【干货分享】文本分类Keras教程
【导读】 这个例子展示了如何从原始文本(utf-8字符的字符串)开始进行文本分类。我们演示了IMDB情感分类数据集(未经处理的版本)的工作流程。我们使用文本矢量化层进行分词和索引。
Setup

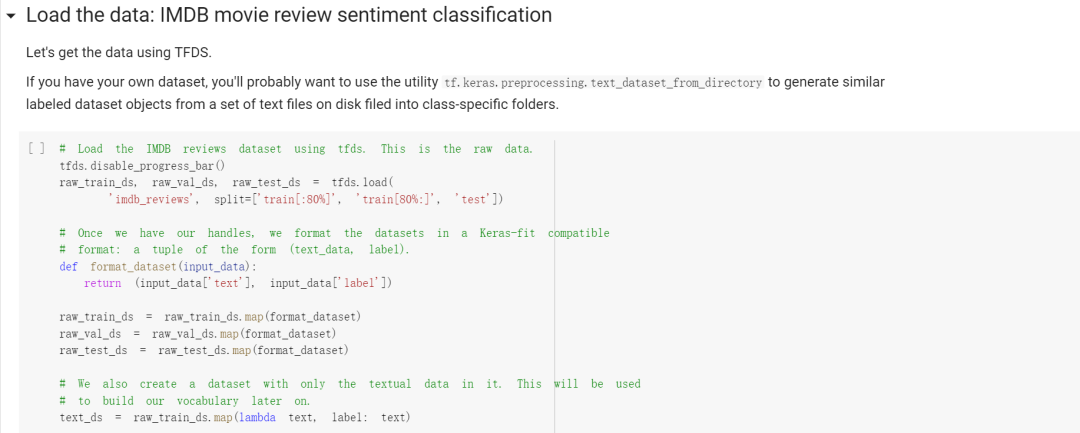
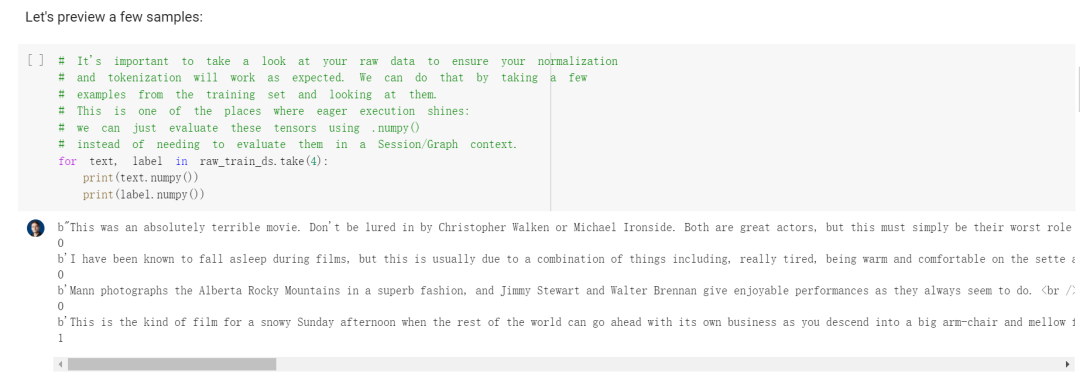
Load the data
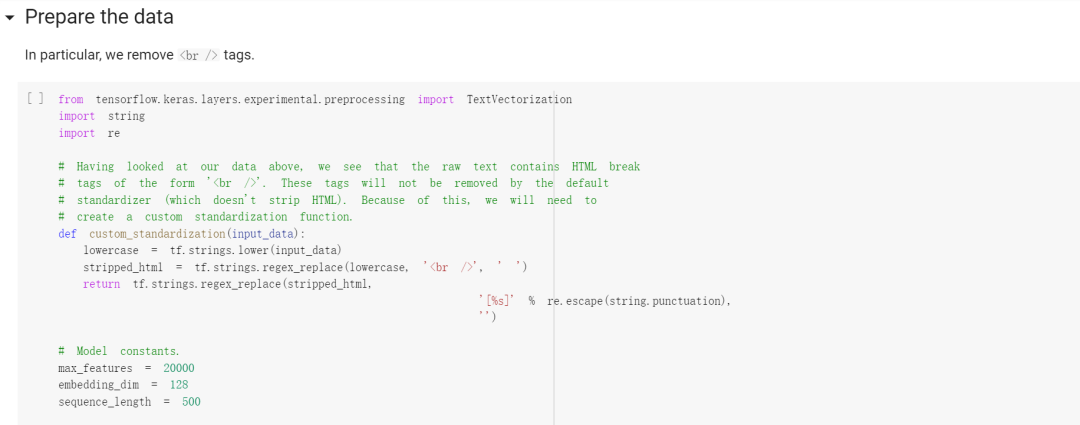
Prepare the data

