深度学习注意力机制-Attention in Deep learning-附101页PPT
导读

-
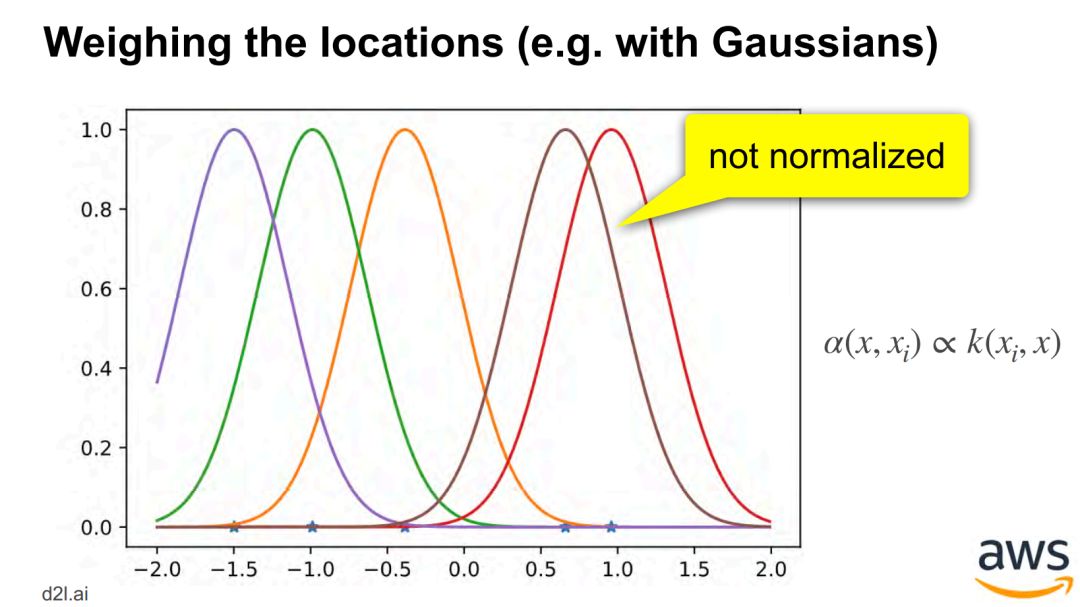
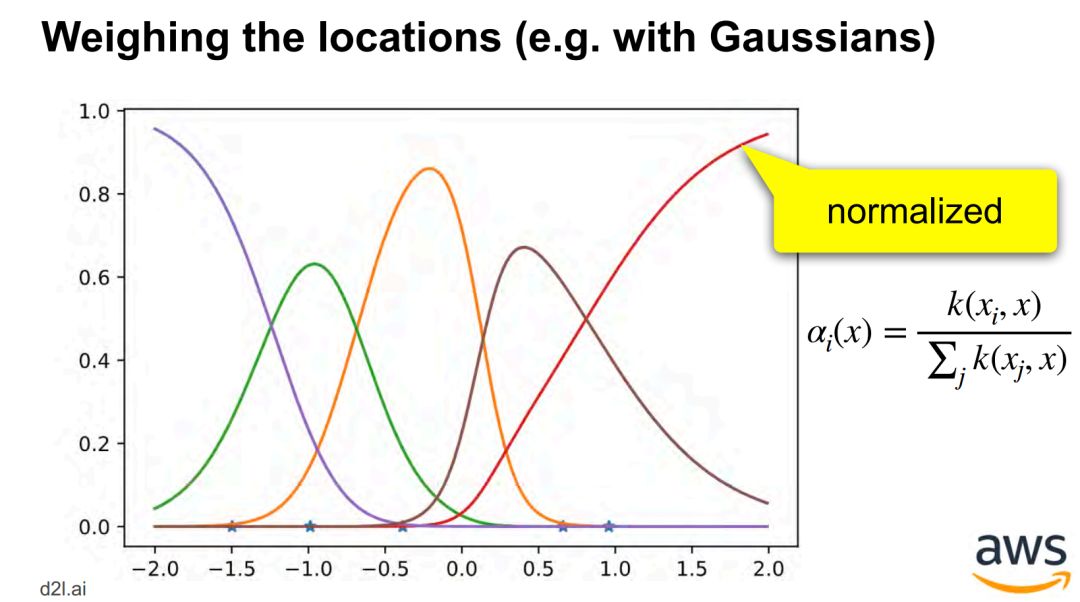
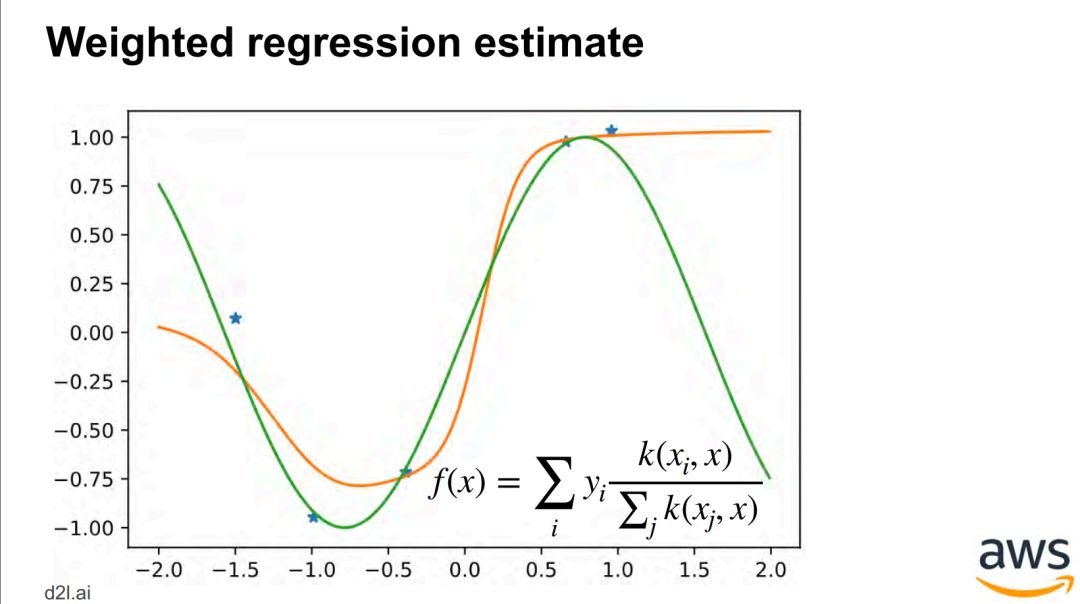
