Wu, Panqu Wang and Ulrich Neumann
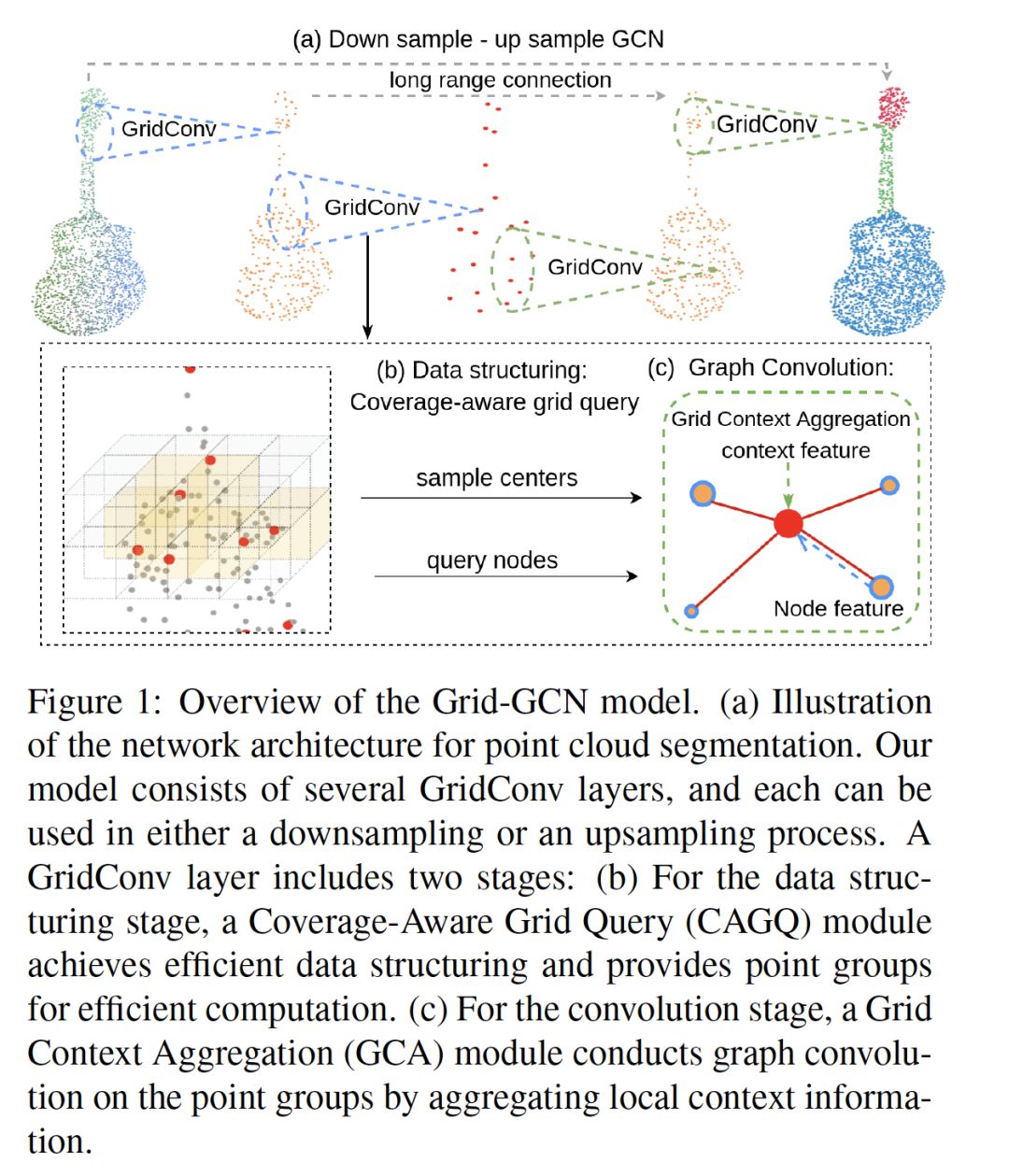
摘要:由于点云数据的稀疏性和不规则性,越来越多的方法直接使用点云数据。在所有基于point的模型中,图卷积网络(GCN)通过完全保留数据粒度和利用点间的相互关系表现出显著的性能。然而,基于点的网络在数据结构化(例如,最远点采样(FPS)和邻接点查询)上花费了大量的时间,限制了其速度和可扩展性。本文提出了一种快速、可扩展的点云学习方法--Grid-GCN。Grid-GCN采用了一种新颖的数据结构策略--Coverage-Aware Grid Query(CAGQ)。通过利用网格空间的效率,CAGQ在降低理论时间复杂度的同时提高了空间覆盖率。与最远的点采样(FPS)和Ball Query等流行的采样方法相比,CAGQ的速度提高了50倍。通过网格上下文聚合(GCA)模块,Grid-GCN在主要点云分类和分割基准上实现了最先进的性能,并且运行时间比以前的方法快得多。值得注意的是,在每个场景81920个点的情况下,Grid-GCN在ScanNet上的推理速度达到了50fps。
2. Object Relational Graph with Teacher-Recommended Learning for Video Captioning
作者:Ziqi Zhang, Yaya Shi, Chunfeng Yuan, Bing Li, Peijin Wang, Weiming Hu and Zhengjun Zha
摘要:充分利用视觉和语言的信息对于视频字幕任务至关重要。现有的模型由于忽视了目标之间的交互而缺乏足够的视觉表示,并且由于长尾(long-tailed)问题而对与内容相关的词缺乏足够的训练。在本文中,我们提出了一个完整的视频字幕系统,包括一种新的模型和一种有效的训练策略。具体地说,我们提出了一种基于目标关系图(ORG)的编码器,该编码器捕获了更详细的交互特征,以丰富视觉表示。同时,我们设计了一种老师推荐学习(Teacher-Recommended Learning, TRL)的方法,充分利用成功的外部语言模型(ELM)将丰富的语言知识整合到字幕模型中。ELM生成了在语义上更相似的单词,这些单词扩展了用于训练的真实单词,以解决长尾问题。 对三个基准MSVD,MSR-VTT和VATEX进行的实验评估表明,所提出的ORG-TRL系统达到了最先进的性能。 广泛的消去研究和可视化说明了我们系统的有效性。

3. Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction
作者:Abduallah Mohamed and Kun Qian
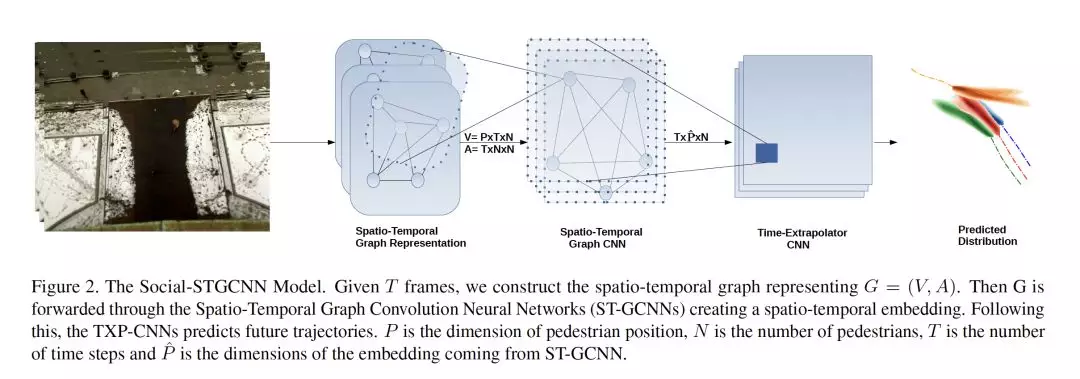
摘要:有了更好地了解行人行为的机器可以更快地建模智能体(如:自动驾驶汽车)和人类之间的特征交互。行人的运动轨迹不仅受行人自身的影响,还受与周围物体相互作用的影响。以前的方法通过使用各种聚合方法(整合了不同的被学习的行人状态)对这些交互进行建模。我们提出了社交-时空图卷积神经网络(Social-STGCNN),它通过将交互建模为图来代替聚合方法。结果表明,最终位偏误差(FDE)比现有方法提高了20%,平均偏移误差(ADE)提高了8.5倍,推理速度提高了48倍。此外,我们的模型是数据高效的,在只有20%的训练数据上ADE度量超过了以前的技术。我们提出了一个核函数来将行人之间的社会交互嵌入到邻接矩阵中。通过定性分析,我们的模型继承了行人轨迹之间可以预期的社会行为。
代码链接:
https://github.com/abduallahmohamed/Social-STGCNN
4. Unbiased Scene Graph Generation from Biased Training
作者:Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi and Hanwang Zhang
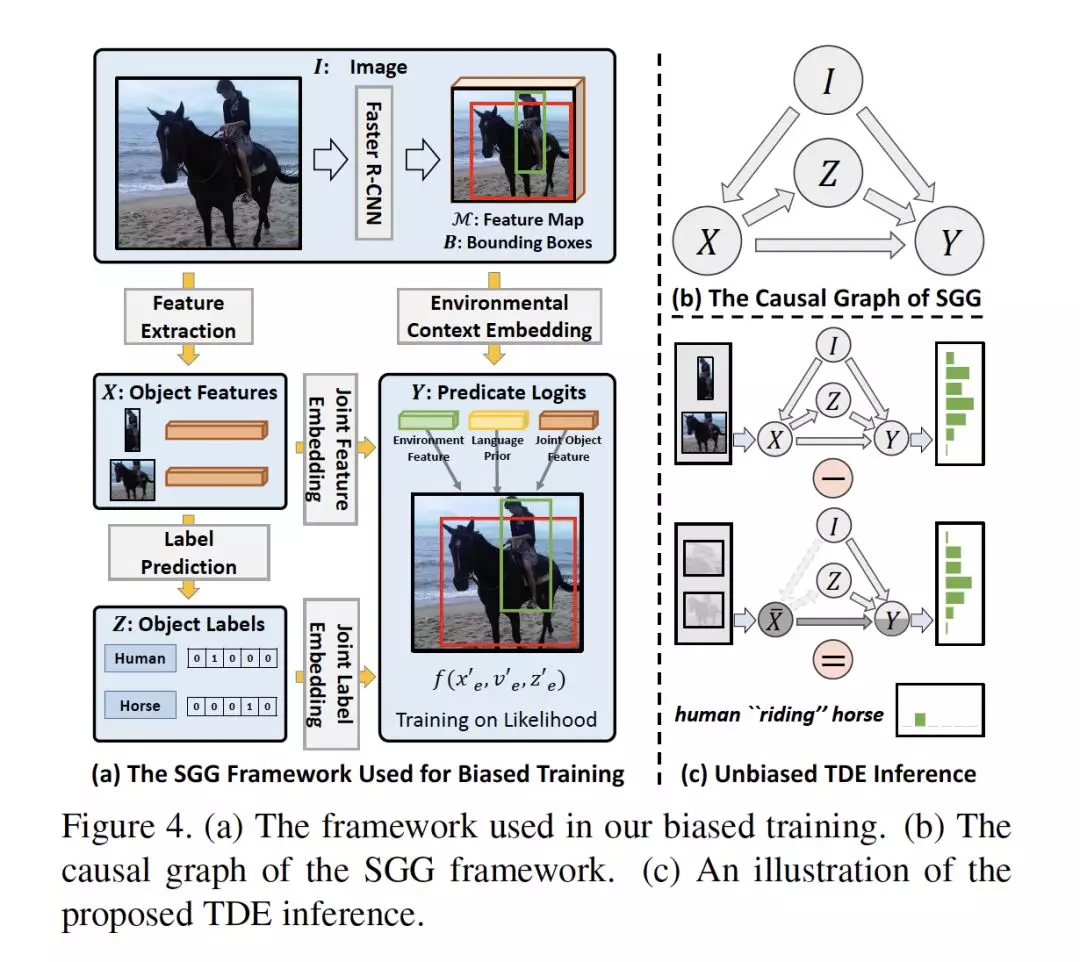
摘要:由于严重的训练偏差,场景图生成(SGG)的任务仍然不够实际,例如,将海滩上的各种步行/坐在/躺下的人简化为海滩上的人。基于这样的SGG,VQA等下游任务很难推断出比一系列对象更好的场景结构。然而,SGG中的debiasing 是非常重要的,因为传统的去偏差方法不能区分好的和不好的偏差,例如,好的上下文先验(例如,人看书而不是吃东西)和坏的长尾偏差(例如,将在后面/前面简化为邻近)。