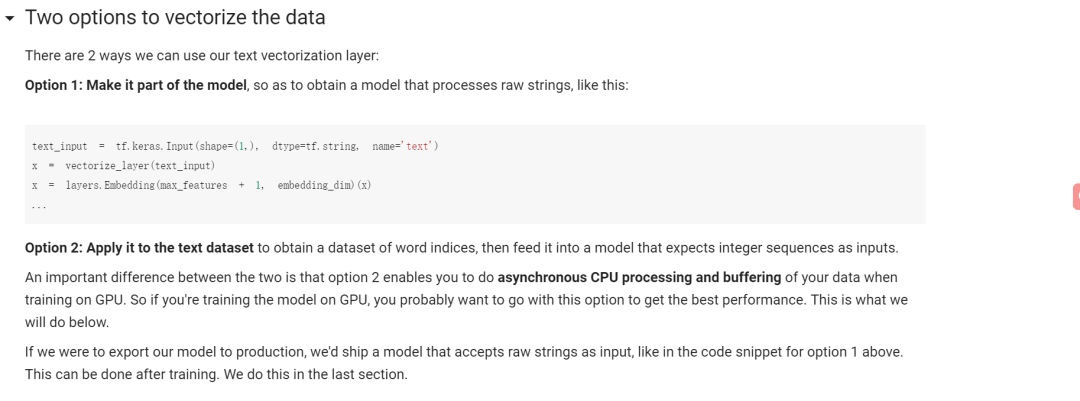
Two options to vectorize the data


Train the model
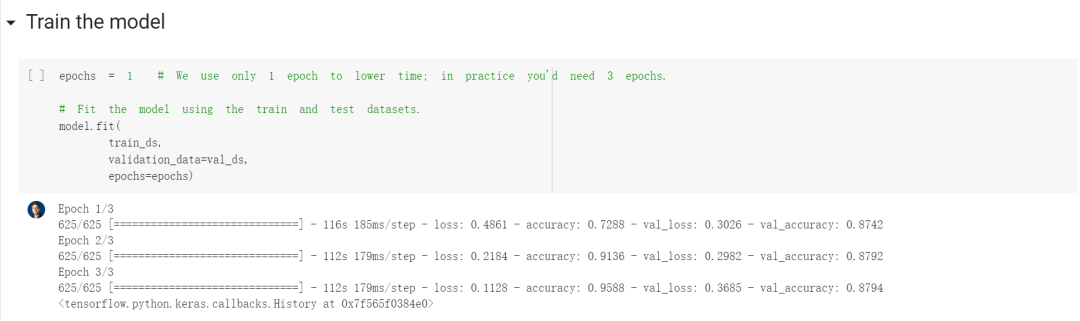
Evaluate the model on the test set

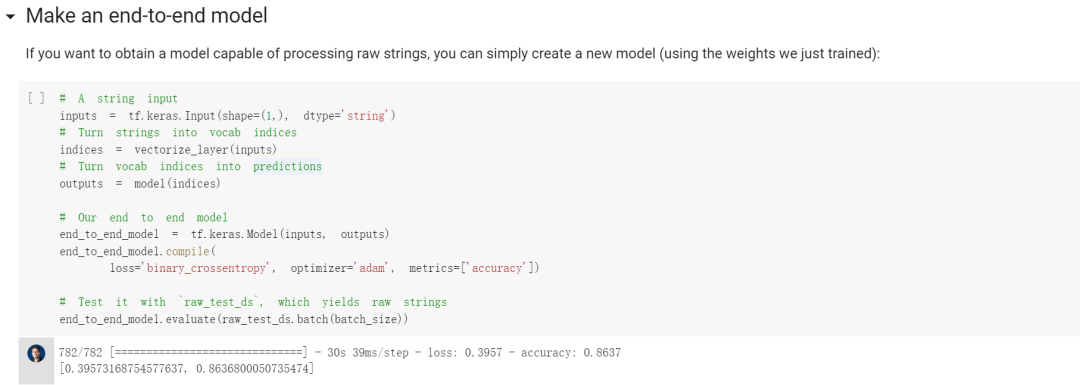
Make an end-to-end model
地址连接:
https://colab.research.google.com/drive/1XcMJqKcTLjduIqjysRd1jGdRaKdetc3X



登录查看更多
相关内容






相关VIP内容
相关资讯
相关论文