单目标 - 从池化 pooling 到注意力池化 attention pooling -
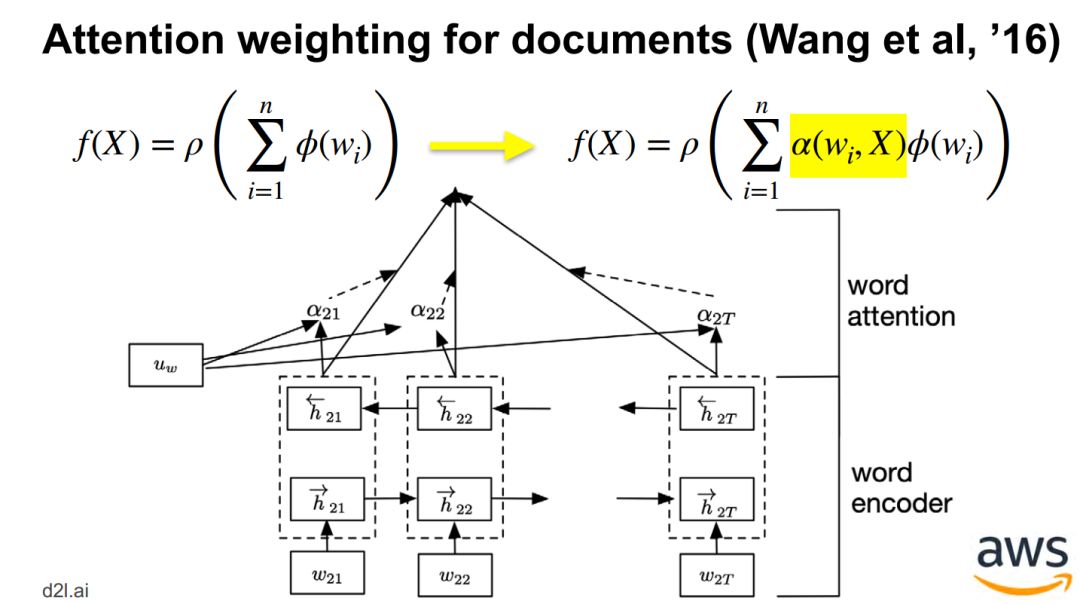
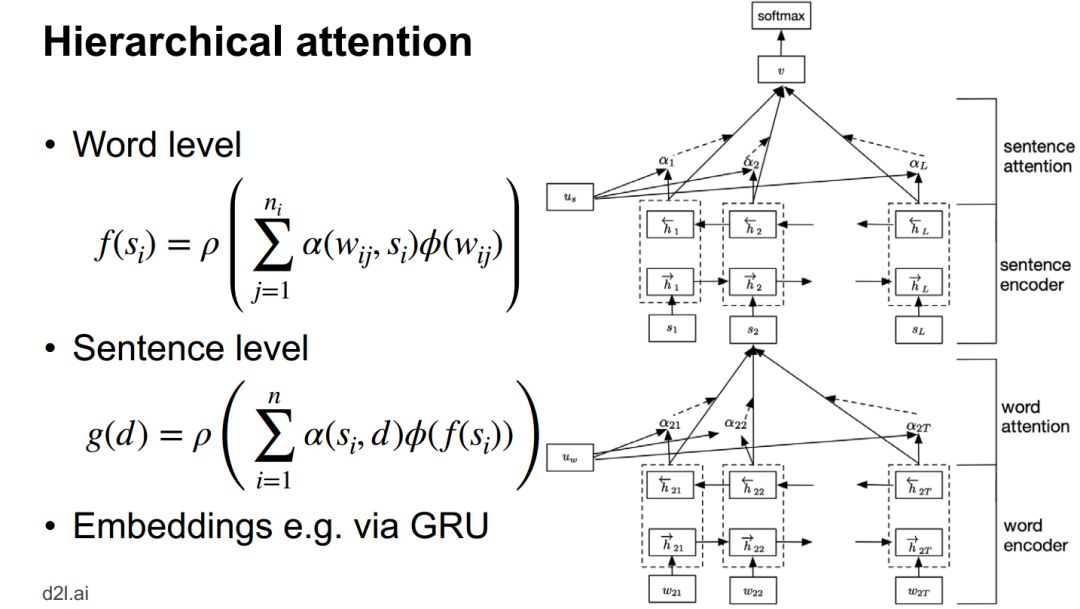
层次结构 - 分层注意力网络 Hierarchical attention network
-
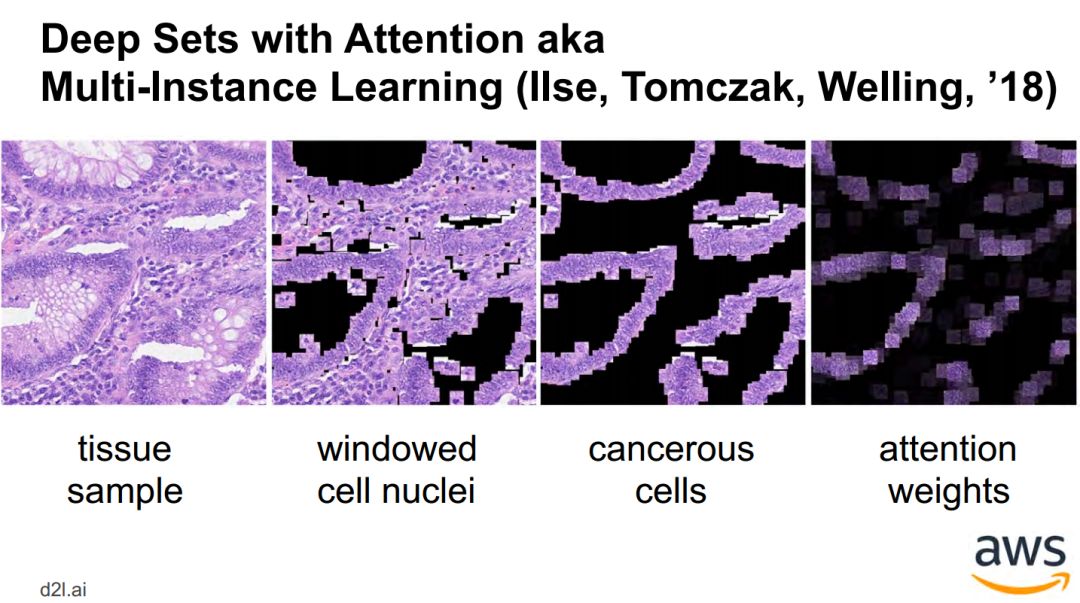
