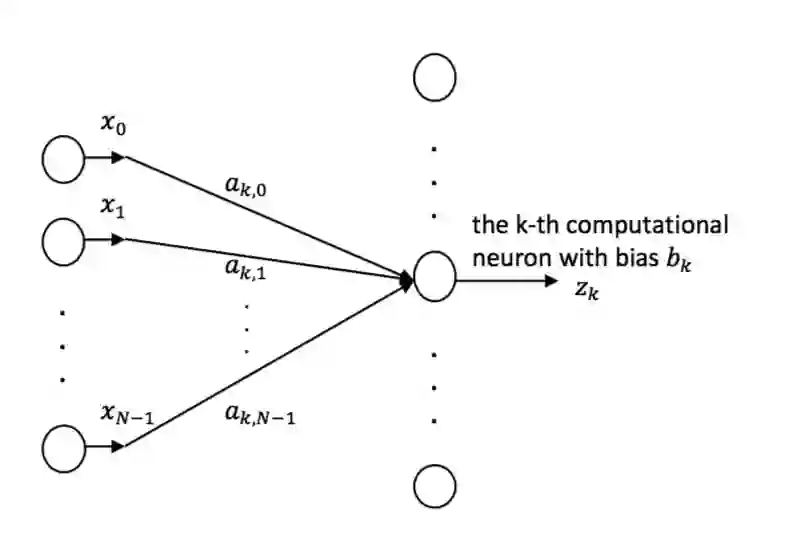
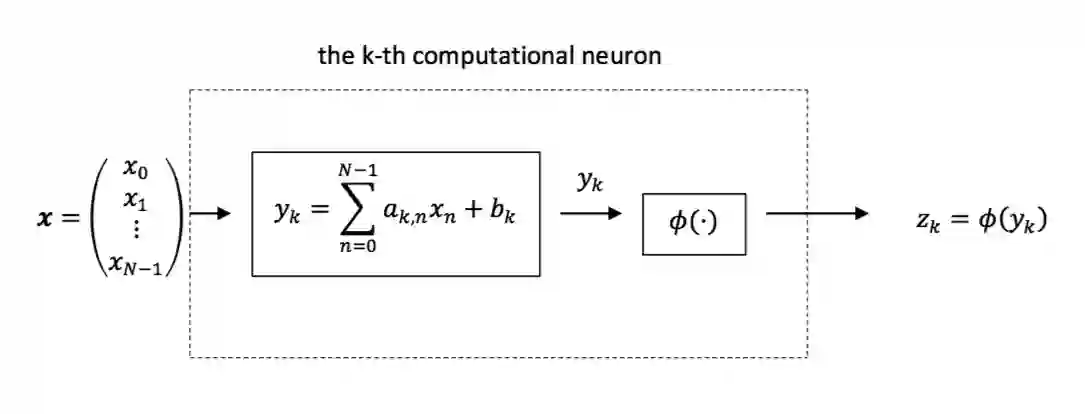
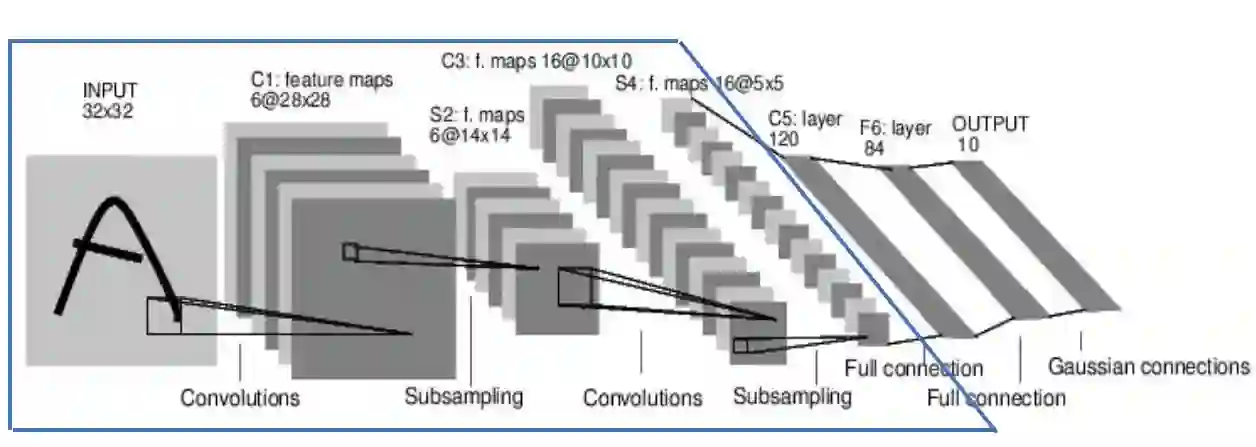
The model parameters of convolutional neural networks (CNNs) are determined by backpropagation (BP). In this work, we propose an interpretable feedforward (FF) design without any BP as a reference. The FF design adopts a data-centric approach. It derives network parameters of the current layer based on data statistics from the output of the previous layer in a one-pass manner. To construct convolutional layers, we develop a new signal transform, called the Saab (Subspace Approximation with Adjusted Bias) transform. It is a variant of the principal component analysis (PCA) with an added bias vector to annihilate activation's nonlinearity. Multiple Saab transforms in cascade yield multiple convolutional layers. As to fully-connected (FC) layers, we construct them using a cascade of multi-stage linear least squared regressors (LSRs). The classification and robustness (against adversarial attacks) performances of BP- and FF-designed CNNs applied to the MNIST and the CIFAR-10 datasets are compared. Finally, we comment on the relationship between BP and FF designs.
翻译:在这项工作中,我们建议采用一种可解释的进料向前(FF)设计,而没有任何BP作为参考。FF设计采用了一种以数据为中心的方法。它根据前一层输出的数据统计数据,以单程方式从上层产生网络参数。为了构建进量层,我们开发了一种新的信号转换,称为Saab(调整后Bias的子空间应用)转换。它是主要组成部分分析的一种变式,增加了一种消除启动非线性性的偏向矢量。在级联中的多层Saab变产生多个相振层。关于完全连接的(FC)层,我们用多阶段最小平方反射器的级级联状构建这些当前层的网络参数。在MNIST和CIFAR-10数据集中应用的BP-和FF设计的CNN(对抗性攻击性攻击性能)的分类和稳健性能。最后,我们比较了BP和FF设计之间的关系。