人工神经网络
斯蒂文的老板是一位高管层,他也知道现在人们都在讨论机器学习和深度学习,好像不谈这个就跟不上时代的潮流一样。有天他突然想了解神经网络,但是他不懂其细节,因此期望斯蒂文能像对小学生或者吉娃娃一样对他讲懂神经网络。
老板

什么是神经网络 (neural network)?
斯蒂文
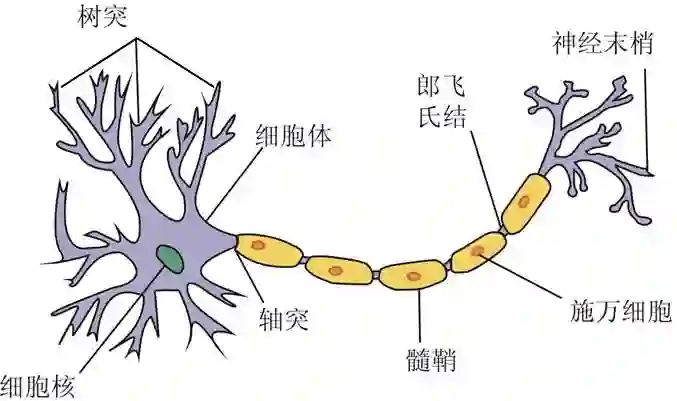
神经网络就是由神经元 (neuron) 组成的系统,而神经元如下图。

老板
你在耍我?我是说机器学习里面的神经网络,即人工神经网络 (artificial neural network, ANN )!
斯蒂文
吉娃娃是听不懂 ANN 的,必须要从生物层面谈起!必须从神经元谈起。
老板
请继续你的表演。
斯蒂文
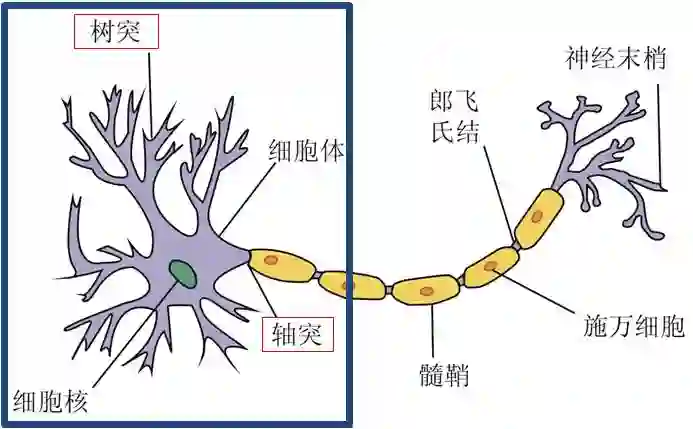
我不是生物专家,我就只把神经元里和 ANN 最相关的功能告诉你。如下图蓝框部分,神经元有许多树突(dendrite) 用于输入 (input),有一个轴突 (axon) 用于输出 (output)。
老板
这只是一个神经细胞,它们怎么形成一个网络呢?
斯蒂文
神经元具有两个最主要的特性:兴奋性和传导性。兴奋性是指当刺激强度未达到某一阈限值时,神经冲动不会发生;而当刺激强度达到该值时,神经冲动发生并能瞬时达到最大强度。传导性是指相邻神经元靠其间一小空隙进行传导。这一小空隙,叫做突触 (synapse),其作用在于传递不同神经元之间的神经冲动。如下图突触将神经元 A 和 B 连在一起,试想很多突触连接很多神经元,不就形成了一个神经网络了吗?

老板
现在我还能跟得上,那么 ANN 是怎么模仿神经网络这个机制呢?
斯蒂文
ANN 里面会用转换函数 (transfer function) 来模拟神经冲动;会用输入和输出来模拟树突和轴突做的事情;会用层 (layer) 来连接神经元使得“上一层神经元的输出经过转换函数变成下一层神经元的输入”。
本帖会介绍 ANN 及其它在机器学习里的应用,只为启发学习它的兴趣。
第一章主要讲构成 ANN 的基本元素和它的种类
第二章举一个非常简单的 ANN 用来区分苹果和香蕉
第三到五章借用 Matlab 的 GUI 来看 ANN 在回归、分类和聚类和问题上的应用
本贴会有大量的图 (包括动图) ,而没有任何关于正向反向传播的复杂的数学推导和公式。在没有激发兴趣之前,公式给的越多吸收效果越差。
第一章 - ANN 基本元素
1.1 转换函数
1.2 单输入-单层-单输出
1.3 多输入-单层-单输出
1.4 多输入-单层-多输出
1.5 多输入-多层-多输出
第二章 - ANN 简单实操
2.1 Matlab 函数
2.2 具体实例
第三章 - ANN 之回归应用
3.1 玩转 GUI
3.2 玩弄 Code
第四章 - ANN 之分类应用
4.1 玩转 GUI
4.2 玩弄 Code
第五章 - ANN 之聚类应用
5.1 玩转 GUI
5.2 玩弄 Code
总结

在人工神经网络 (ANN) 世界里,层与层之间是靠转换函数 (transfer function) 连接的,而转换函数就是一种将输入 (input) 转成输出 (output) 的函数。下图总结了几乎所有 ANN 用到的转换函数。
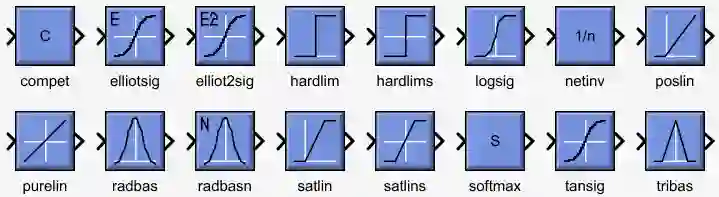
看着太乱是吗?那我们只关注 ANN 用的最多的转换函数,分别是 hardlim(), logsig() 和 purelin() 函数。以下例子用 w 代表权重,b 代表偏差 (下节会详细介绍)。
purelin() 函数
顾名思义,purelin() 代表 pure linear,就是线性函数 (linear function),它用于解决回归问题,如下图所示:
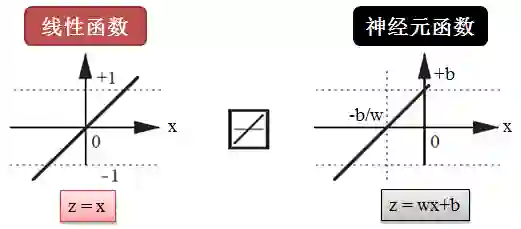
最简单的线性函数是 z = x,而神经元用的版本是 z = wx+b,意思是说给神经元喂一个 x,它给你吐出 wx+b。
hardlim() 函数
顾名思义,hardlim() 代表 hard limit,就是硬分类函数而通常用符号函数来模拟 (sign function),它用于解决分类问题,如下图所示:
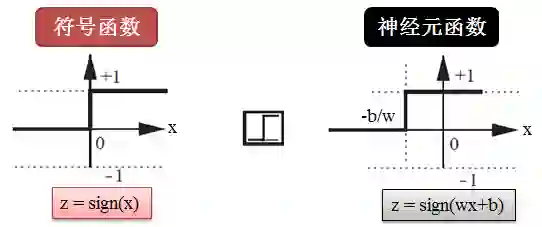
最简单的符号函数是 z = sign(x),而神经元用的版本是 z = sign(wx+b),意思是说给神经元喂一个 x,它计算出 z,如果大于 0 给你吐出 1,如果小于 0 给你吐出 -1。
logsig() 函数
顾名思义,logsig() 代表 logistic sigmoid,就是对率函数 (sigmoid function),它也用于解决分类问题,不过是以概率的方式,如下图所示:
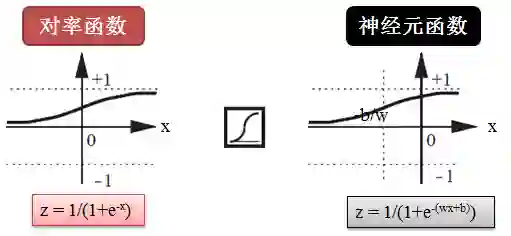
最简单的符号函数是 z = 1/(1+e-x),而神经元用的版本是 z = 1/(1+e-(wx+b)),意思是说给神经元喂一个 x,它计算出 z。给定一个阈值 c,如果 z 大于 c 给你吐出 1,如果 z 小于 c 给你吐出 -1。
最简单的 ANN 只包含一个输入 x,一个神经元和一个输出 y。
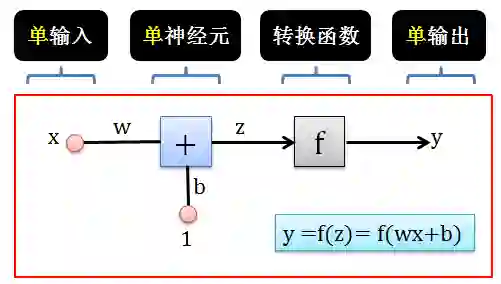
在 ANN 中从 x 生成 y 的过程如下:
用 x 乘以权重 w 得到 wx
用 1 乘以偏差 b 得到 b
将 wx 和 b 相加得到 z = wx+b
用转换函数 f 将 z 转成 y = f(z)
不要太简单 huh?
稍微加点难度?把一个输入 x 加强为多个输入 {x1, x2,…, xR},神经元和输出 y 还是一个。

那么在这样 ANN 中从 {x1, x2,…, xR} 生成 y 的过程如下:
用 x1 乘以权重 w1 得到 w1x1
用 x2 乘以权重 w2 得到 w2x2
…
用 xR 乘以权重 wR 得到 wRxR
累加全部得到 w1x1+ … + wRxR
用 1 乘以偏差 b 得到 b
将 w1x1+ … + wRxR 和 b 相加得到 z
用转换函数 f 将 z 转成 y = f(z)
可以跟得上 huh?
作为一个懒人和爱美之人,每次写 w1x1+ … + wRxR 相当烦而且难看,引进向量来简写吧。
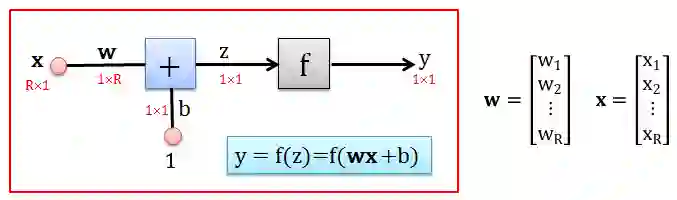
令 wx = w1x1+ … + wRxR,其中 w 是行向量,x 是列向量,这次定义就是避免引进转置符号。现在那么在这样 ANN 中从 x 生成 y 的过程如下:
用 x 乘以权重 w 得到 wx
用 1 乘以偏差 b 得到 b
将 wx 和 b 相加得到 z = wx+b
用转换函数 f 将 z 转成 y = f(z)
是不是很美 huh?
稍微再加点难度?把
输入 x 变成 {x1, x2,…, xR}
一个神经元变成多个神经元
输出 y 变成 {y1, y2,…, yS}

注意 x 和 y 的个数可以不相等,R 不见得等于 S。那么在这样 ANN 中从 {x1, x2,…, xR} 生成 {y1, y2,…, yS} 的过程如下:
用 x1 乘以权重 w1,1 得到 w1,1x1
用 x2 乘以权重 w1,2 得到 w1,2x2
…
用 xR 乘以权重 w1,R 得到 w1,RxR
累加全部得到 w1,1x1 + … + w1,RxR
用 1 乘以偏差 b1 得到 b1
将 w1,1x1 + … + w1,RxR 和 b1 相加得到 z1
用转换函数 f 将 z1 转成 y1 = f(z1)
…
重复 1 到 8 得到 y2,…, yS
其中 wi,j 代表 xj 到第 i 个神经元的权重。
勉强跟得上 huh?
同样上面的 wi,1x1 + … + wi,RxR 看起来太臃肿,没有美感而且会写死你,引进矩阵来简写吧。
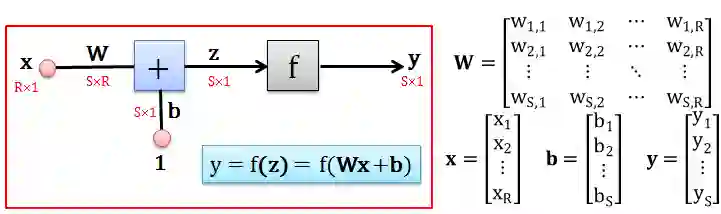
令矩阵 W 和列向量 b, x, y 定义如上图中的表达式,现在那么在这样 ANN 中从 x 生成 y 的过程如下:
用 x 乘以权重 W 得到 Wx
用 1 乘以偏差 b 得到 b
将 wx 和 b 相加得到 z = wx+b
用转换函数 f 将 z 转成 y = f(z)
不能再美 huh?
最后加难度到顶,将单层变多层,需要注意有几点:
每层 L 都有自己的权重矩阵 WL 和偏差列向量 bL
每层 L 含有的神经元的数目都可以不同,其个数定义为 SL
输入数据 x 可认为在第 0 层,因此其个数 R 定义成 S0
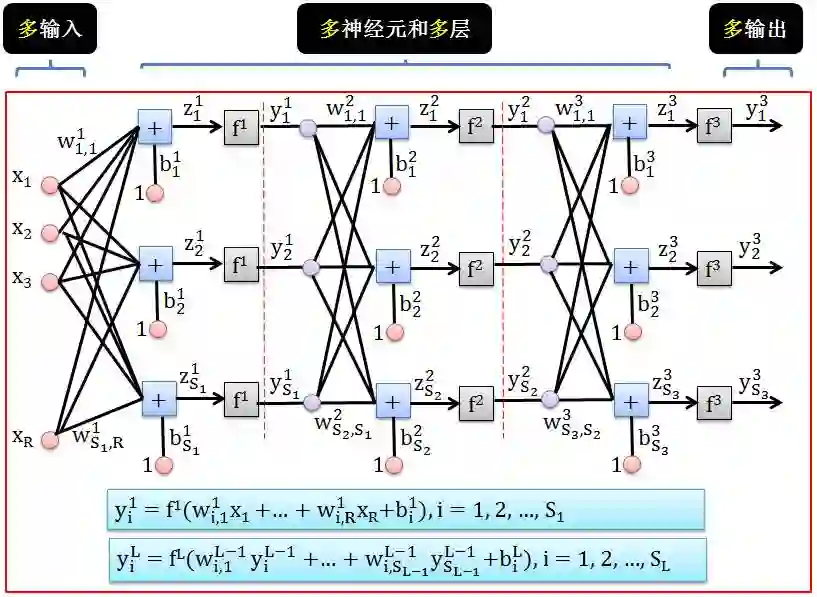
假设 ANN 有 3 层,那么从 {x1, x2,…, xR} 生成 {y31, y32,…, y3S3} 的过程如下:
用 x1 乘以权重 w11,1 得到 w11,1x1
用 x2 乘以权重 w11,2 得到 w11,2x2
…
用 xS0 乘以权重 w11,S0 得到 w11,S0xS0
累加全部得到 w11,1x1 + … + w11,S0xS0
用 1 乘以偏差 b11 得到 b11
将 w11,1x1 + … + w11,S0xS0 和 b11 相加得到 z11
用转换函数 f 将 z11 转成 y11= f(z11)
…
重复 1 到 8 得到 y12,…, y1S1
…
重复 1 到 10 得到 y21,…, y2S2
再重复 1 到 10 得到 y31,…, y3S3
其中 wLi,j 代表第 L-1 层第 j 个神经元到第 L 层第 i 个神经元的权重。
跟不上了 huh? 如果之前不引入矩阵符号来化简还情有可原,现在对于这种多层 ANN 不写成矩阵形式会要命的。
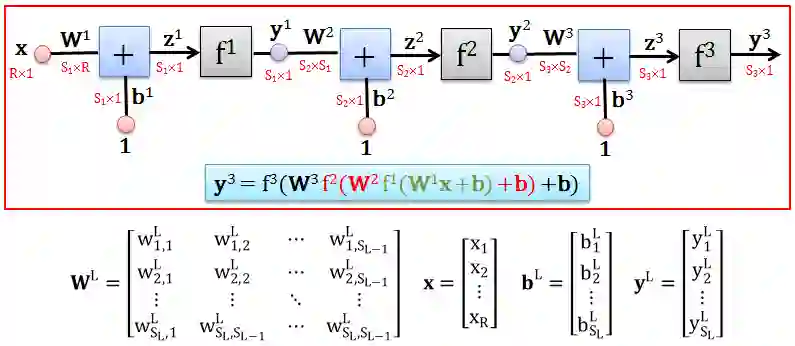
对第 L 层,令矩阵 WL 和列向量 bL, x, yL 定义如上图中的表达式,现在那么在这样 ANN 中从 x 生成 y3 的过程如下:
用 x 乘以权重 W1 得到 W1x
用 1 乘以偏差 b1 得到 b1
将 W1x 和 b1 相加得到 z1 = W1x+b1
用转换函数 f 将 z1 转成 y1 = f(z1)
重复 1 到 4 得到 y2 = f(z2) = f(W2y1+b2)
再重复 1 到 4 得到 y3 = f(z3) = f(W3y2+b3)
你自己说美不美 huh?
这种 ANN 每层的神经元都连接这下一层的所有神经元,因此被称为全连接前馈 (fully connected feedforward) ANN。这也是最常见的一种 ANN。
如何在 Matlab 生成全连接前馈 ANN 呢?一行程序:
net = feedforwardnet
下面是这个 ANN 的关键信息:

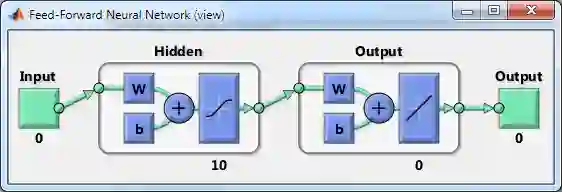
把注意力集中到 dimensions 一栏。Matlab 默认的 ANN 含有
1 个输入 (numInputs: 1)
2 层 (numLayers: 2),一个隐藏层,一个输出层
1 个输出 (numOutputs: 1)
最重要的信息在 Connections 一栏,读懂它就知道这个 ANN 是如何连在一起的。
基本规则:1 代表连接,0 代表没连接
biasConnect: [1; 1] 是一个列向量,第 i 行元素代表偏差项是否连接 layer i。本例可知,偏差项 b 连接 layer 1 和 layer 2
inputConnect: [1; 0] 是一个列向量,第 i 行元素代表 Input 是否连接 layer i。本例可知,Input 项只连接 layer 1,不连接 layer 2
outputConnect: [0 1] 是一个行向量,第 i 列元素代表 Output 是否连接 layer i。本例可知, Output 项只连接 layer 2,不连接 layer 1
layerConnect: [0 0; 1 0] 是一个矩阵,每行代表截止层 (layer 2),每列代表起始层 (layer 1)。本列可知,只有 layer 1连着 layer 2,因此矩阵的第 1 列第 2 行为 1,其余为 0
有人会说废话,当然只可能 layer 1 连着 layer 2,有可能自己连自己,或者 layer 2 连着 layer 1 吗?有可能啊,循环神经网络就是自己连自己,双向网络就是layer 2 连着 layer 1,但是超出本贴内容范围了。
听着好晕,能否在 Matlab 可视化这个全连接前馈 ANN 呢?一行程序:
view(net)
美图如下 (建议一边看图一边强化上面讲的那些连接规则):
有野心的读者肯定会想,谁会用只有一层隐藏层的 ANN?不要小看 Matlab,试试下面一行代码:
net = feedforwardnet( [5 6 7] )
根据下面的截屏,相信你完全可以读懂下面的信息,而且也知道这样一个 3 层隐藏层的 ANN 是如何连接的。


本章举一个用 ANN 来分类苹果和香蕉,假设我们考虑区分它们的三个特征:形状、质地和重量,用 x 来表示:
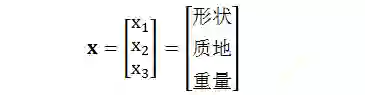
其中
形状:1 代表圆,-1 代表长
质地:1 代表滑,-1 代表糙
重量:1 代表重,-1 代表轻
下面动图是用 hardlim() 为转换函数的 ANN 作分类的,Just For Fun!
接下来三章分别用 Matlab 里面神经网络函数来解决三个应用领域的问题:房价拟合,癌症识别和花朵聚类。任何这些问题的工作流程都有以下七个主要步骤。(在步骤 1 的数据收集通常会发生在 Matlab 环境之外,在下面例子中假设已经处理好了数据)
收集数据
创建网络
配置网络
初始化重量和偏差
训练网络
验证网络
使用网络
步骤 2 到 7 你可以自己编写程序,当然也可以用 Matlab 自带的图形用户界面 (graphical user interface, GUI),只用在命令栏里轻轻敲打 nnstart,下图出现后一步步按照提示来,你就天空任鸟飞,海阔凭鱼跃了。
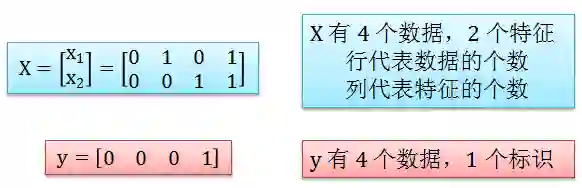
ANN 可以解决监督学习下的回归 (regression) 问题。回归问题需要输入 X 和输出 y,以 AND 函数为例,在 Matlab 里规定 X 和 y 要写成以下数组 (array) 格式
X = [0 1 0 1; 0 0 1 1];
y = [0 0 0 1];
注意 Matlab 要求的格式和我们之前规定的格式有所不同,比如行和列代表的意思完全相反,解释如下图:
上例中 0 代表 false,1 代表 true,y 一个值就是 x1 和 x2 每一个值的 AND 结果。比如:
y(1) = x1(1) ∧ x2(1)= 0∧0 = 0
y(2) = x1(2) ∧ x2(2) = 1∧0 = 0
y(3) = x1(3) ∧ x2(3) = 0∧1 = 0
y(4) = x1(4) ∧ x2(4) = 1∧1 = 1
用 Matlab GUI 玩转 ANN 回归的步骤如下:
步骤 1 – 点击下图 Fitting app (等价于运行 nftool 函数)
步骤 2 – 下图关于回归 ANN 的介绍框出现,之后会先选择数据,再点击 Next
步骤 3 – 点击 Load Example Data Set 来选择 Matlab 里面自带的供你玩耍的数据

步骤 4 – 选择 House Pricing 再点击 Import
House Pricing 的数据明细如下:
houseInputs - a 13x506 matrix defining thirteen attributes of 506 different neighborhoods.
1. Per capita crime rate per town
2. Proportion of residential land zoned for lots over 25,000 sq. ft.
3. proportion of non-retail business acres per town
4. 1 if tract bounds Charles river, 0 otherwise
5. Nitric oxides concentration (parts per 10 million)
6. Average number of rooms per dwelling
7. Proportion of owner-occupied units built prior to 1940
8. Weighted distances to five Boston employment centres
9. Index of accessibility to radial highways
10. Full-value property-tax rate per $10,000
11. Pupil-teacher ratio by town
12. 1000(Bk - 0.63)^2, where Bk is the proportion of blacks by town
13. Percent lower status of the population
houseTargets - a 1x506 matrix of median values of owner-occupied homes in each neighborhood in 1000's of dollars.
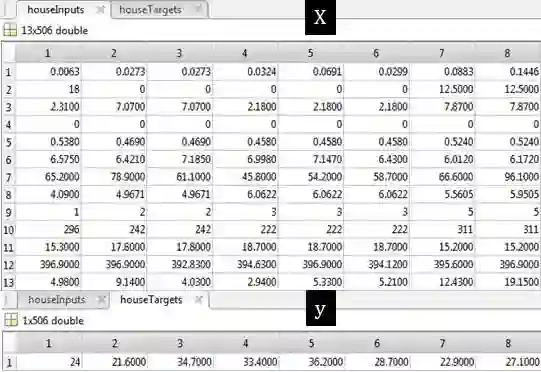
从上表可看出总共有 506 个数据,其中 X 有 13 列,包括人均犯罪率、房间数、学生老师比率、房产税、黑人指数等等,而 y 记录着房价中位数。
步骤 5 – 用 75%-15%-15% 来划分训练集、验证集和测试集,再点击 Next
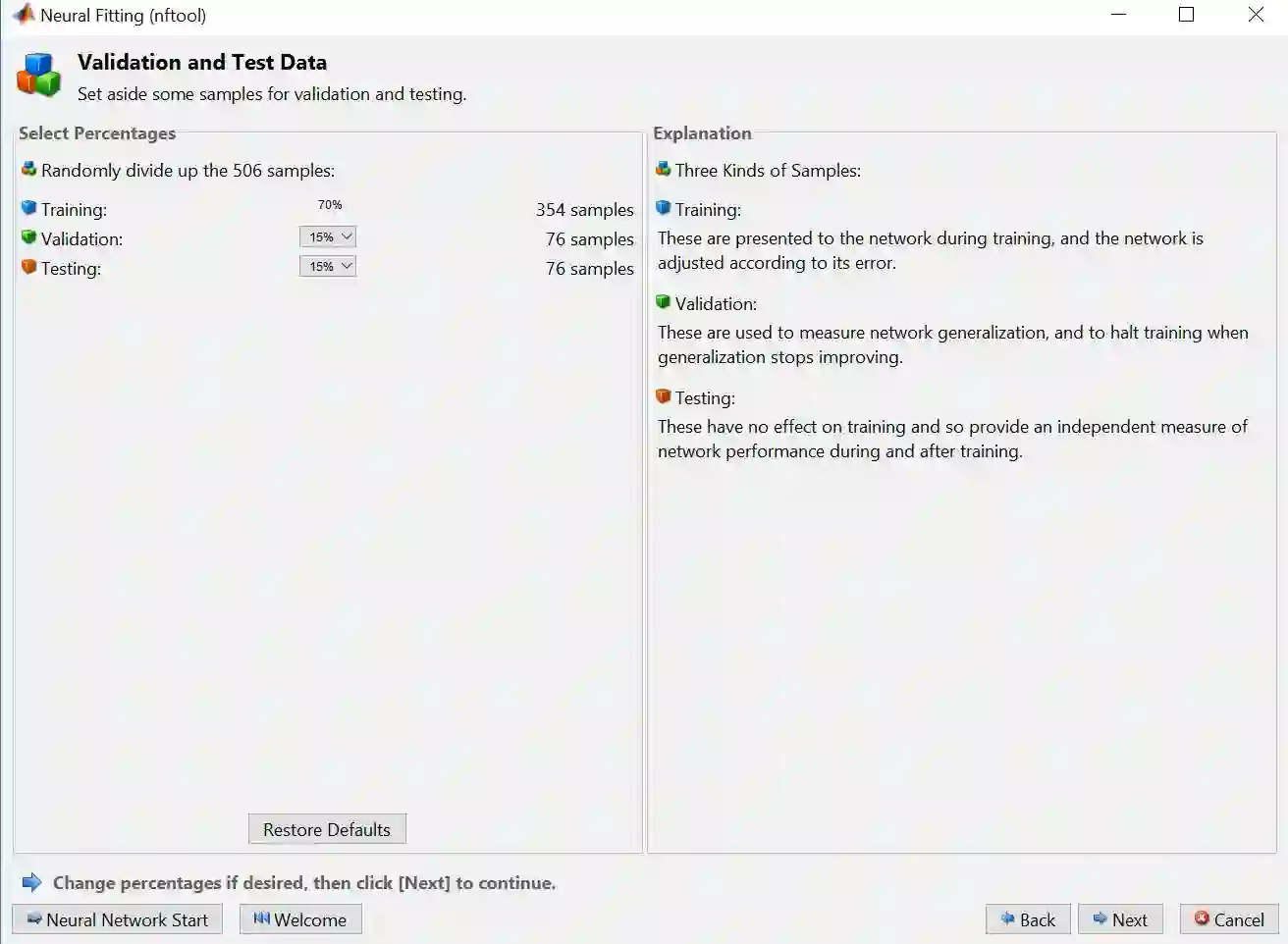
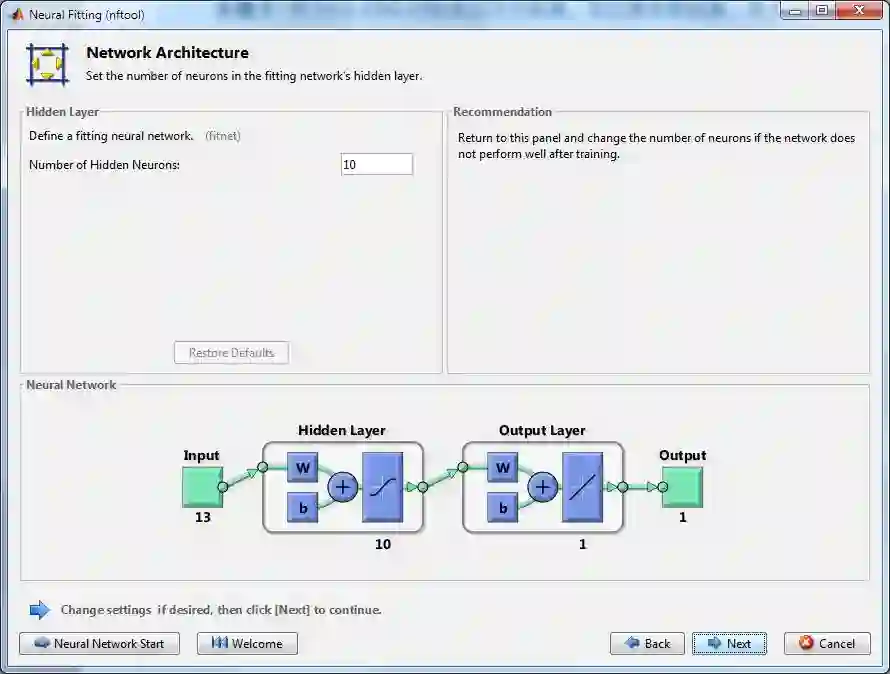
步骤 6 – 默认的回归 ANN (如彩图) 有 2 层,一层含 10 个神经元的隐藏层,一层输出层。隐藏层转换函数为 sigmoid 函数,而输出层转换函数为 linear 函数,原因是要输出一个实数值。再点击 Next
步骤 7 – 选择训练算法 Levenberg-Marquardt,再点击 Train
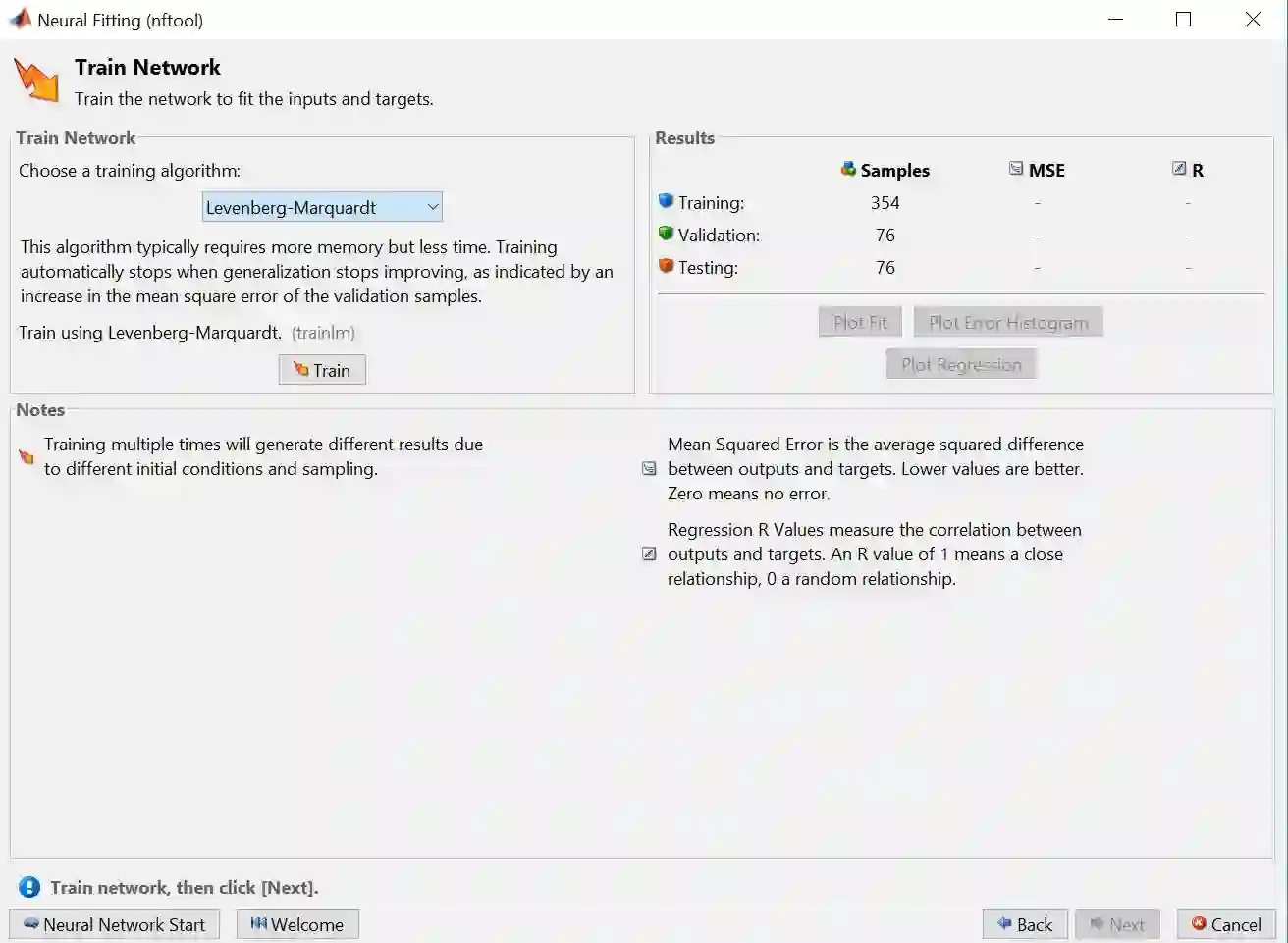
算法有 Levenberg-Marquardt (LM),Bayesian Regularization (BR) 和 Scaled Conjugate Gradient (SCG) 三个选项。
LM 是最常用也是默认的选项
BR 对那些带有噪声数据的问题得到的解更准确
SCG 对大数据的问题解法更为高效
这些算法的终止条件是:当验证误差连续在六次迭代中没有减小。
训练完之后得到下图。
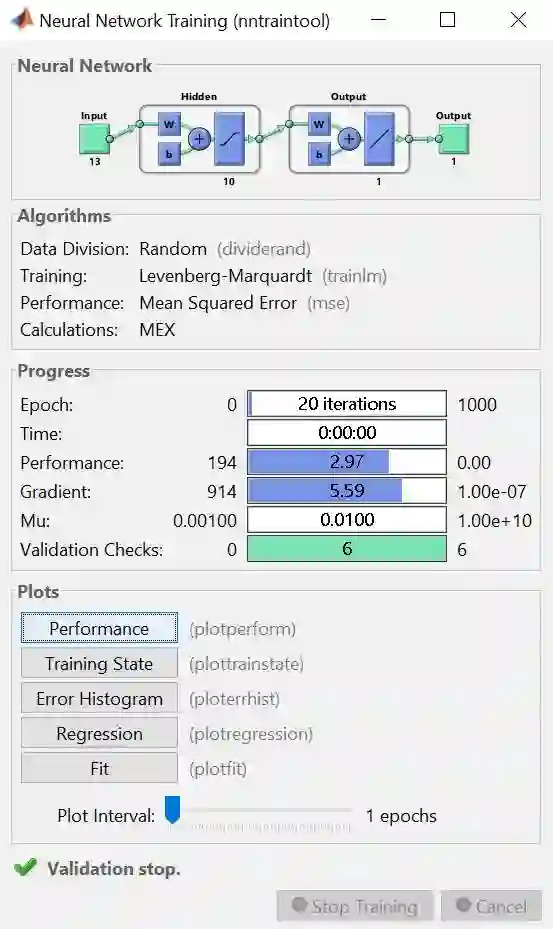
上图是训练完的结果概要,整个板上分 Neural Network, Algorithms, Progress 和 Plots 四小块。
Neural Network 板上画出解决该问题的神经网络图
Algorithms 板上显示随机划分数据方法、LM 算法和 MSE 性能评估
Progress 板上展示算法小于 20 次迭代次数 (总共1000次),用时几乎为零,MSE 值为 2.97,梯度很小 (意味着找到最优解) ,等等
Plots 板上有 5 种绘图可供展示
步骤 8 – 在上图 Plots Panel 里面分别点击那 5 个按钮得到以下 5 幅图,分别是:
Performance (性能图)
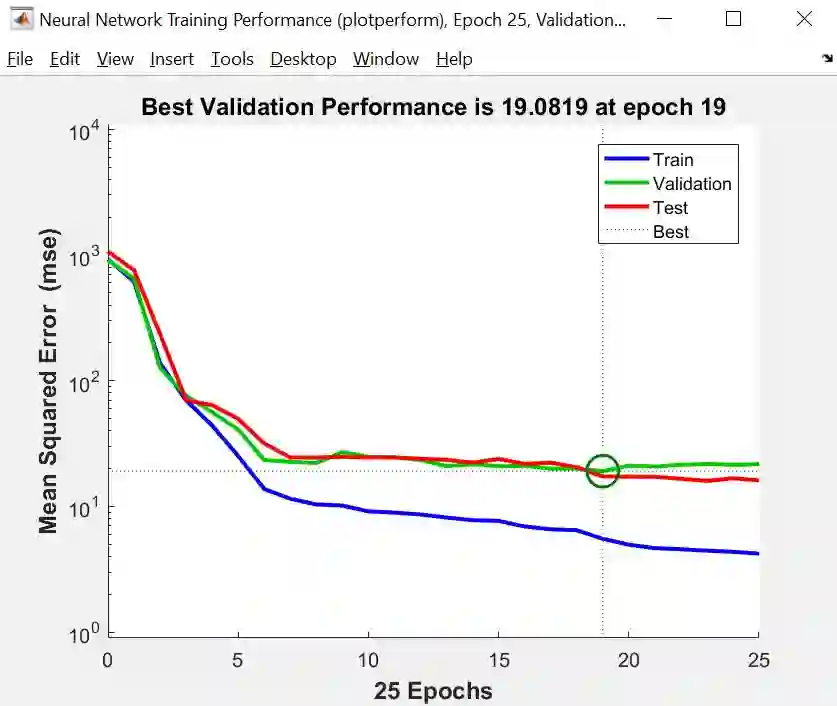
性能图画出训练、验证和测试的 MSE 随着迭代次数的走势,由上图可知
三个 MSE 都很小,而验证和测试 MSE 样子差不多
最小的验证 MSE 发生在第 19 次迭代 (深绿色圆圈),而且在此之前没有过拟合现象,即没有训练 MSE 递减但验证 MSE 递增的现象出现
Training State (训练状态图)
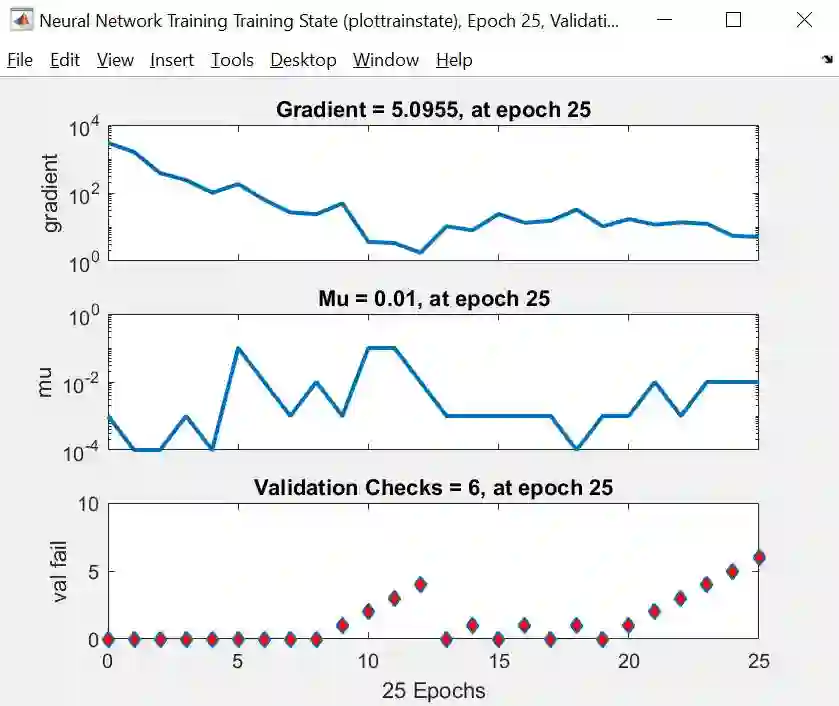
训练状态图给出梯度、mu 和验证检查的三幅图,由上图可知
梯度是稳步减小的
mu 是 LM 算法里面的一个参数,基本上随着迭代次数是稳定变化的,最大值也没超过 0.01
验证检查就是找到一个时点,而它之后 6 个时点对应的 MSE 都没有减小。在时点 19 到 25 上,验证 MSE 单调增大,因此算法停止,最小的验证 MSE 发生在第 19 次迭代上
Error Histogram (误差柱状图)
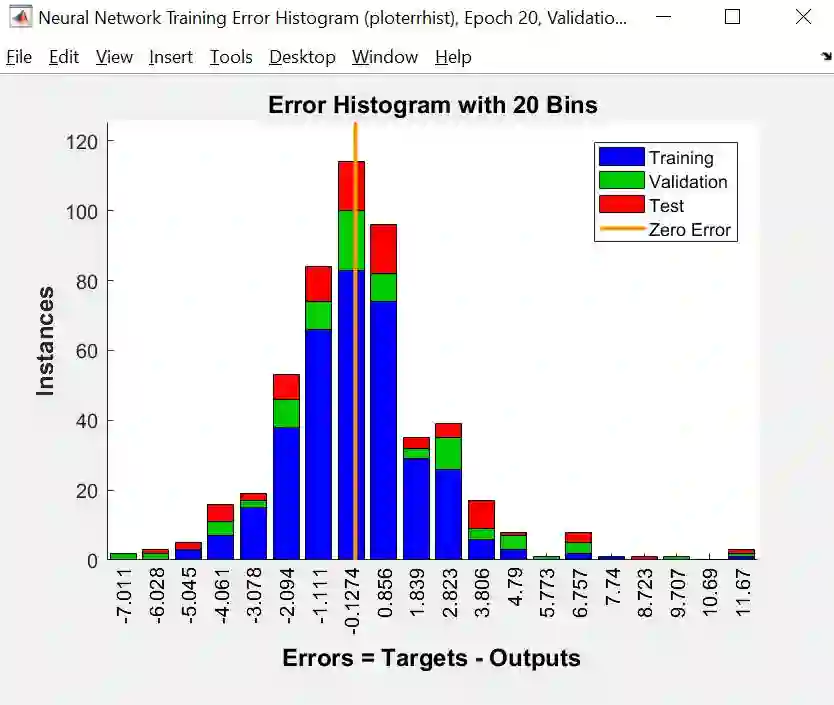
误差柱状图给出的是训练、验证和测试的误差分布图。黄线是零误差,我们发现绝大部分误差都在 -5 和 5 之间,但有几个误差到达 11,这些可能是异常点 (outlier)。如果它们是真实数据,我们需要收集更多的数据再来重新训练神经网络;如果它们是错误数据,我们需要删除它们再来重新训练神经网络。
Regression (回归图)
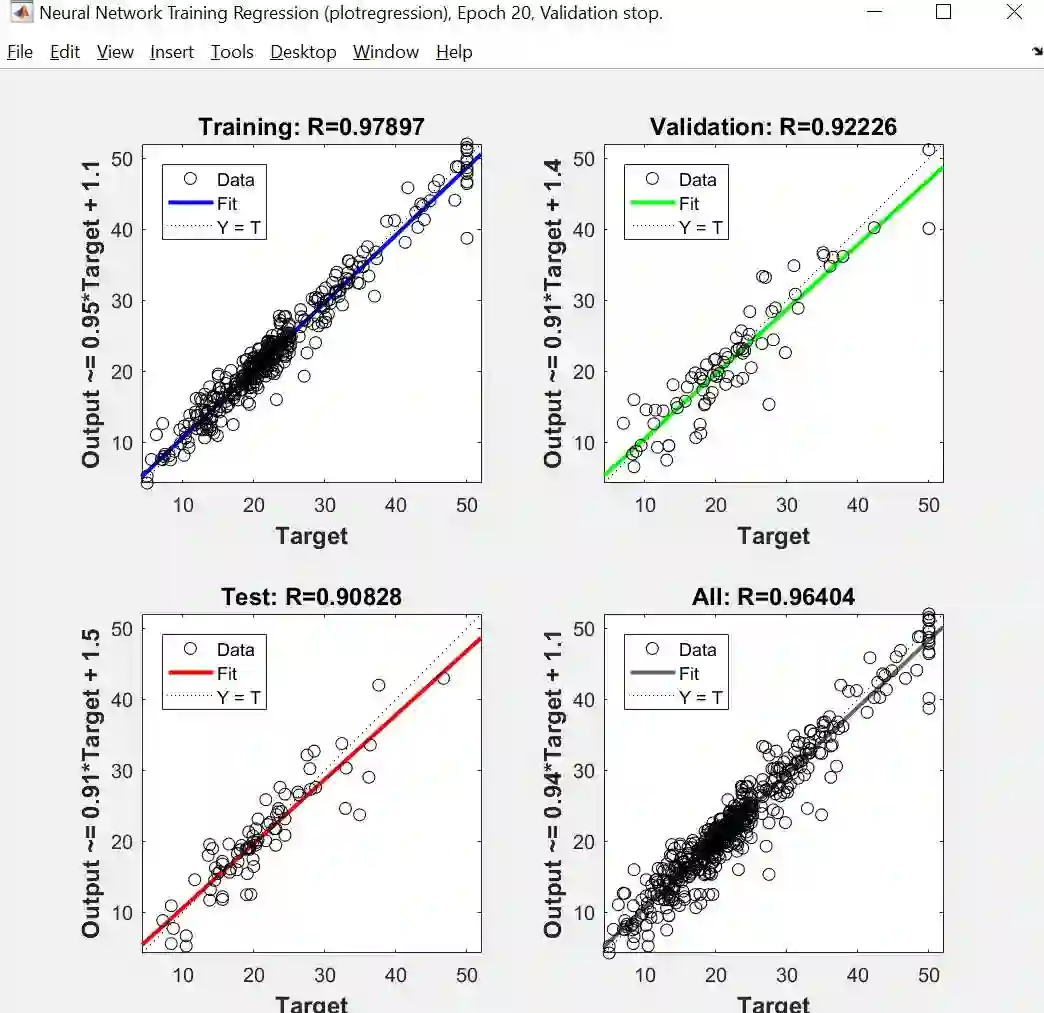
对于完美的回归图,拟合出来的直线斜率是 45 度而 R 值是 1,由上图可知,训练 R 值为 0.97,测试 R 值为 0.90,回归结果还不错。如果希望能调出更好的结果,可以尝试:
换权重和偏差的初始值
增加隐藏层神经元个数
增加数据个数
换一个训练方法
Fit (拟合图)
拟合图是一个 X-y 二维空间画出来的,因此只对一维数据 X 才适用。本例的 X 有 13 个维度,因此根本不可能在平面图中画出。
通常结果有三种情况
如果训练结果不好,证明 ANN 欠拟合,可以增加隐藏层神经元数,再次训练
如果训练结果好但是测试结果不好,证明 ANN 过拟合,可以减少隐藏层神经元数,再次训练
如果训练和测试结果都很好,如本例一样,那么大功告成
这个 GUI 更酷的功能是它可以自动帮你生成所有代码 (code) 、应用 (app) 和绘图 (graphic),点击下图的 Next。
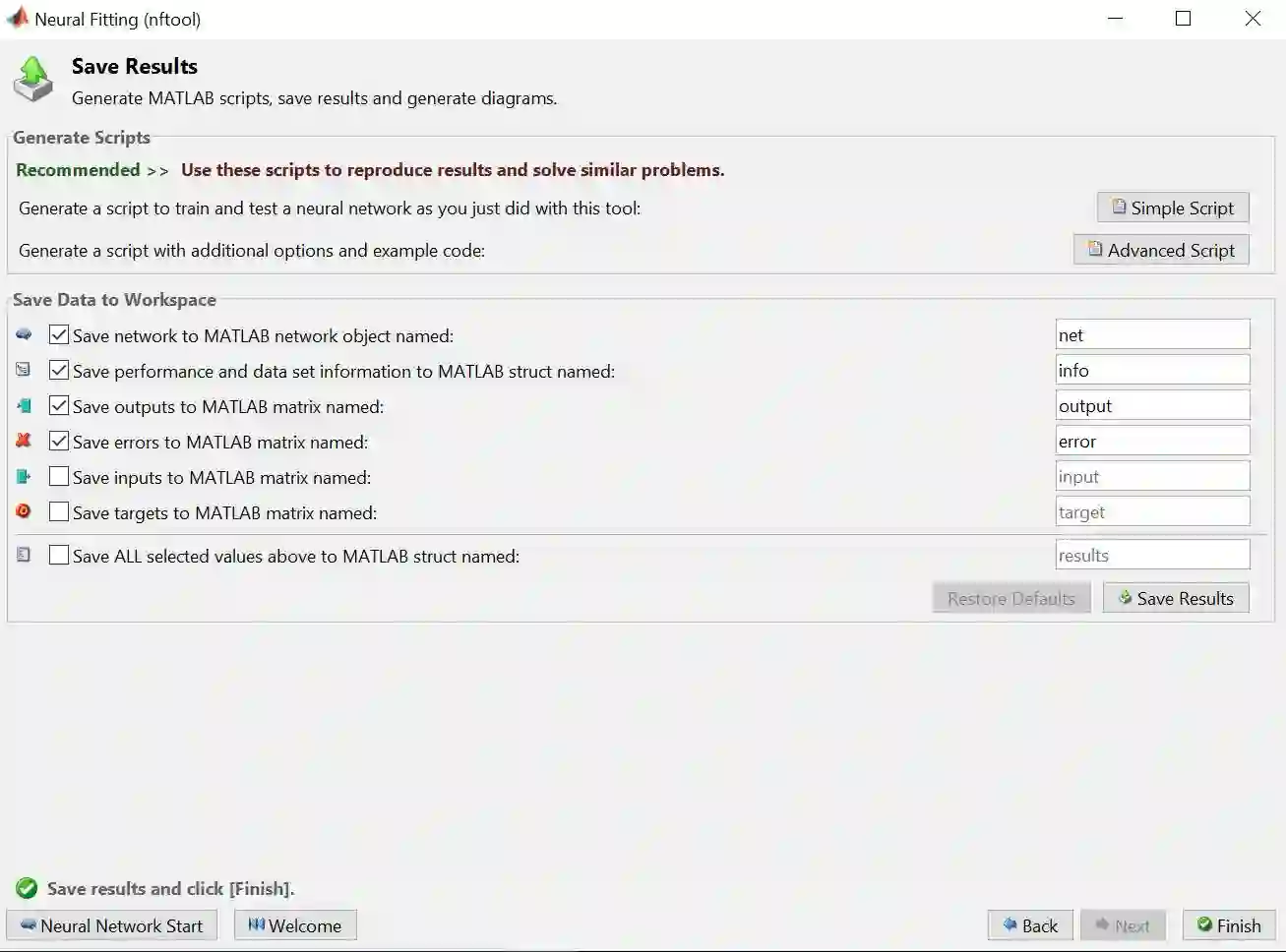
以生成代码为例,点击 Simple Script 或者 Advanced Script 来用代码重现之前所有步骤的操作。它的好处是你有更多自由度来修改每个步骤设定的一些参数,比如训练集验证季测试集的划分比例,比如根据用户需求打印出相应的图,等等。
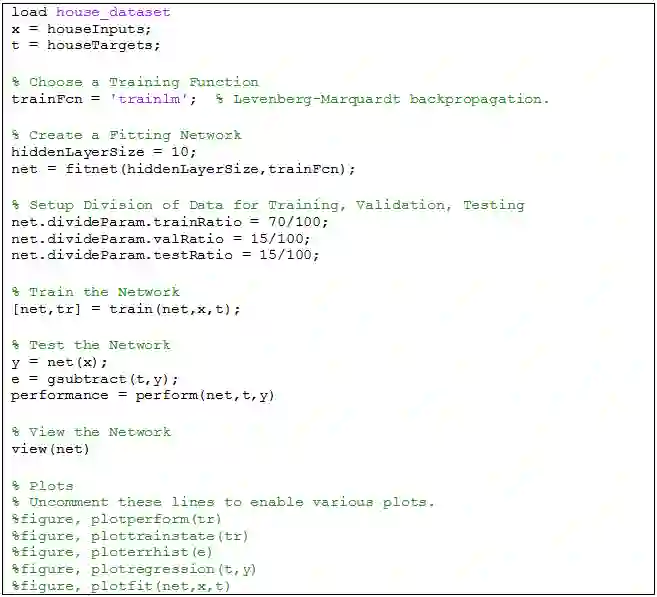
自动生成的代码如下:
有了这个框架,现在你有无限自由小改程序来得到自己想要的了 (哥当时写论文时 Matlab 怎么没有这个功能?!?),以下改动的地方用黄色高亮标注。
修改 1 - 你可以选其他如 Chemical 数据。如果你不知道 Matlab 自带哪些数据,在命令框里打 help nndatesets 便一目了然:
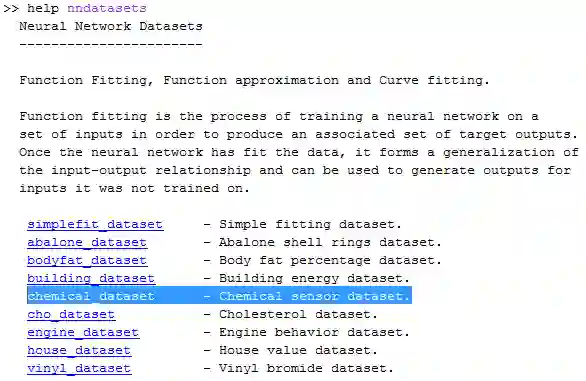
小改之后的代码如下:

修改 2 – 假如训练结果不佳,你可以将 LM 算法改成 BR 或 SCG。如果你不知道 Matlab 自带哪些算法,在命令框里打 help nntrain 便一目了然:

如果数据含有噪声,小改成 BR 之后的代码如下:

修改 3 – 你当然可以改变隐藏层神经元的个数,也可以增加隐藏层的个数。奥妙在于怎么用 fitnet 函数。

当该函数的第一个参数是一个纯量,比如 10,代表只有一层隐藏层,而且含神经元 10 个;如果需要三层隐藏层,每层含有神经元分别是 6,8,5 个,类比一下小改之后的代码如下:

修改 4 – 假如数据足够,你可以另一套百分比来划分训练、验证和测试集 (减小训练集份额,增大验证集和测试集份额),比如 50-30-20,小改之后的代码如下:

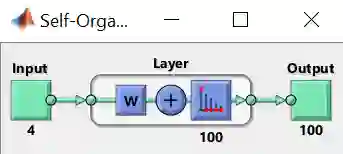
修改 5 – 训练和测试的代码是标准化的,不需要任何修改,当你想可视化神经网络图,用 view(net) 语句。
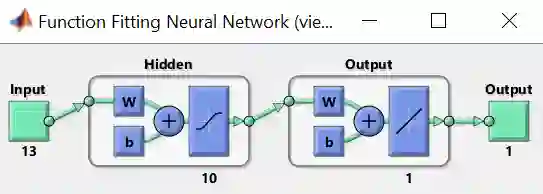
当你想看训练完后的性能图 、训练状态图、误差柱状图、回归图和拟合图时,将下面 % 去掉即可:

总结,每次训练 ANN 时,因为
权重和偏差的初始值不一样
训练集验证季测试集划分的方式不一样
因此相同的数据会得到不同的结果。为了确保 ANN 的产出结果准确可靠,运行该程序 5 到 10 次看看结果。
ANN 可以解决监督学习下的分类 (classification) 问题。通常分类问题需要输入 X 和输出 y,以 EXCLUSIVE-OR 函数为具体例子,在 Matlab 里规定 X 和 y 要写成以下数组 (array) 格式
X = [0 1 0 1; 0 0 1 1];
y = [0 1 0 1; 1 0 1 0];
很迷惑对吗?X 还好理解,y 是分类型变量怎么有两行呢?原因是我们这里不用1,2,3,…来代表类1,2,3,而是用独热编码 (one-hot encoding) 的向量代表类,[1 0 0]T 代表类1,[0 1 0]T 代表类2,[0 0 1]T 代表类3,你发现规律了吗?
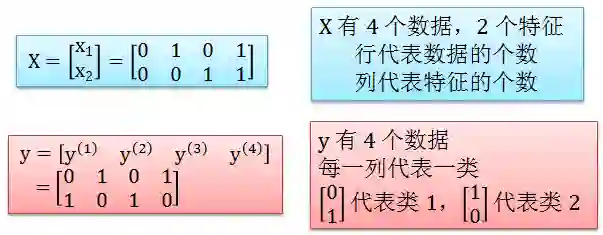
这种向量表达方式就是先确定好类的个数,用 K 表示,那么第 k 类就是 [0 0 … 1 … 0 0],向量第 k 个元素为 1,其余是 0。
用 Matlab GUI 玩转 ANN 分类的步骤如下:
步骤 1 – 点击下图 Pattern Recognition app (等价于运行 nptrtool 函数)

步骤 2 – 下图关于分类 ANN 的介绍框出现,之后会先选择数据,再点击 Next
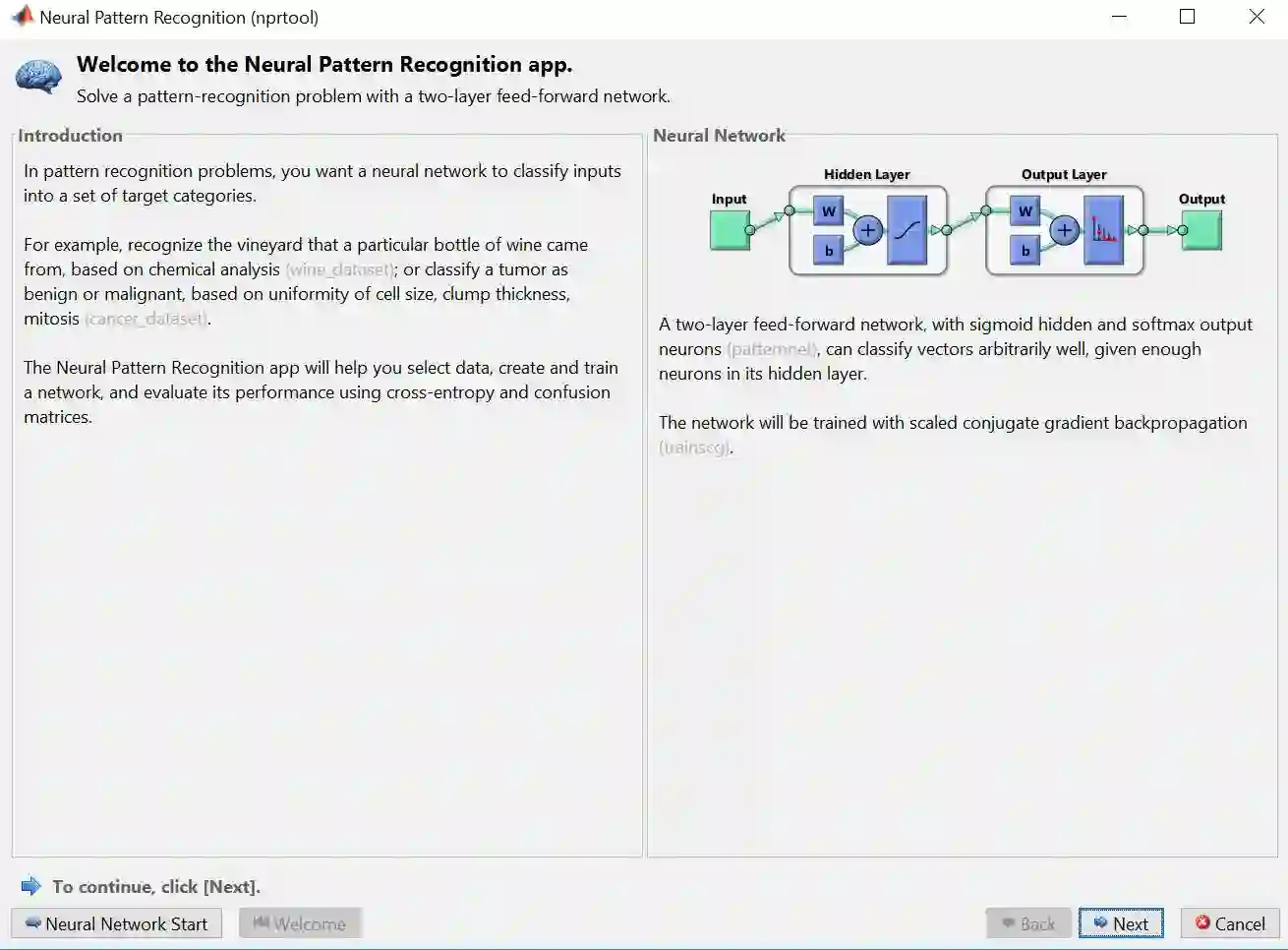
步骤 3 – 点击 Load Example Data Set 来选择 Matlab 里面自带的供你玩耍的数据
步骤 4 – 选择 Breast Cancer 再点击 Import
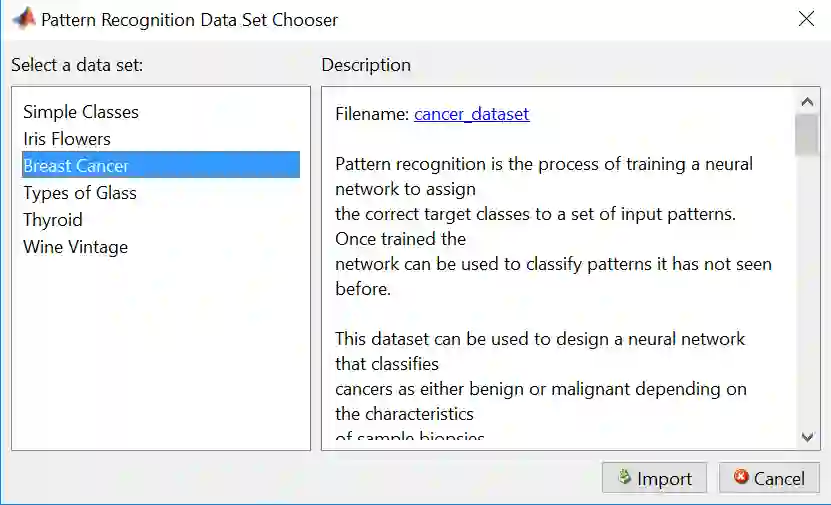
Breast Cancer 的数据明细如下:
cancerInputs - a 9x699 matrix defining nine attributes of 699 biopsies.
1. Clump thickness
2. Uniformity of cell size
3. Uniformity of cell shape
4. Marginal Adhesion
5. Single epithelial cell size
6. Bare nuclei
7. Bland chomatin
8. Normal nucleoli
9. Mitoses
cancerTargets - a 2x699 matrix where each column indicates a correct category with a one in either element 1 or element 2.
1. Benign
2. Malignant
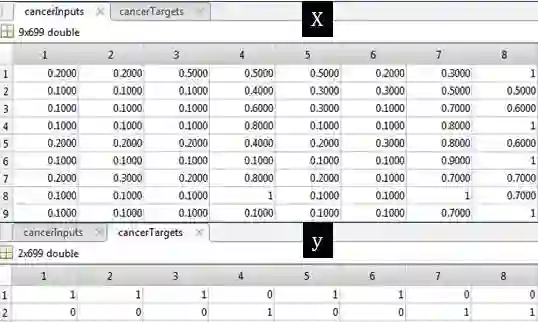
从上表可看出总共有 699 个数据,其中 X 有 9 列,包括团块厚度、细胞大小一致性、细胞形状一致性、边缘粘附、正常核仁、有丝分裂等等,而 y 记录良性 (用 [1 0]T 表示) 和恶性 (用 [0 1]T 表示)。
步骤 5 – 用 75%-15%-15% 来划分训练集、验证集和测试集,再点击 Next
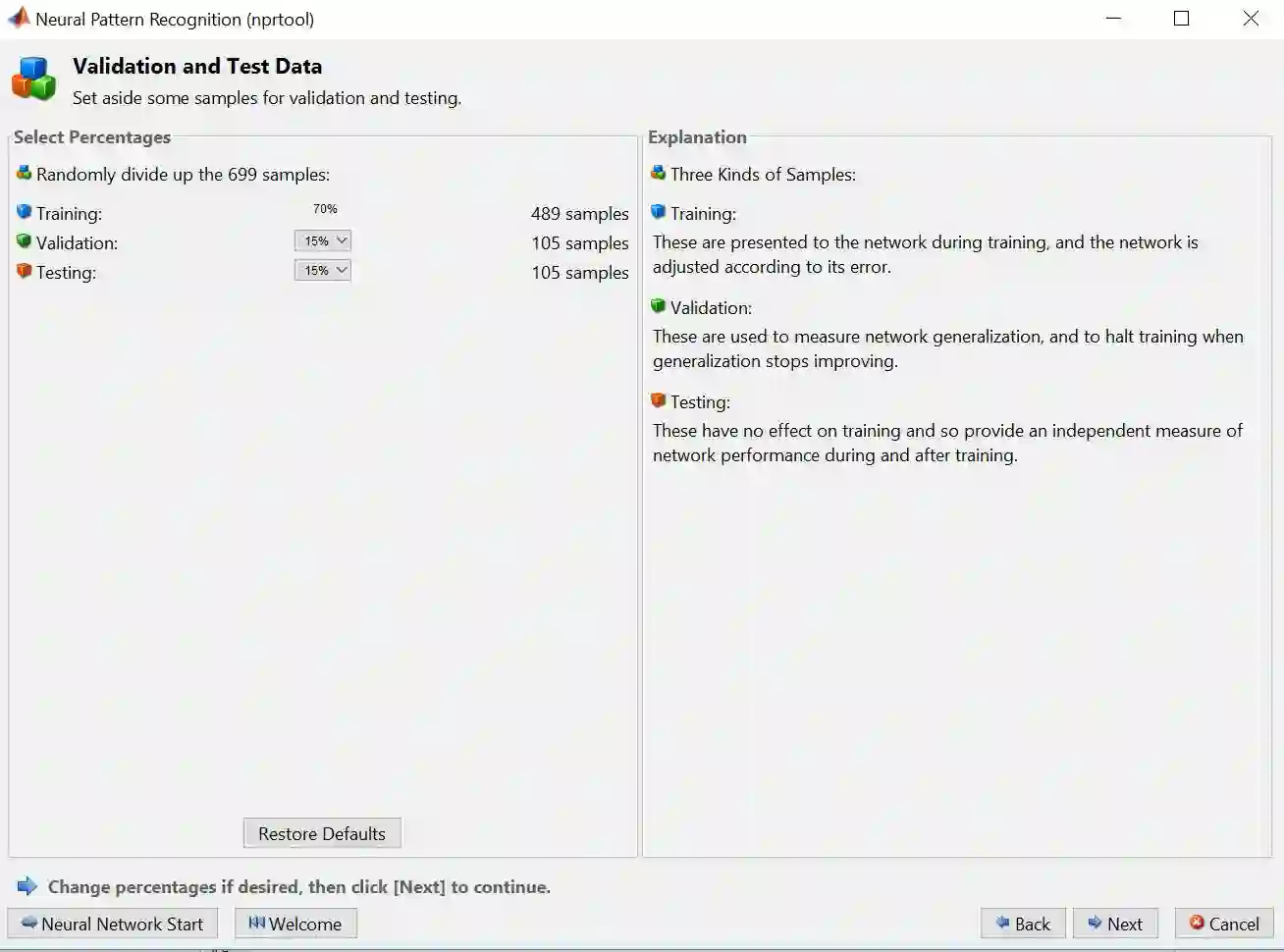
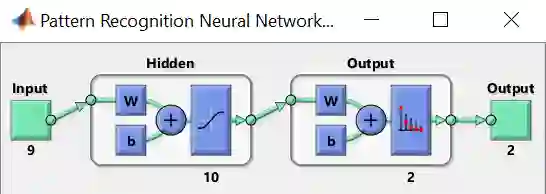
步骤 6 – 默认的分类 ANN (如彩图) 有 2 层,一层含 10 个神经元的隐藏层,一层输出层。隐藏层转换函数为 sigmoid 函数,而输出层转换函数为 softmax 函数,原因是要输出一个 0 和 1 之间的概率值。再点击 Next
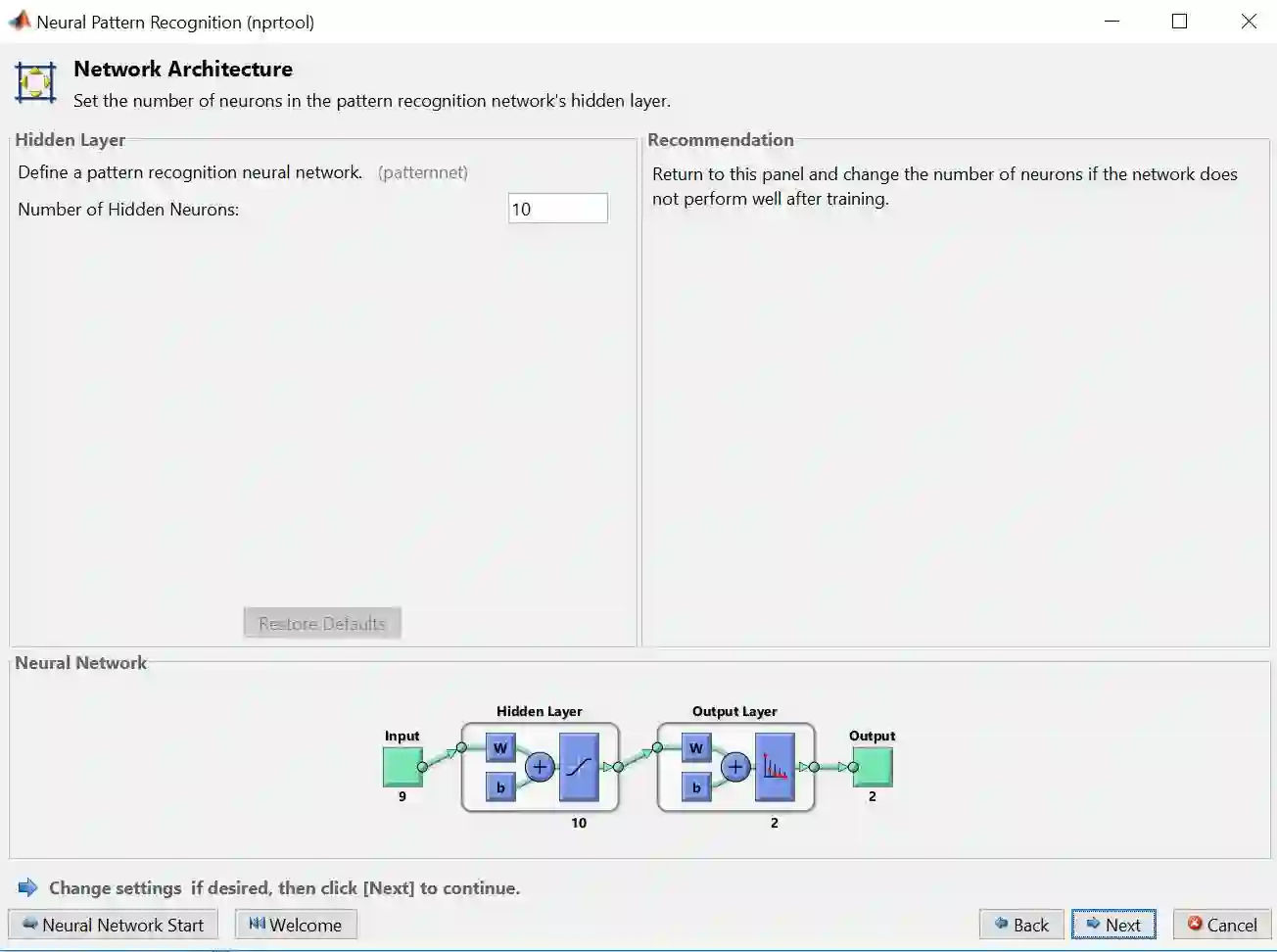
注意“输出神经元”大小为 2,和类别总数一样,原因是输出的样子会类似于 [1 0]T 或者 [0 1]T ,前者归为类1,前者归为类2。
步骤 7 – 选择训练算法 Scaled Conjugate Gradient,再点击 Train
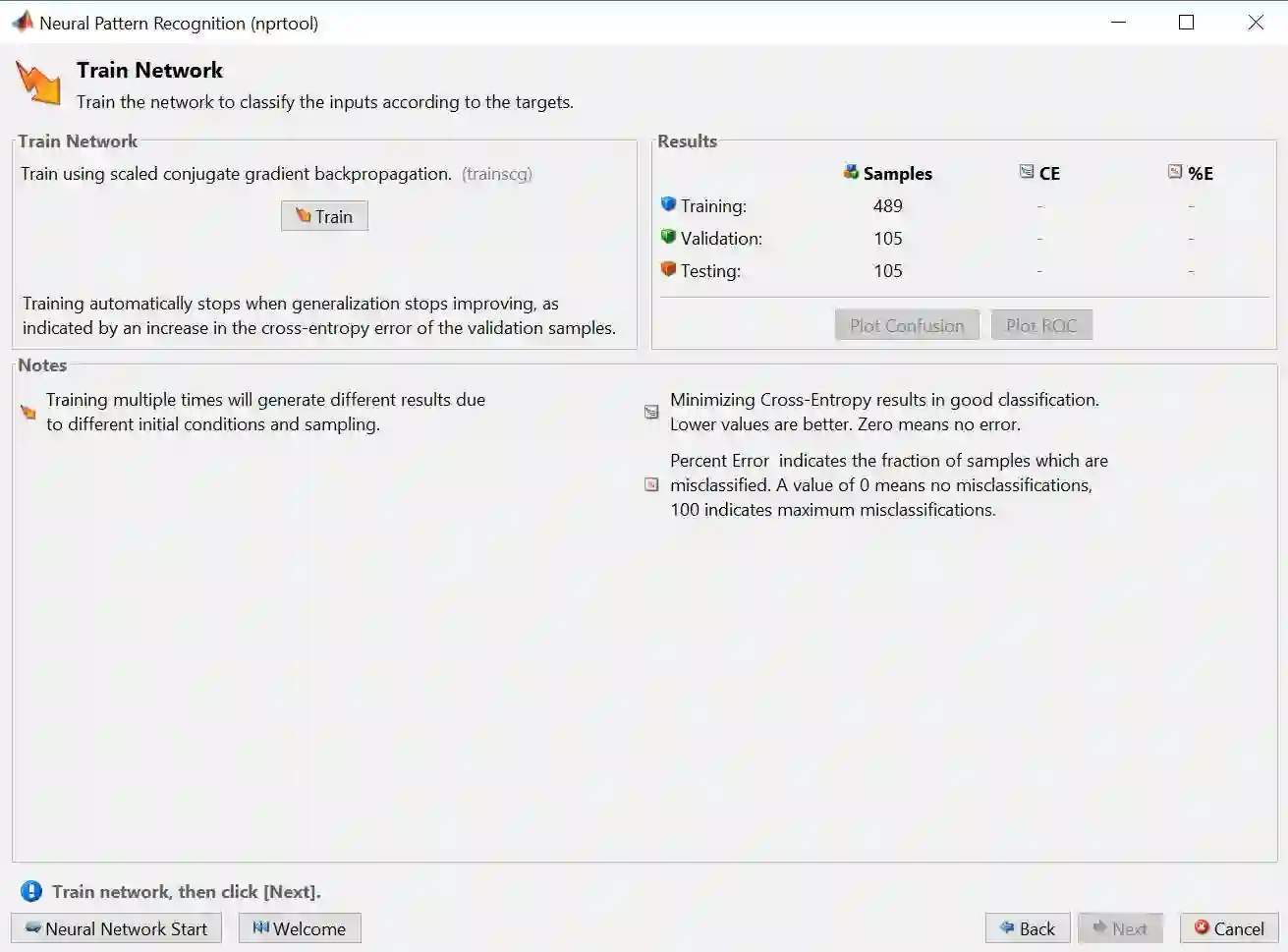
训练完之后得到下图。
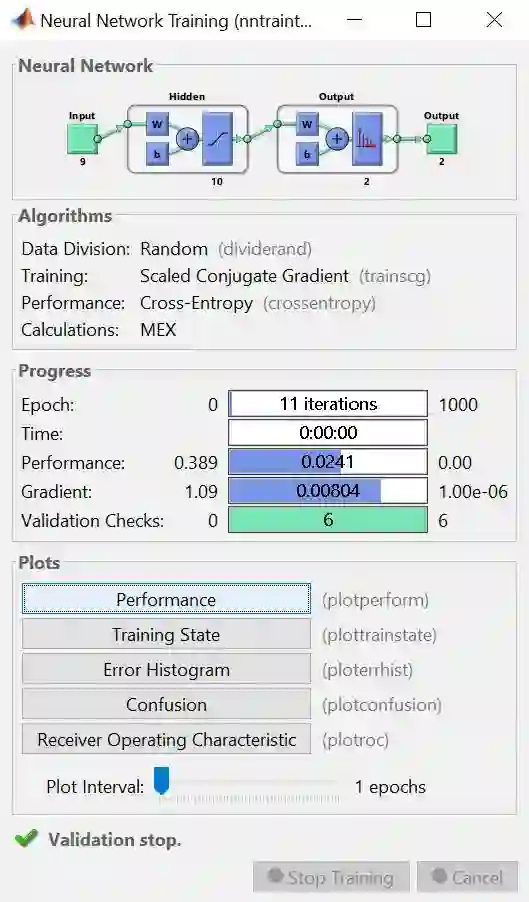
上图是训练完的结果概要,整个板上分Neural Network, Algorithms, Progress 和 Plots 四小块。
Neural Network 板上画出解决该问题的神经网络图
Algorithms 板上显示随机划分数据方法、SCG 算法和 Cross-Entropy (CE) 性能评估
Progress 板上展示算法小于 11 次迭代次数 (总共1000次),用时几乎为零,CE 值为 0.389,梯度几乎为 0 (意味着找到最优解) ,等等
Plots 板上有 5 种绘图可供展示
步骤 8 – 在上图 Plots Panel 里面分别点击那 5 个按钮得到以下 5 幅图,分别是:
Performance (性能图)

性能图画出训练、验证和测试的CE随着迭代次数的走势,由上图可知
三个 CE 都很小,奇怪的是验证 CE 居然小于训练 CE
最小的验证 CE 发生在第 8 次迭代 (深绿色圆圈),而且在此之前没有过拟合现象,即没有训练 CE 递减但验证 CE 递增的现象出现
Training State (训练状态图)
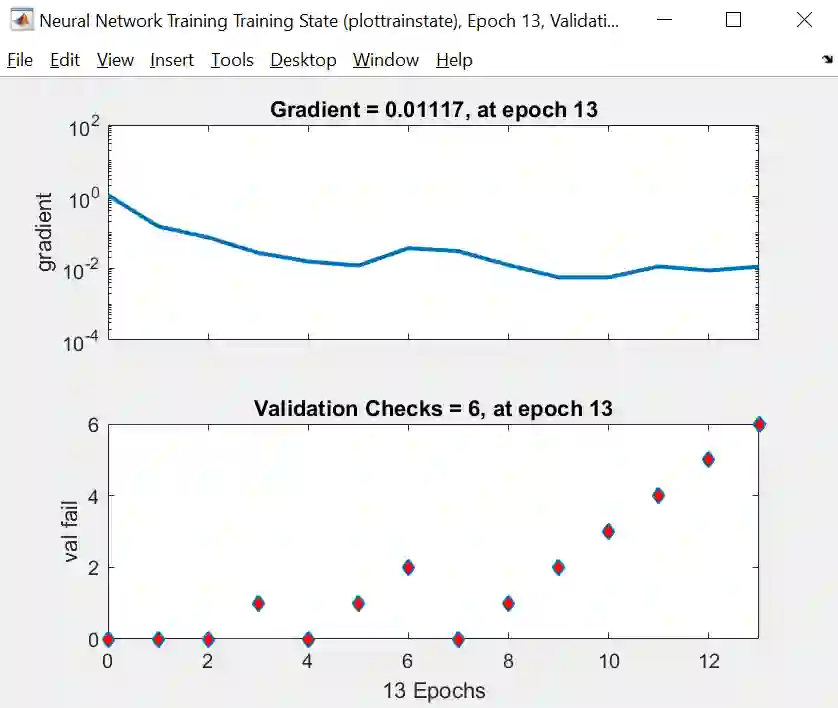
训练状态图给出梯度和验证检查的两幅图,由上图可知
梯度是稳步减小的
验证检查就是找到一个时点,而它之后 6 个时点对应的 CE 都没有减小。在时点 7 到 13 上,验证 CE 单调增大,因此算法停止,最小的验证 CE 发生在第 7 次迭代上 (有点奇怪,因为从性能图上看显示着是最小 CE 发生在第 8 次迭代上 )
Error Histogram (误差柱状图)
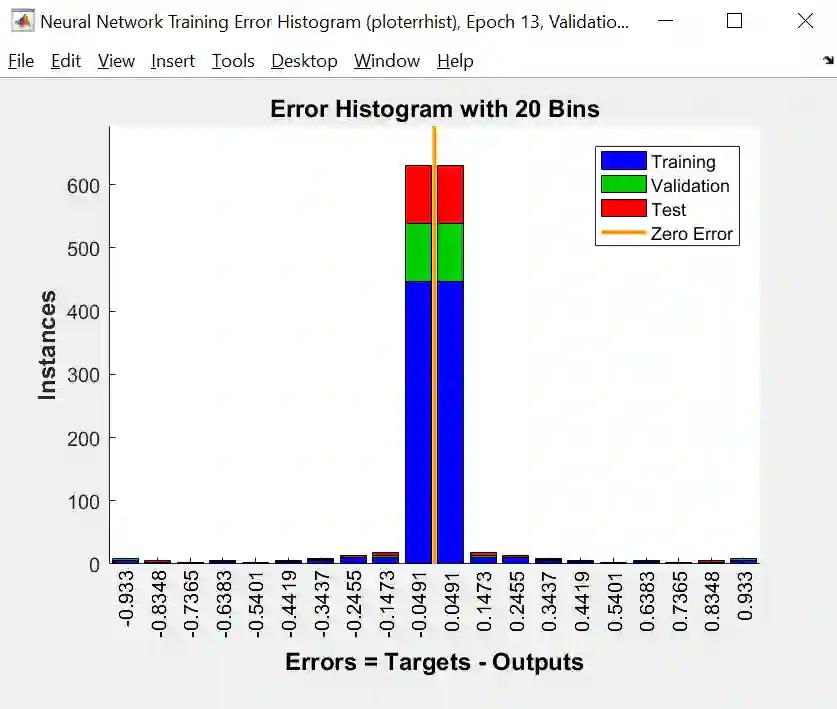
误差柱状图给出的是训练、验证和测试的误差分布图。黄线是零误差,我们发现绝大部分误差都在黄线附近,结果非常好。
Confusion (混淆图)

要看懂混淆图必须要知道混淆矩阵的定义,如下图
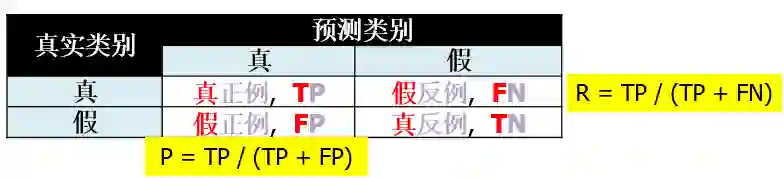
上图 P 代表查准率 (precision) 而 R 代表查全率 (recall),顾名思义,查准率就是查准的 (查出东西多少是有用的就是准),而查全率就是查全的 (有用的东西有多少被查出就是全)。对于二分类问题,可将样例根据其真实类别与模型预测类别的组合划分为真正例 (true positive, TP),真反例 (true negative, TN), 假正例 (false positive, FP) 和假反例 (false negative, FN)。其中
预测类别的真假来描述“正例反例”,如果“预测为真”就是“正例”,如果“预测为假”就是“反例”。
真实类别和预测类别的同异来描述“真假”,如果“相同”就是“真”,如果“不同”就是“假”。
真正例就是预测类别为真且和真实类别相同,真反例就是预测类别为假且和真实类别相同,假正例就是预测类别为真但和真实类别不同,假反例就是预测类别为假但和真实类别不同。
再回到上图,有四个混淆矩阵,分别是训练、验证、预测和总矩阵,我们需要关注一个,但发现它是一个 3 乘 3 而不是 2 乘 2 的矩阵,原因在于灰色和蓝色是加总的数,我们先把注意力再缩小到红色和绿色,其中
绿色代表分类正确,粗体数字是正确个数,正常数字是正确率
红色代表分类错误,粗体数字是错误个数,正常数字是错误率
但是正确包括 TP 加上 TN,错误包括 FP 加上 FN。仔细一看 Maltab 里面的混淆矩阵和一般惯例混淆矩阵互为转置,因为 output class 是预测类别,而 target class 是真实类别,那么以训练混淆矩阵为例,我们来验证一下 Matlab 计算的是否准确
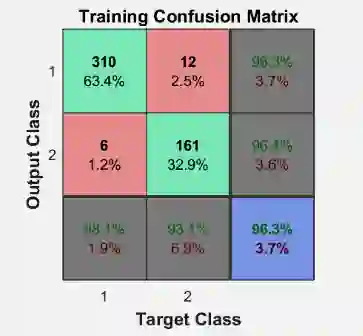
从上图我们知道:
TP = 310, FP = 12, FN = 6, TN = 161
N = TP+FP+FN+TN = 489
TP% = 310/489 = 63.4%
FP% = 12/489 = 2.5%
FN% = 6/489 = 1.2%
TN% = 161/489 = 32.9%
P = TP/(TP+FP) = 310/(310+12) = 96.3%
R = TP/(TP+FN) = 310/(310+6) = 98.1%
Total P = TP%+TN% = 63.4%+32.9% = 96.3%
几个公式不如一张图解释的清楚:

ROC 图

ROC 全名叫做 Receiver Operating Characteristic,而 ROC 图描绘的是真正例 TP 和假正例 FP 之间的关系,我们当然希望 TP 越大 FP 越小,根据公式,它们的比率
TP rate = TP/(TP+FP)
FP rate = FP/(TP+FP)
TP rate 越接近于 1,FP rate 越接近于 0,就越好。完美的测试结果是左上角的那个点 (横坐标是 0,纵坐标是 1),从图上看,神经网络的训练、验证和测试结果都非常好。
进行和上一章一样的操作,自动生成的代码如下:
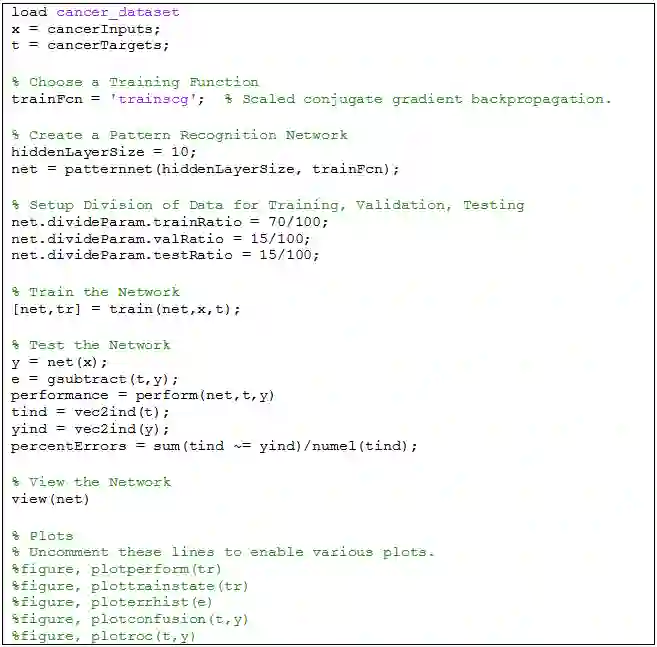
细心的同学可以发现,这段代码和 ANN 回归那段代码非常相似,而结构几乎一模一样,包括引入数据,确定算法,创建网络,训练网络,测试网络,可视化网络,可视化最终结果。整个代码逻辑非常清晰,如果在哪个步骤需要小改,可以参考小节 3.2 的内容。
最后来看看用 view(net) 可视化神经网络图
除了第三、四章的监督学习下的回归和分类问题,ANN 可以解决无监督学习下的聚类 (clustering) 问题。无监督学习问题只需要输入 X 和而不需要输出 y,在Matlab 里规定 X 要写成以下数组 (array) 格式
X = [7 0 6 6 1 0 1; 6 2 5 5 1 2 2];
把上面 X 当做是点在平面上的坐标,而聚类问题要解决的是将这些点聚成 2 类、3 类或者 k 类。
用 Matlab 的 GUI 玩转 ANN 聚类的步骤如下:
步骤 1 – 点击下图 Clustering app (等价于运行 nctool 函数)
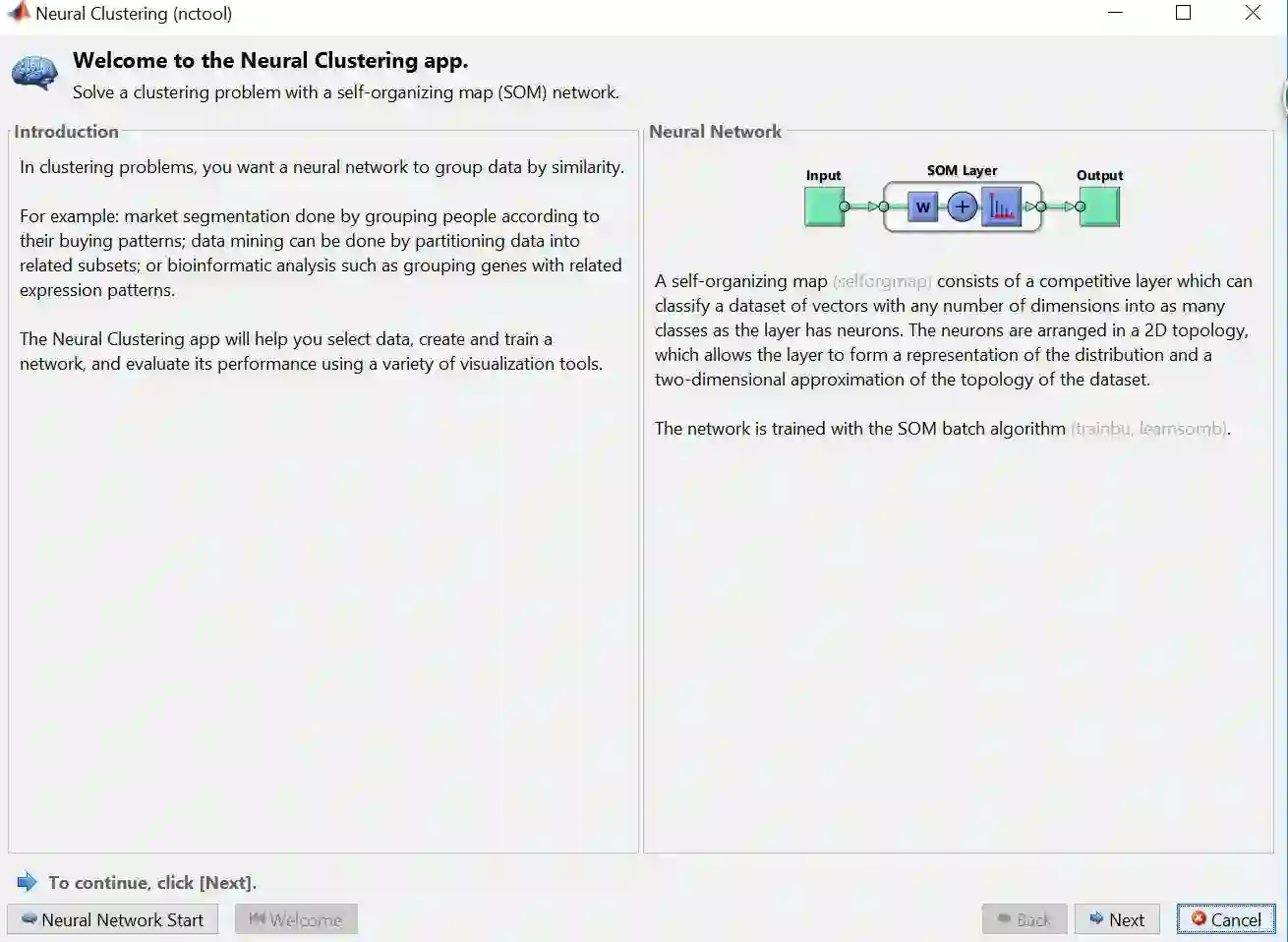
步骤 2 – 下图关于聚类 ANN 的介绍框出现,之后会先选择数据,再点击 Next
步骤 3 – 点击 Load Example Data Set 来选择 Matlab 里面自带的供你玩耍的数据
步骤 4 – 选择 Iris Flowers 再点击 Import
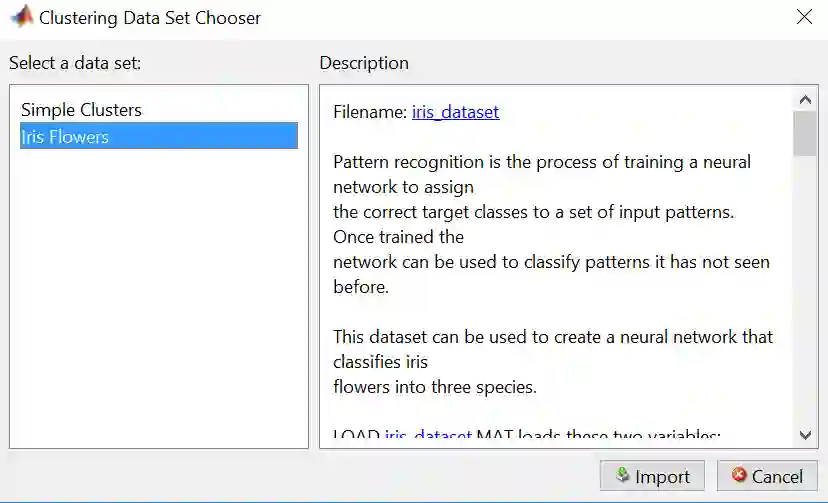
Iris Flowers 的数据明细如下:
irisInputs - a 4x150 matrix of four attributes of 1000 flowers.
1. Sepal length in cm
2. Sepal width in cm
3. Petal length in cm
4. Petal width in cm
irisTargets- a 3x150 matrix of 1000 associated class vectors defining which of three classes each input is assigned to. Classes are represented by a 1 in one ofthree rows, with zeros in the others.
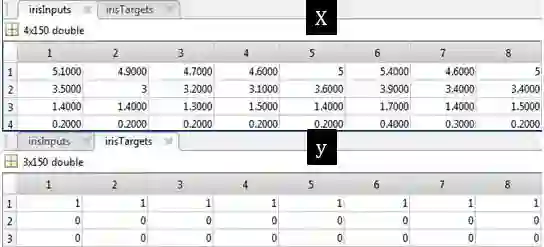
这套数据是最经典的鸢尾花数据,也是经常被数据科学家拿来举例。从上表可看出总共有 150 个数据,其中 X 有 4 列,包括萼片长度、萼片宽度、花瓣长度、花瓣宽度,而 y 记录上鸢尾 (用 [1 0 0]T 表示) 、变色鸢尾 (用 [0 1 0]T 表示) 和维吉尼亚鸢尾 (用 [0 0 1]T 表示)。

这套数据也可以用来分类,因此有 y;但是现在是聚类问题,因此我们不用 y 的信息,就单单看 X 把它给聚类了。
注意:聚类问题不需要划分训练集、验证集和测试集。
步骤 5 – 默认的聚类 ANN (如彩图) 比较特殊,只有 1 层,最后是通过自组织映射 (self-organizing map, SOM) 来生成结果的。再点击 Next
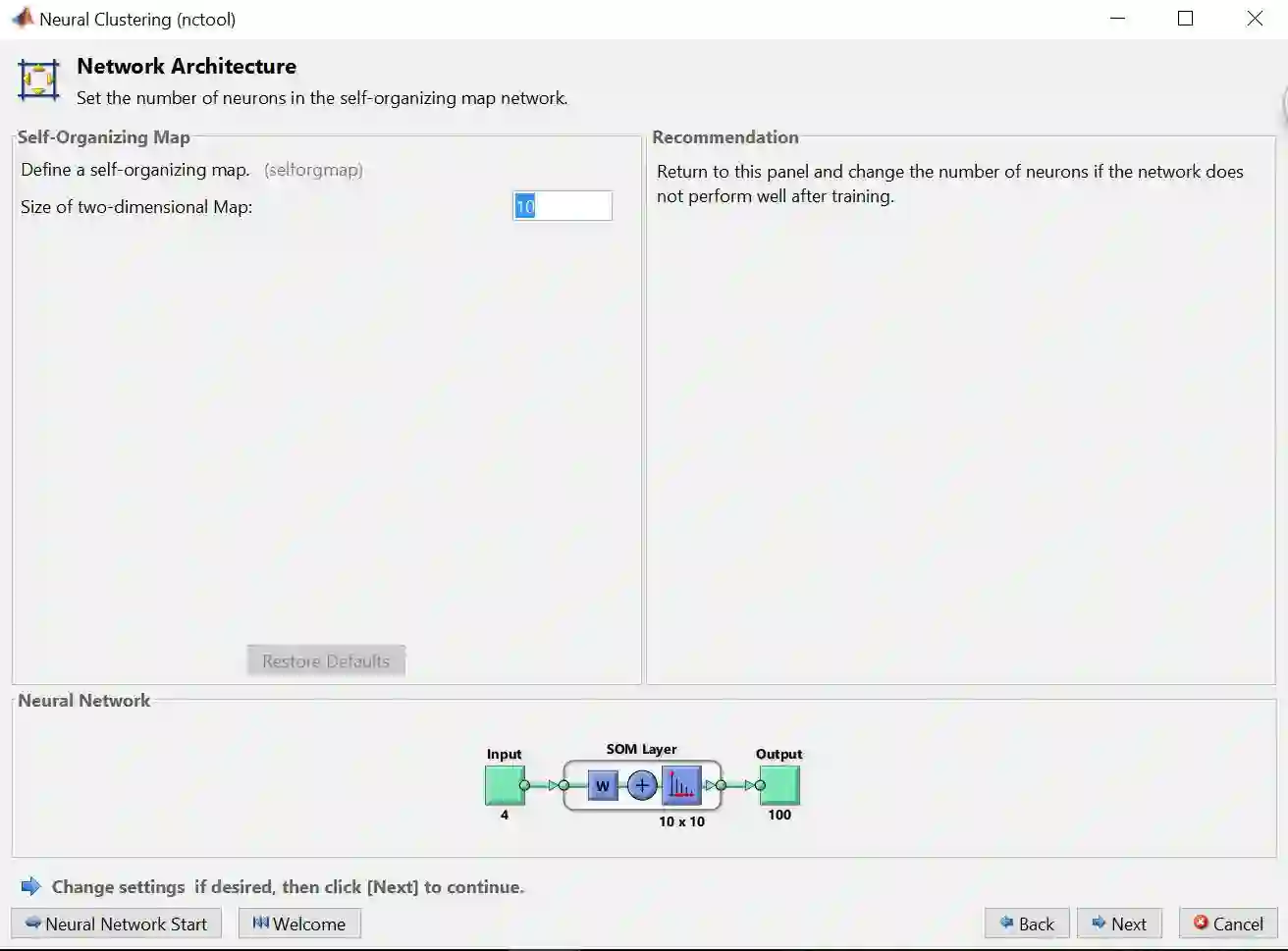
SMO 将最后得神经元组成一个网格 (grid) 形式,在本例是一个 10 乘 10 的二维网格,因此总共有 100 个神经元。SMO 中学习的目标是使网络的不同部分对输入模式有相似的响应。
步骤 6 – 选择训练算法 Batch Unsupervised (trainbu),再点击 Train
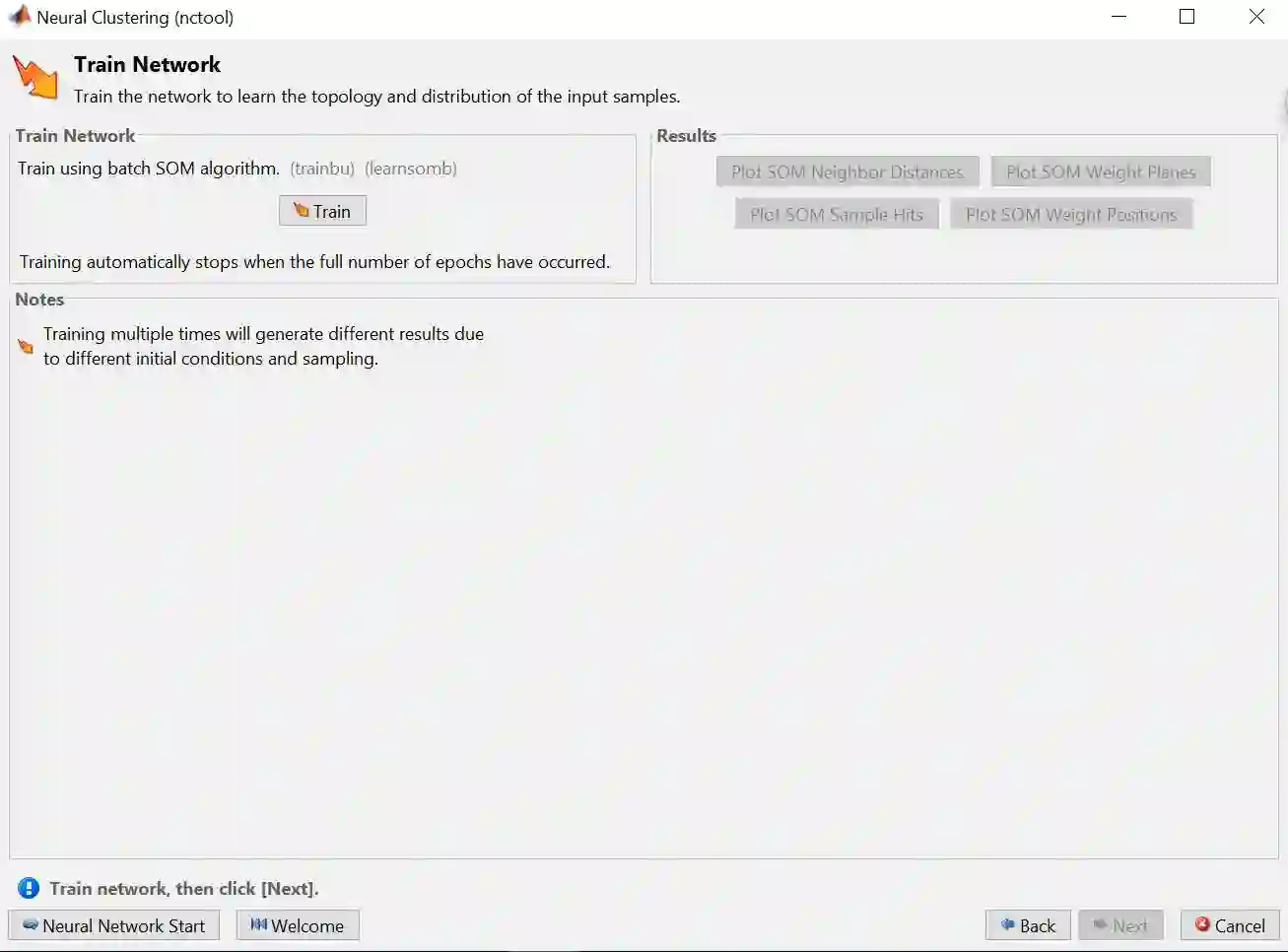
训练完之后得到下图。
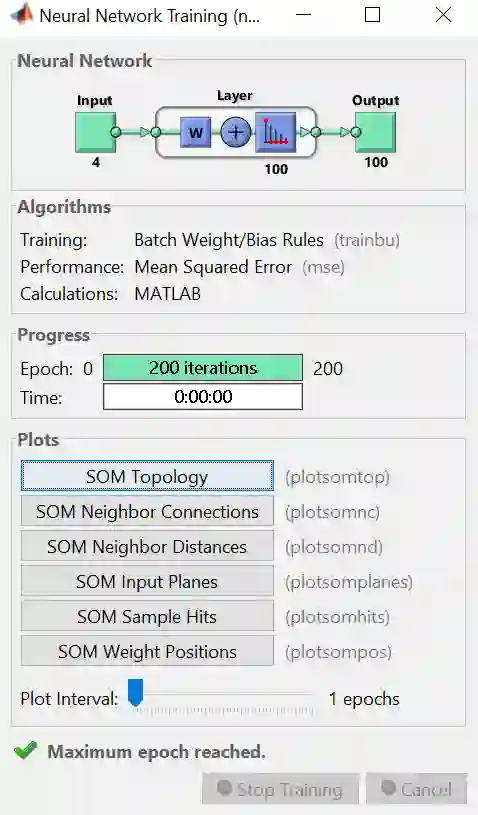
上图是训练完的结果概要,整个板上分 Neural Network, Algorithms, Progress 和Plots 四小块。
Neural Network 板上画出解决该问题的神经网络图
Algorithms 板上显示 BU 算法和 MSE 性能评估
Progress 板上展示算法需要 200 次迭代次数 (总共200次),用时几乎为零
Plots 板上有关于 SMO 的 6 种绘图可供展示
步骤 7 – 在上图 Plots Panel 里面分别点击那 6 个按钮得到以下关于 SMO 的 6 幅图,分别是:
Topology (拓扑图)
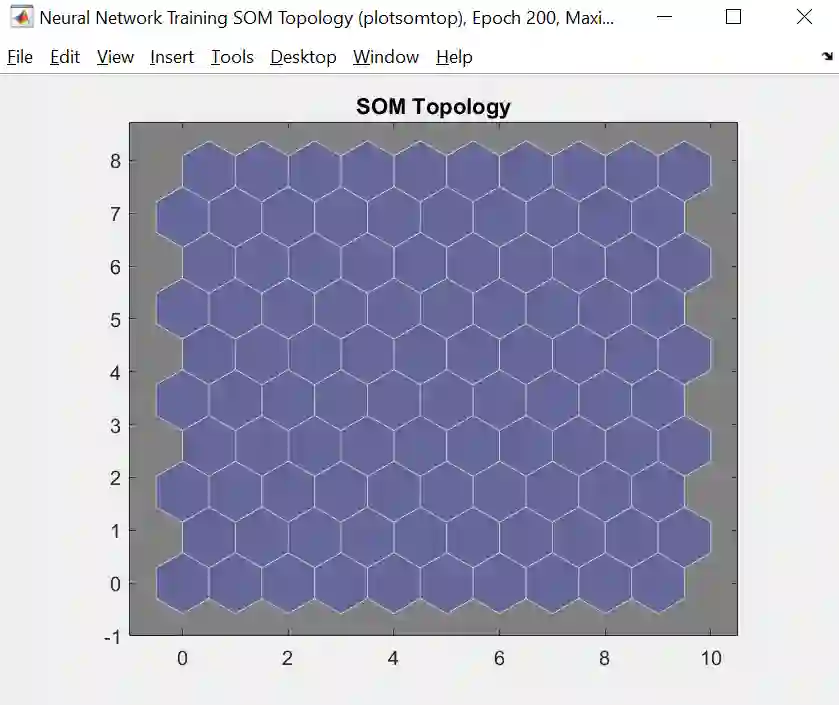
拓扑图其实就是创建一个二维网格图,每一个六边形代表一个神经元,在聚类时每个神经元会对应一个中心点 (centroid),因此每个神经元可看成一个聚团 (cluster)。每个数据会找到离自己最近的中心点,即那个聚团,从而赋给那个神经元。如样本分布图所示。
Sample Hits (样本分布图)

该图是聚类数据之后的可视化,每个神经元里面的数字代表其包含数据的个数。由于数据是个 4 维变量,而拓扑图是个 2 维平面图,因此只能借助样本分布图来做到可视化。
Neighbor Connection (邻接图)

邻接图是将神经元 (聚团) 连接 (用红线) 起来的图,将本例 150 个数据分成 100 个聚团显然太细了。从样本分布图中看出,聚团里含最多数据个数的也只是 6,很多都只含 1 个数据甚至没有,这种过于散的聚类没有任何意义。因此我们可以计算出聚团之间的距离,如邻距图所示。
Neighbor Distance (邻距图)
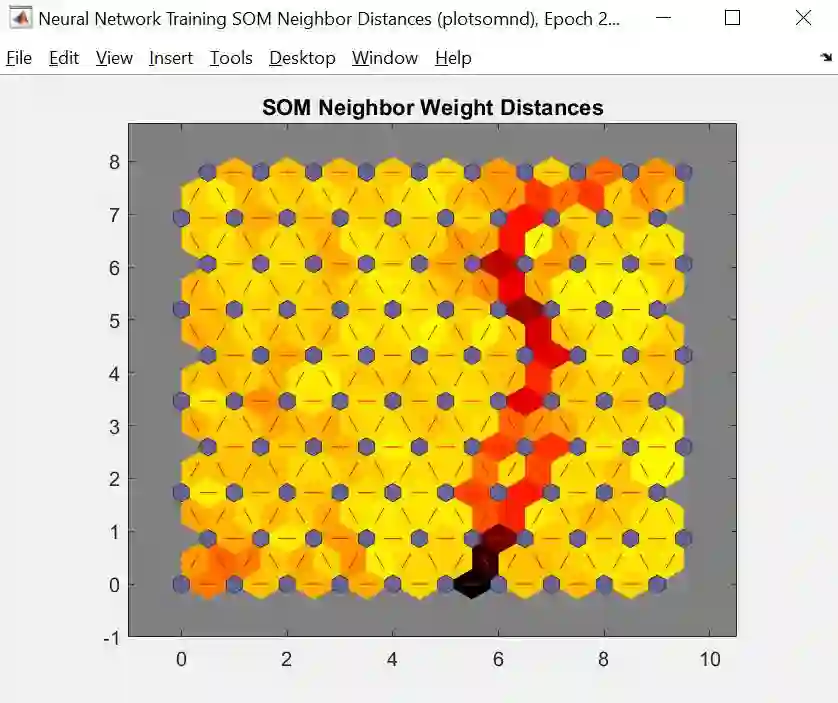
邻距图将神经元(聚团) 之间距离用颜色来表示,颜色越浅距离越短,颜色越深距离越长,从上图看,SOM 神经网络将数据聚成了 2 类 (这个结果不大理想,因为我们知道其实这些鸢尾花应该有 3 类)。
Input Panel (输入板图)
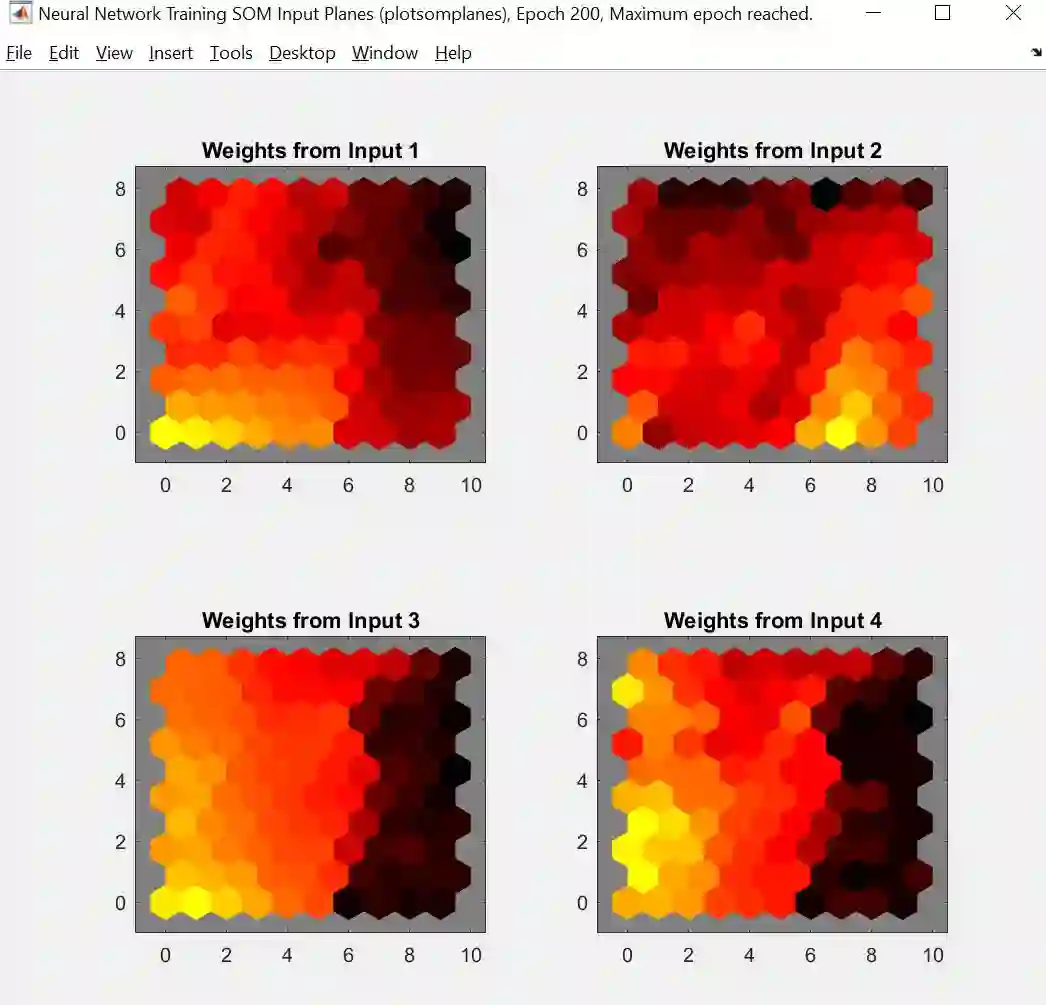
输入板图画出 X 每一个维度 (本例有四个维度) 的权重的拓扑图,颜色越浅权重越小,颜色越深权重越长。如果两个维度之间的颜色模型很相近,那么它们的相关性很高,从上图中第二行两张小图看出,第三维度 (花瓣长度) 和第四维度 (花瓣宽度) 的数据很相关。换句话说,花瓣越长也就越宽。
Weight Positions (权重位置图)

权重位置图只画出数据前二个维度的可视图。比如 X = [1 2 3 4],因为四维图不可能画出来,只能舍去后两维而画出 X = [1 2] 的图。绿点代表数据点,而蓝点代表聚团点,红线就是上面邻接图的连接神经元的红线。
进行和前两章一样的操作,自动生成的代码如下:
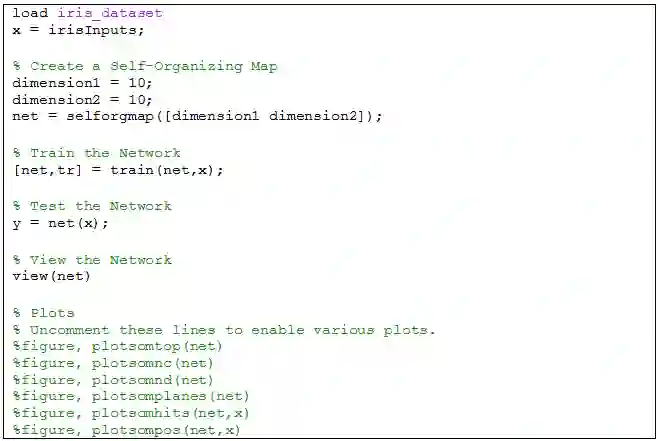
聚类代码更为简单,步骤如下
只需要引进 X
制定 SMO 的网格维度,构建网络
训练网络和测试网络
可视化网络和最终结果
整个代码逻辑非常清晰,如果在哪个步骤需要小改,可以参考小节 3.2 的内容。最后来看看用 view(net) 可视化神经网络图
人工神经网络 (artificial neural network, ANN) 属于机器学习 (machine learning, ML) 里的课题,而深度神经网络 (deep neural network, DNN) 属于深度学习 (deep learning, DL) 里的课题。ML 包含 DL,DNN 就是多层的 ANN。
啥也不说了,看看下面一幅图就知道自己有多少东西还要继续学习下去了。

其中用于图像处理的卷积神经网络 (convolutional neural network, CNN),用于语音处理的循环神经网络 (recurrent neural network, RNN) 和长短期记忆 (long short term memory, LSTM),和用于半监督学习和强化学习的生成式对抗网络 (generative adversarial network, GAN) 是 DNN 里面的重中之重。作者现在也刚刚涉足 DL,但发现其实各种各样神经网络的东西还是蛮直观的,花点时间慢慢学慢慢写,我只要能学明白就保证写出来让你们明白。Stay Tuned!