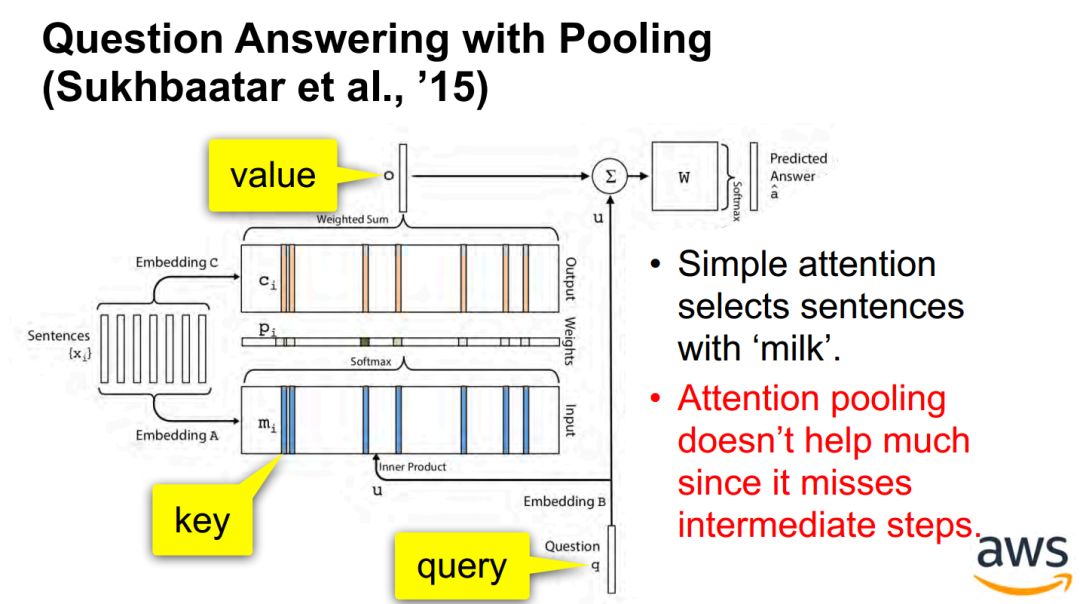
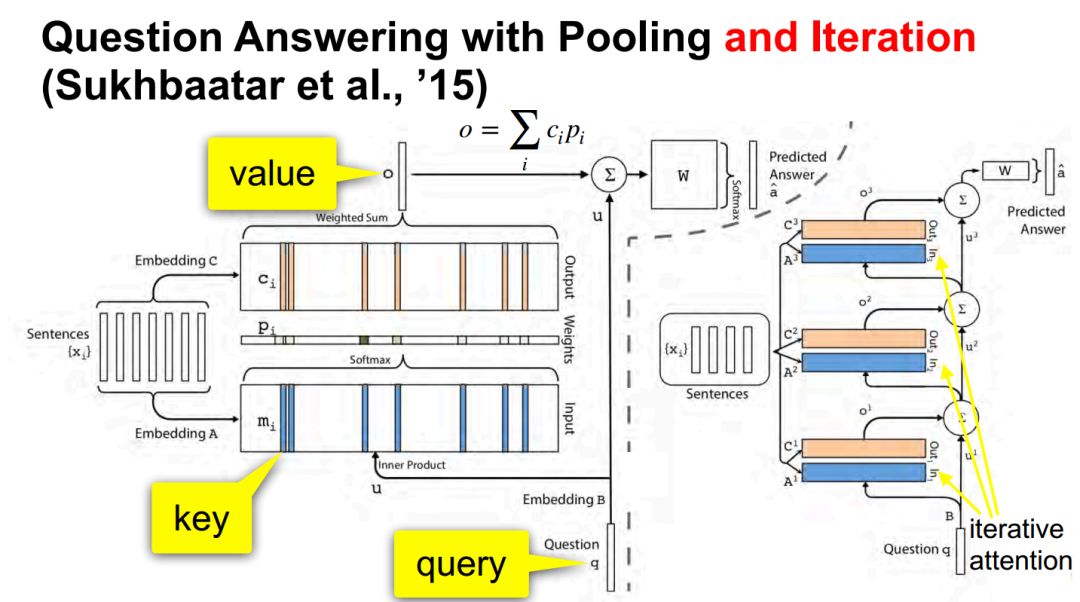
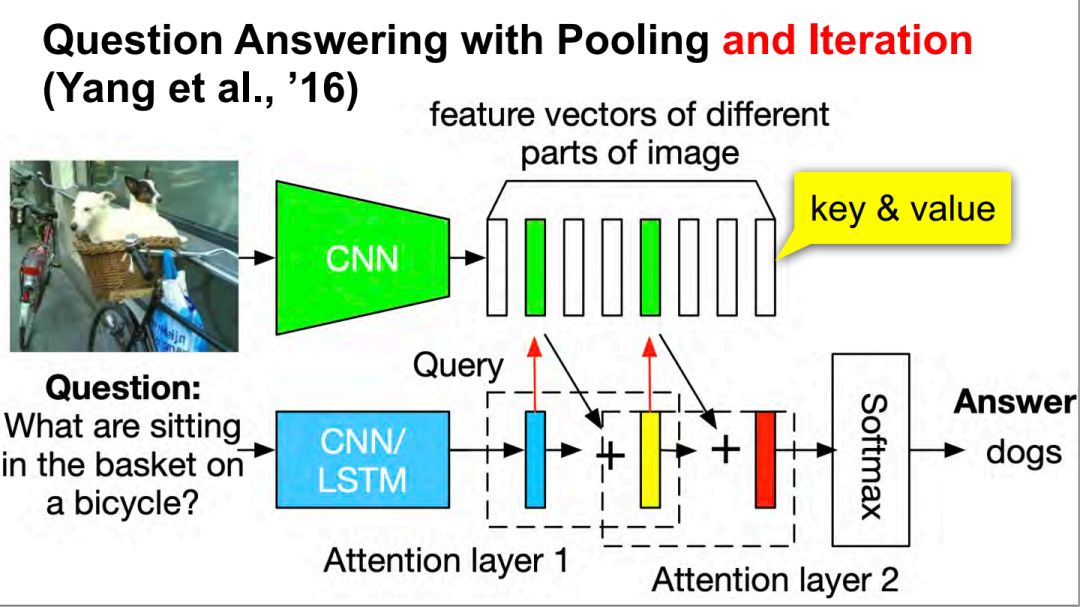
问答 Question answering / 记忆网络 memory networks
-
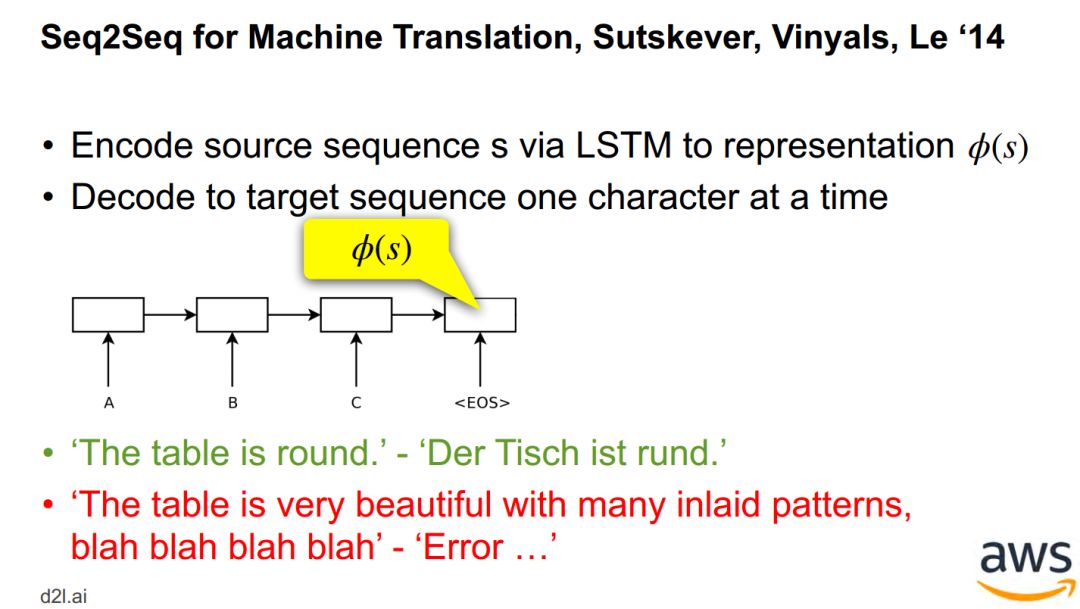
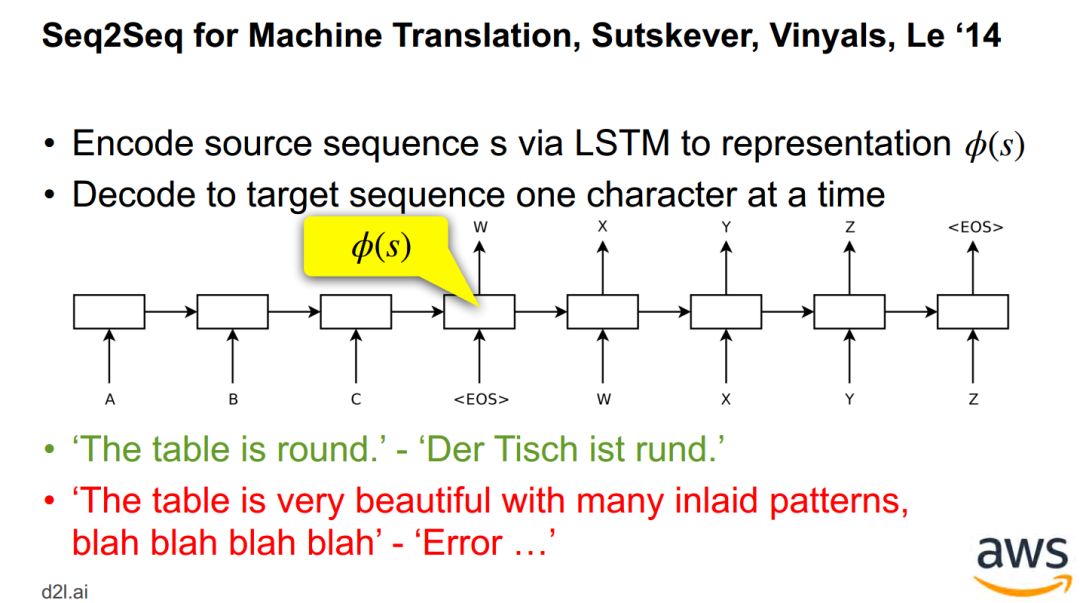
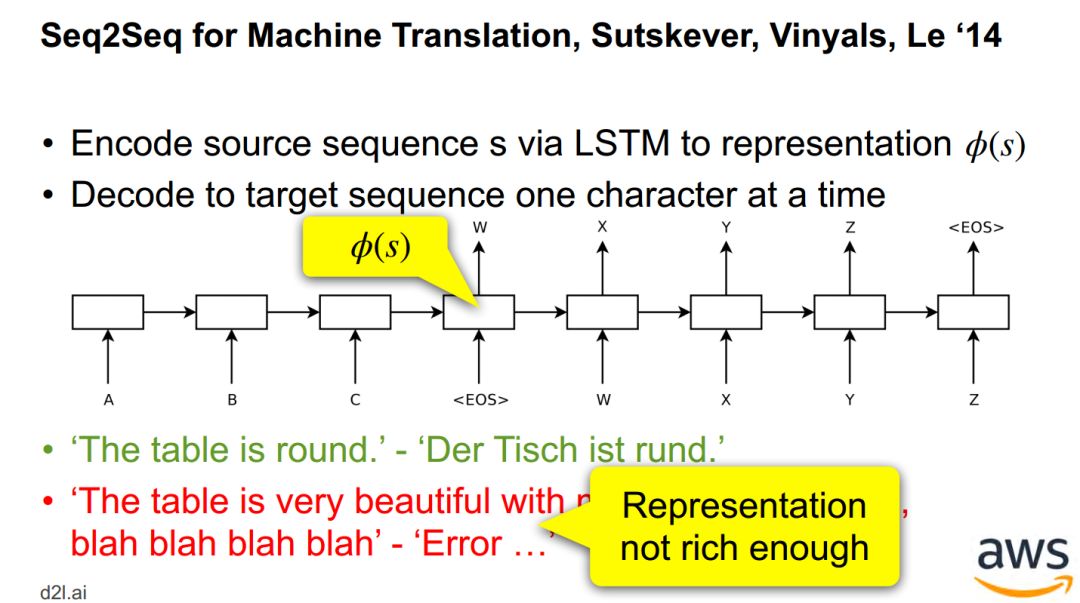
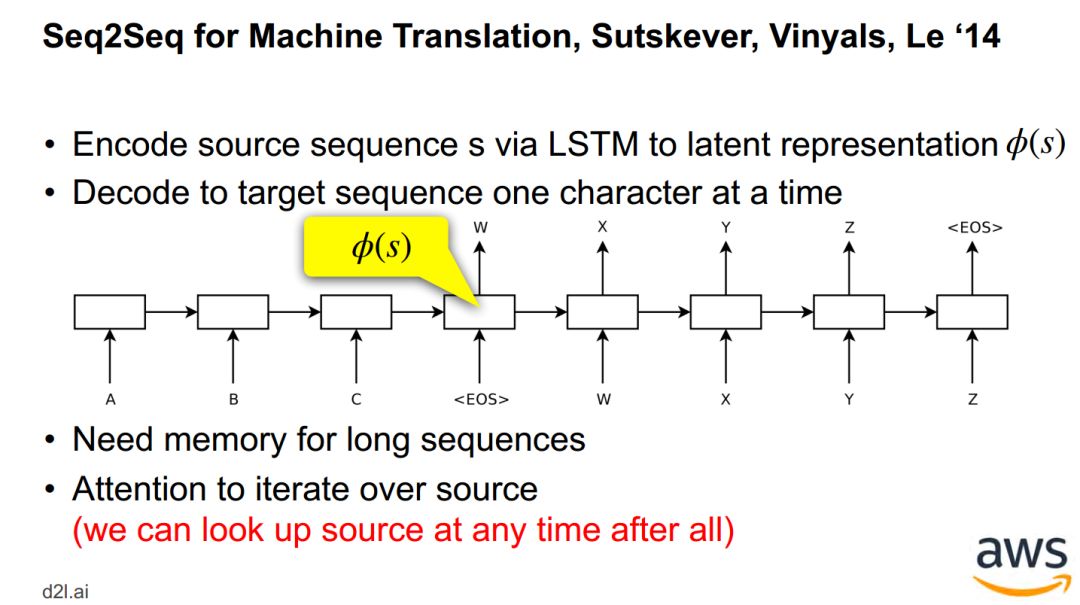
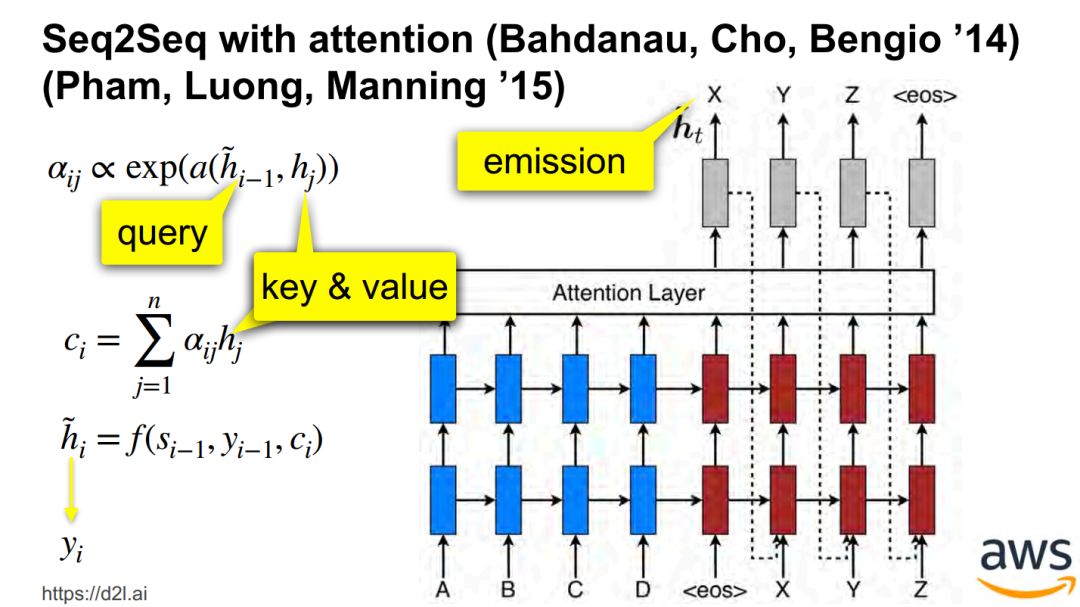
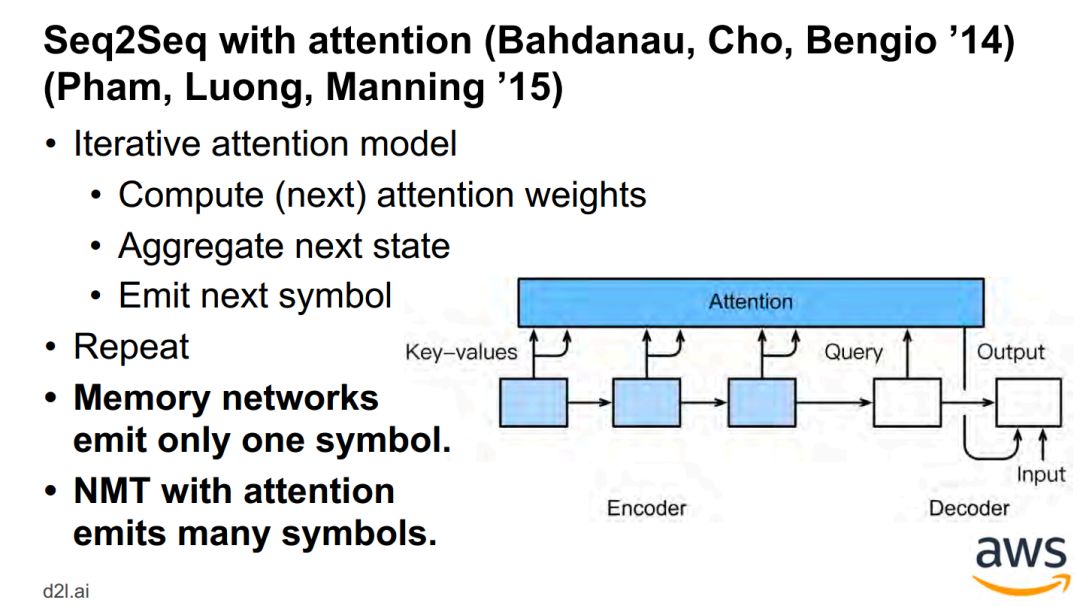
神经机器翻译
-
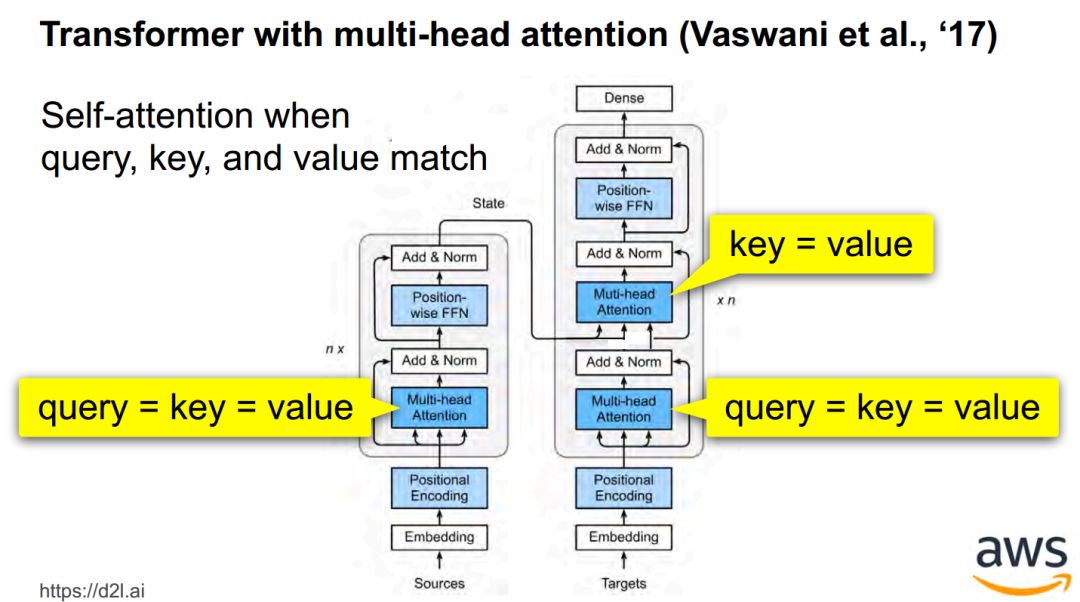
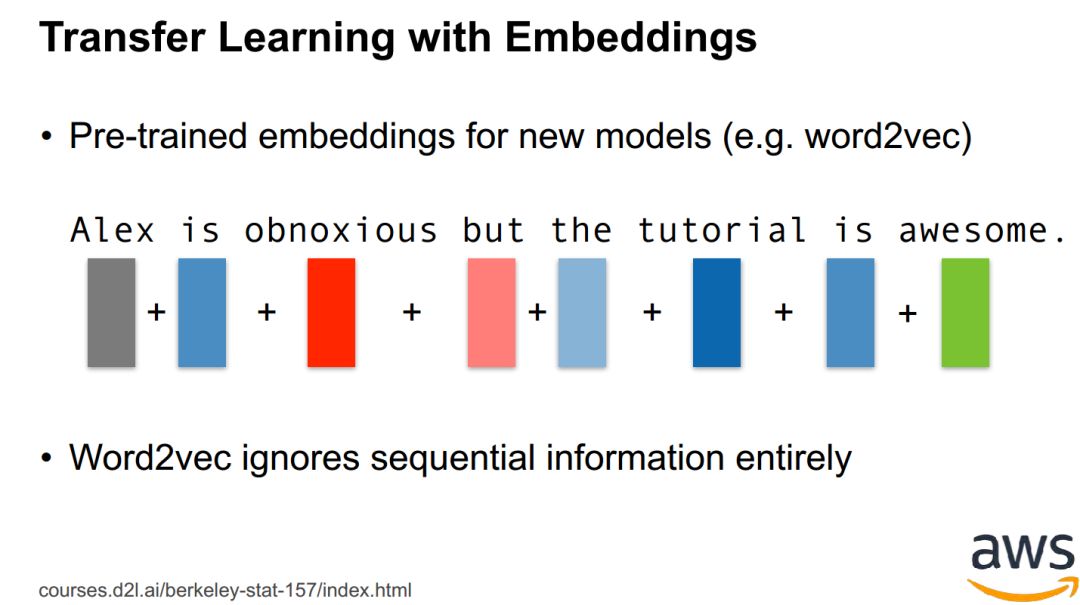
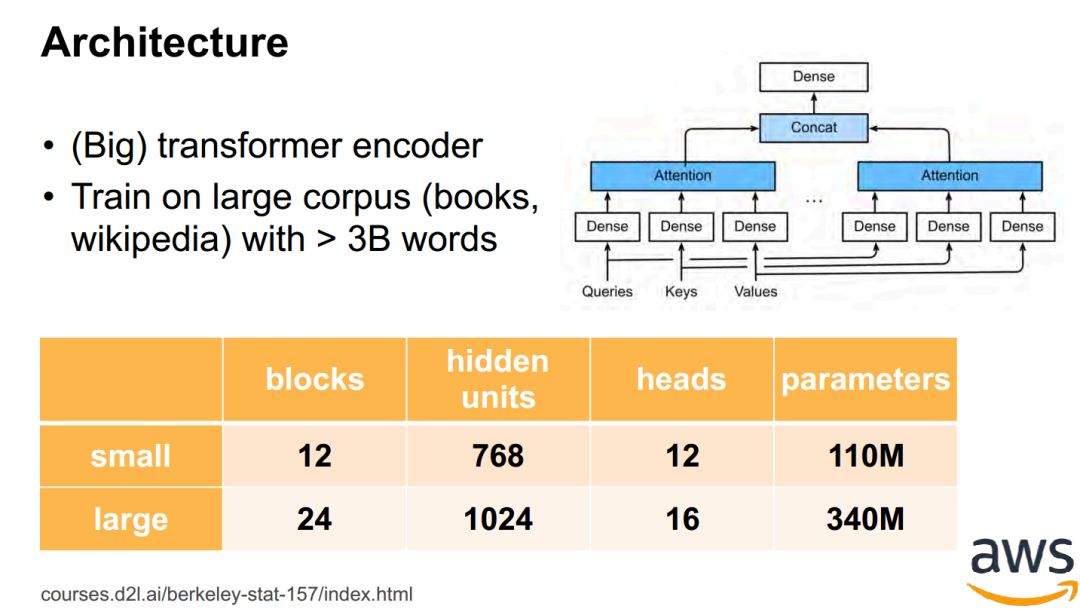
Transformers / BERT -
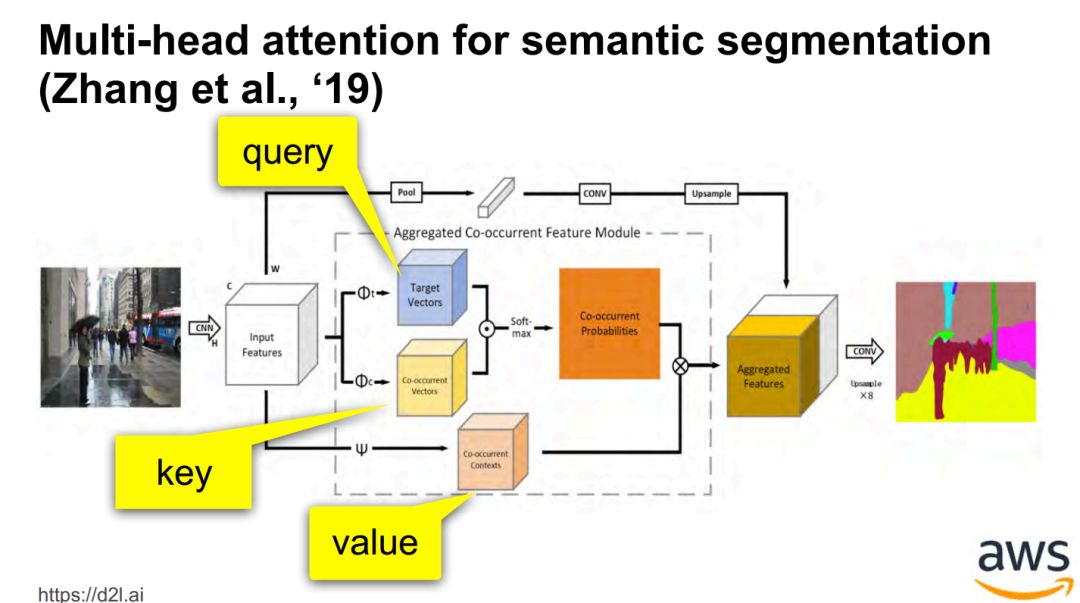
Lightweight, structured, sparse
-
后台回复“ADL” 就可以获取完整版《Attention in Deep learning》的下载链接~




















-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
登录查看更多
相关内容

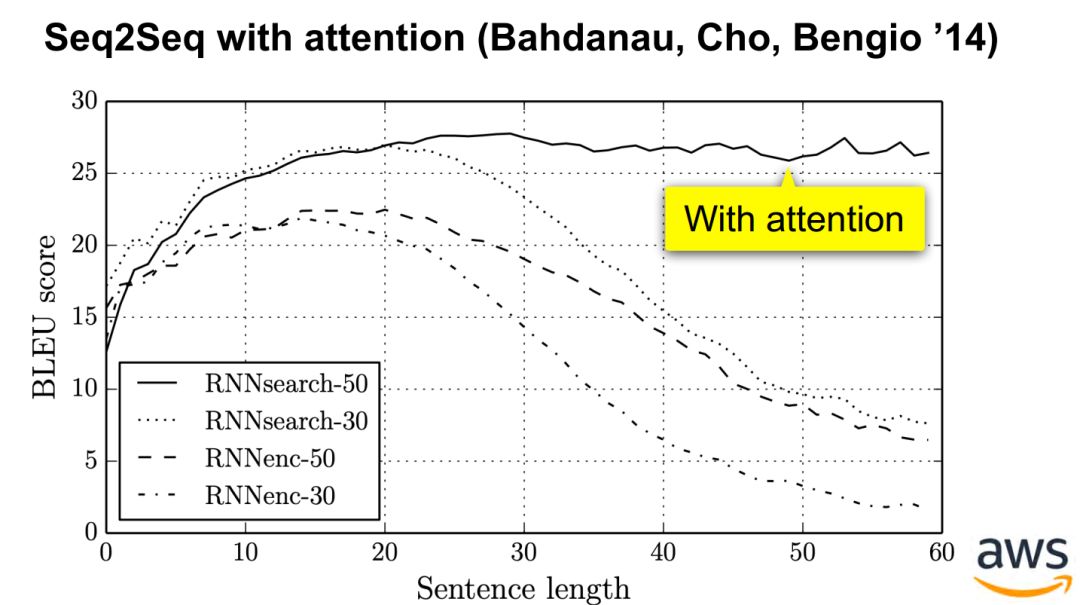
Attention机制最早是在视觉图像领域提出来的,但是真正火起来应该算是google mind团队的这篇论文《Recurrent Models of Visual Attention》[14],他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 [1]中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
专知会员服务
68+阅读 · 2019年6月11日




相关VIP内容
专知会员服务
68+阅读 · 2019年6月11日
相关资讯