与传统的传统的似然推理不同,在本文中,我们提出了一种新的基于因果推理的SGG框架。我们首先为SGG建立因果关系图,然后用该因果关系图进行传统的有偏差训练。然后,我们提出从训练好的图中提取反事实因果关系(counterfactual causality),以推断应该被去除的不良偏差的影响。我们使用Total Direct Effect作为无偏差SGG的最终分数。我们的框架对任何SGG模型都是不可知的,因此可以在寻求无偏差预测的社区中广泛应用。通过在SGG基准Visual Genome上使用我们提出的场景图诊断工具包和几种流行的模型,与以前的最新方法相比有显著提升。
代码链接:
https://github.com/KaihuaTang/Scene-Graph-Benchmark.pytorch
5. Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences
作者:Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu and Lianli Gao
摘要:在本文中,我们考虑了一项用于多形式句子(Multi-Form Sentences)的时空Video Grounding(STVG)的任务。 即在给定未剪辑的视频和描述对象的陈述句/疑问句,STVG旨在定位所查询目标的时空管道(tube)。STVG有两个具有挑战性的设置:(1)我们需要从未剪辑的视频中定位时空对象管道,但是对象可能只存在于视频的一小段中;(2)我们需要处理多种形式的句子,包括带有显式宾语的陈述句和带有未知宾语的疑问句。 由于无效的管道预生成和缺乏对象关系建模,现有方法无法解决STVG任务。为此,我们提出了一种新颖的时空图推理网络(STGRN)。首先,我们构建时空区域图来捕捉具有时间对象动力学的区域关系,包括每帧内的隐式、显式空间子图和跨帧的时间动态子图。然后,我们将文本线索加入到图中,并开发了多步跨模态图推理。接下来,我们引入了一种具有动态选择方法的时空定位器,该定位器可以直接检索时空管道,而不需要预先生成管道。此外,我们在视频关系数据集Vidor的基础上构建了一个大规模的video grounding数据集VidSTG。大量的实验证明了该方法的有效性。
 网址:
网址:
