CIIS2018演讲实录丨哈尔滨工业大学车万翔:任务型对话系统研究进展
声明:本文转载自公众号 中国人工智能学会,已获得授权
本文整理了来自哈尔滨工业大学社会计算与信息检索研究中心车万翔教授的主题为《任务型对话系统研究进展》的精彩演讲。

车万翔
哈尔滨工业大学
社会计算与信息检索研究中心教授
以下内容根据速记进行整理
经过车万翔老师本人校对
大家好,我叫车万翔,来自哈尔滨工业大学,今天很高兴和大家分享任务型对话系统的一些技术现状以及我们的一些研究进展。对话系统最早可以追述到图灵测试,后来并没有太大的进展,直到苹果公司的SIRI开始才有大规模的应用,之后谷歌、微软、百度等公司相继开发了各自的对话机器人。

我们将对话系统分成四个主要的功能:第一个是任务型对话系统,也可以认为其他都是非任务型对话系统,又可以进一步划分为聊天类、知识问答类,以及推荐类,这几个类型的机器人我们研究中心都在做。我今天主要介绍任务型的对话系统。
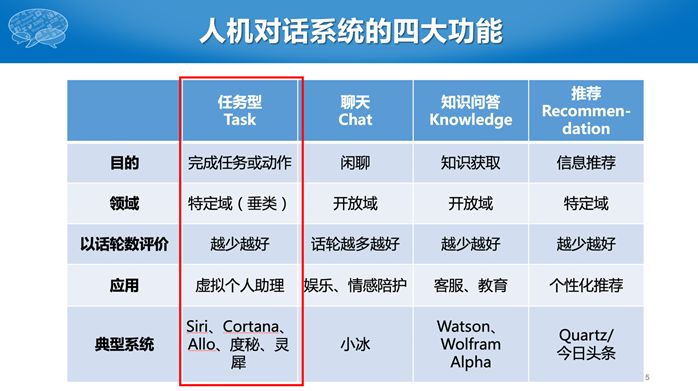
任务型的对话机器人有很多用处,如智能汽车控制、个人助理等。任务型对话系统主要构成包括三模块:第一个模块为自然语言理解(这个名字不是特别好,因为我们做自然语言处理整个大方向也叫自然语音理解,这个名字是在人机对话领域约定俗成的,也可以叫口语语言理解),它主要实现两个功能,一个是意图识别,一个是语义槽填充。比如“请帮我订一张去北京的机票”,意图是订机票,语义槽为“到达地=北京”。
第二模块为对话管理,又包括对话状态跟踪和对话策略优化。对话状态一般表示为语义槽和值的列表,如有出发地、到达地等。通过自然语言理解,我们知道到达地是北京,出发地和出发时间仍然是空,这就是当前的对话状态。获得当前对话状态后,我们要进行策略优化,选择下一步采用什么样的策略,也叫动作。动作有很多种,我可以问出发时间,也可以问出发地。如此时可以寻问出发地。
第三部分为自然语言生成。在对话系统里面语言生成工作相对比较简单,通过写模板即可实现。比如要询问出发地,就直接问“请问你从哪里出发”,然后经过 TTS 系统给用户反馈。整个过程可以一直循环下去,随着每次提问的不同,对话状态也随之变化,然后采用不一样的回复策略。
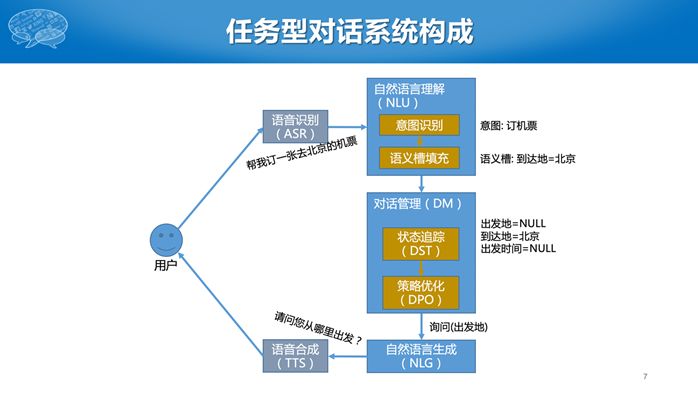
下面介绍这几个模块的技术发展趋势。其中,意图分类可以看成是文本分类,而且是短文本分类问题。早期采用SVM等线性分类器,最近主要采用深度学习方法,比如CNN或者CNN-LSTM。有人说深度学习需要大数据,对话领域数据不多,为什么还采用深度学习技术呢?这主要归功于预训练模型,使得深度学习在只有较少数据的情况下,仍然可以取得比较好的效果。

语义槽填充是要识别句子中规定好的语义槽的值。可以看成序列标注问题,即标注出序列中每个词的标签,如出发地的开始或者出发地的继续等。传统的序列标准模型是CRF,现在双向LSTM之后还可以再加CRF模型。
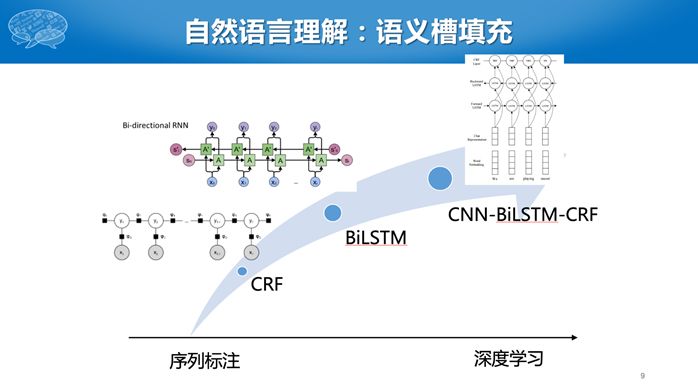
对话管理负责识别出下一步采用什么动作。这个问题比较麻烦就是我们很难标注出数据,告诉对话系统每一步采用什么动作,因为很多时候没有标准答案。比如刚才那个例子,询问出发时间还是出发地都是合理的动作,只有对话全流程结束后才知道该步骤采取的动作是否合适。这是强化学习擅长解决的问题。早期对话管理的研究往往采用基于规则的方法,后来出现基于有指导,即标注每一步所谓的标准动作,目前研究主要集中在基于强化学习的方法,其中的奖励可以是对话轮数、任务完成情况等。
最后是对话生成,通常采用基于模板的简单方法,也可以采用语言模型,目前也出现了基于深度学习的模型。与之前基于序列到序列的深度学习模型不同,这里采用的是状态到序列的模型。基于深度学习的模型还多处于研究阶段,实际应用中还是多采用基于模板的方法。
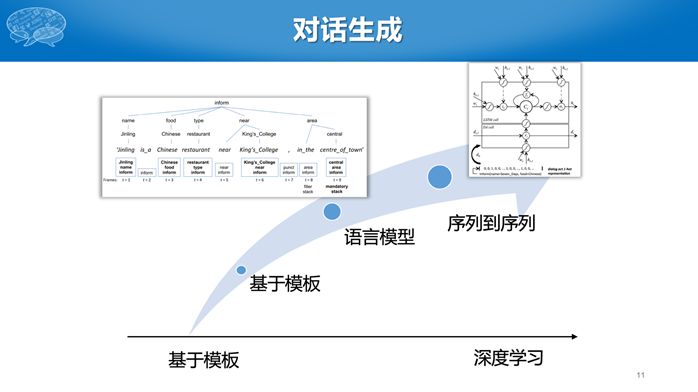
我们可以看到,用户即开发者如果想构建自己的对话系统,都需要这实现这三个模块,大大增加了开发的难度。有没有可能帮助用户,快速的构建自己的对话系统呢?用户只需要提供各自领域相关的数据,无需关注太多的技术细节。为此我们开发了对话技术平台。实际上,整个的产业界,包括微软、谷歌、脸书和百度等都在这做方面工作。如微软开发的LUIS系统,脸书收购的wit.ai,谷歌收购的api.ai,百度自研的UNIT以及收购的kitt.ai等等这些都在做对话平台。

我们的对话技术平台(DTP)也是这样的网站,网址是:http://dtp-cloud.cn,开发者若想做一个对话系统,不需要亲自实现刚才介绍的三个模块,只要上传数据并进行标注,最后就可以提供对话API,来回答用户的问题或者进行对话。背后是我们积累多年的自然语言处理技术。
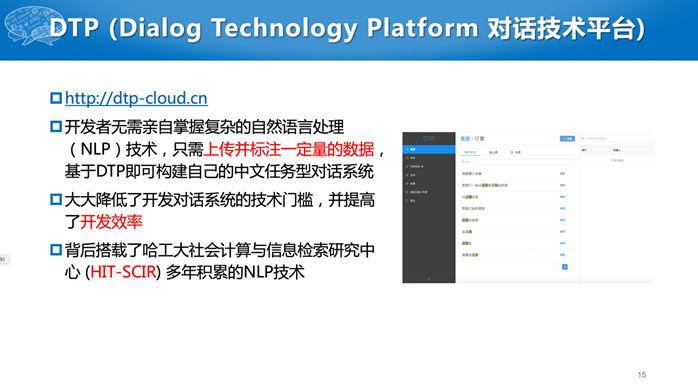
DTP主要帮助用户完成语言理解和对话管理功能,基于我们的LTP和大词林系统,然后提供给开发者应用。

与其他类似的系统相比,我们优势主要有三个:第一,对中文支持的更好;第二,有强大的多轮交互能力;第三,跟大厂相比我们专业定制能力更好。如果开发者要实现一个个性化对话系统,谷歌、百度不可能来一个工程师给提供定制化服务。如果出一定经费,我们还是可以做这个事的。

比如,我们做了一个个性化体检机器人。一般去医院体检需要选一个套餐,这种选套餐的形式有两个问题:其一就是可能会包含一些你不需要检的项目,这样会浪费钱;第二是有一些潜在的疾病,但是套餐里面没有包含,存在漏检的风险。我们的想法是通过机器人跟用户对话,定制个性化体检方案。

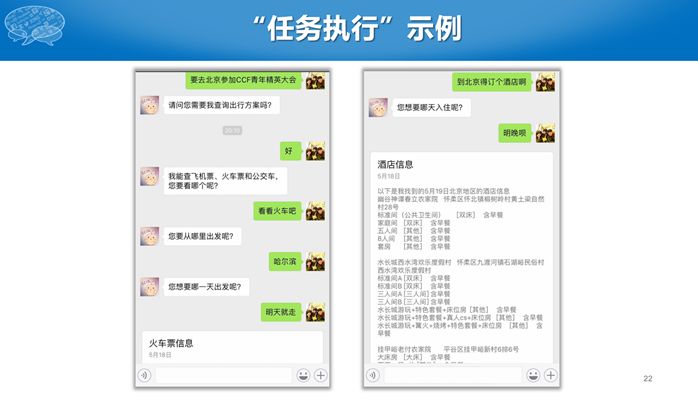
我们实验室开发了一个叫“笨笨”的对话机器人,主要包括聊天、任务执行、知识问答和推荐四项功能,并通过微信提供服务。其中任务执行就是DTP系统提供的。我们可以用“笨笨”完成订火车票、飞机票,以及查询酒店信息等出行场景下的功能。

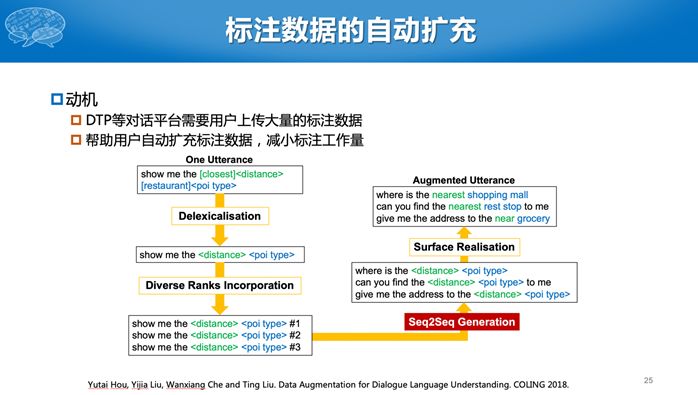
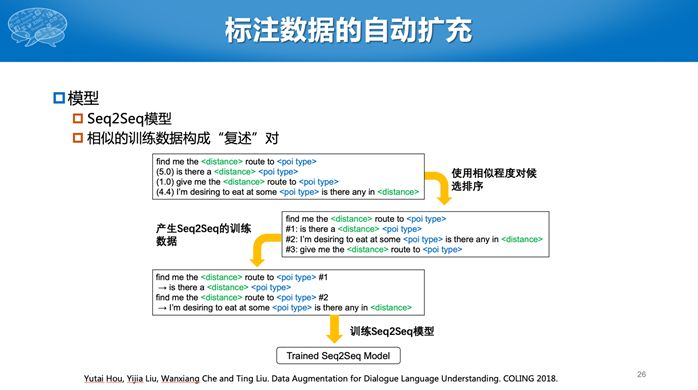
在使用对话技术平台时,目前一个最大的问题就是用户需要上传一些数据,但是数据量往往非常少,如何在少量数据的情况下提高对话能力呢?假设用户就上传三句话,并为这三句话标注了一些槽,我们希望能通过这三句话改写成更多语义相同,但是表达形式不一样的句子。这其实是数据增强,在图像里面也有类似的想法,我们可以对原始的图像进行旋转或者平移的操作,构造更多的训练数据。但是即使只对语言稍微替换一个字母,意思也不一样了。所以对语言的数据增强难度更高。此处,我们将同一意图下的多个句子两两构造成互为复述的句对,然后使用Seq2Seq模型学习如何生成新的数据。最终将原始的训练数据,扩展成更多的数据。当训练数据比较少时,如只有几十句或者几句,提升的效果非常明显。

另外,传统的对话系统还有一些不足。首先,各个模块之间都是相互独立的,这样我需要为每个模块去标注大量的数据,特别是跟领域相关的数据;底层模块的错误会影响上层模块,如果语言理解错了,就会影响到对话的管理,这也叫错误的级联;上层模块信息无法反馈到下层模块。其次,针对每个领域都需要人工设计语义槽,动作空间也都不一样,导致系统的设计跟领域非常相关,很难切换到新的领域。

因此,我们希望把原来的三个模块用统一的端到端模型替代。系统只需要知道输入以及相应的输出,也就是对应的回复即可。这种数据也比较容易获得,如各大银行、电信、携程等有大量的客服对话数据。

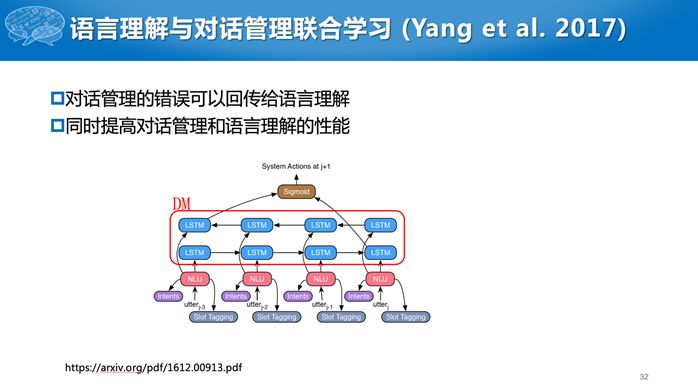
之前有一些相关的工作,如所谓的联合学习,就是将多个模块放在一起学习,这样可以减小错误级联的问题。Yang et al. 2017把对话管理模块和语言理解模块进行联合学习。Wen et al. 2016把更多的模块放在一起端到端的训练,包括语言理解、对话管理和对话生成。但是对于数据库的查询,仍然需要显式地转成SQL语句。

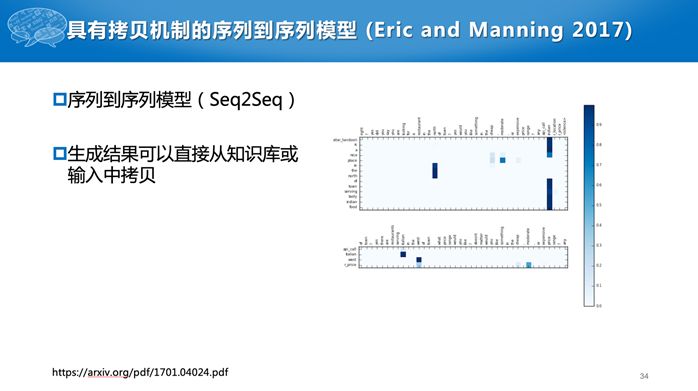
Eric and Manning (2017)直接使用序列到序列的模型,从用户的提问生成相应的回复。针对任务型对话,传统的序列到序列模型有一个明显的问题,就是我们不能简单地从历史对话数据中学习,比如问“明天天气怎么样?”如果训练数据有回复说“晴天”,但是不能每次都一样的回答,需要根据当前天气预报数据进行回复。所以在他们的工作中,生成的词有两个来源,一个数据库,如“晴天”或者“阴天”,第二就是从原始文本中拷贝过来。
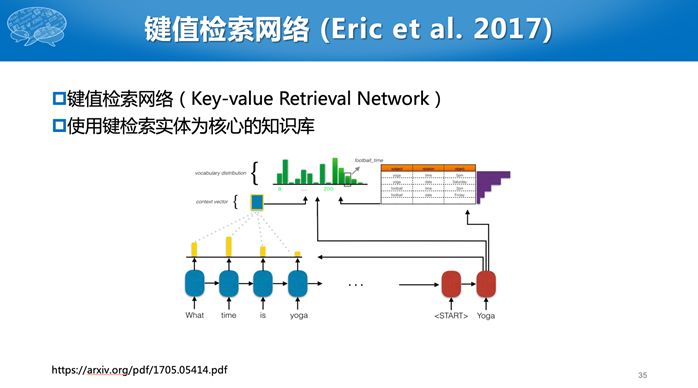
后来他们把这个工作进一步进行延伸,能够更好的对数据库进行查询 (Eric et al. 2017)。先把数据库的表示方式进行修改,原来数据库是多种属性的关系表。现在拆分成<实体, 属性名字, 属性值>构成的三元组,然后在三元组列表上进行打分,分数最高的即为最能回答当前问题的知识。
以上工作是纯粹端到端的模型,而进行对话时,要对对话的状态进行表示和跟踪。我们不想显示的定义对话状态,所以我们用向量表示对话状态,向量每一维代表哪一个槽需要自己学习,这相当于隐式的对话状态表示。一方面可以用它直接查数据库,使得查询更准确,另一方面它更有利于对话回复的生成。

所使用的数据集是斯坦福发布的,有日程、天气预报和导航三个领域。每个对话都有相应的数据库进行支撑。如导航领域,数据库包括要查询的POI地址,与当前位置的距离,是否堵车等交通信息。以下是自动以及人工评价的结果,后面是具体的样例。


与其它自然语言处理问题不同,对话系统的评价也是一个非常难的问题。对于用户输入的对话,系统可以有各种各样合理的回答。为此,我们去年和今年,在全国SMP(社会媒体处理)大会上,连续两年组织了人机对话技术评测,评测相关的具体信息如下。

我们设置了两个评测任务,第一是用户意图领域分类,即给定一个用户对话输入,识别是什么样的意图。我们共选取了30个垂类。

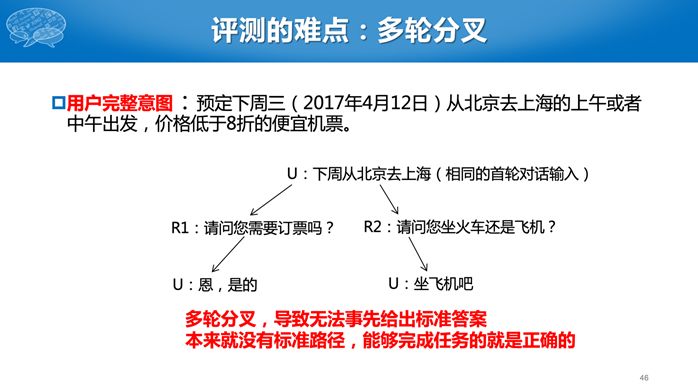
第二个任务比较难,参赛单位需要构建一个完整的对话系统,对于同一个用户输入,有很多种可能的输出,到底哪个输出好,现在机器比较难评价。因此我们采用了人工评测的办法。有一个真实的评测人员,给所有的系统统一的初始输入,然后针对每个系统的回复继续进行对话,若干轮后给出评价。评价有几个指标,包括用户满意度、回复自然度等主观指标,还有对话轮次等客观指标,对话轮数是越少越好。



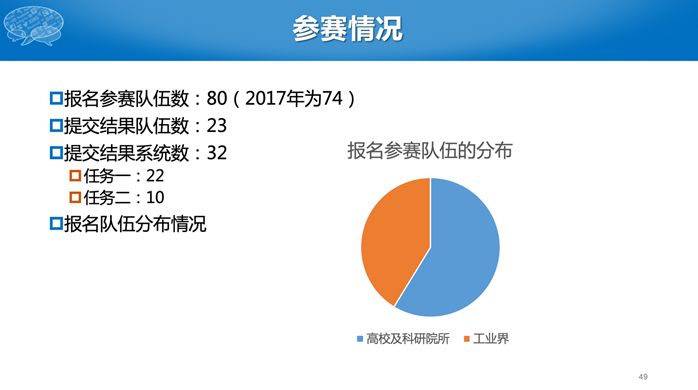
最终共有80支队伍参赛,工业界和高校等科研院所各占一半。任务一有20多个单位提交结果,任务二有10个单位提交结果。最终评测排名如下。
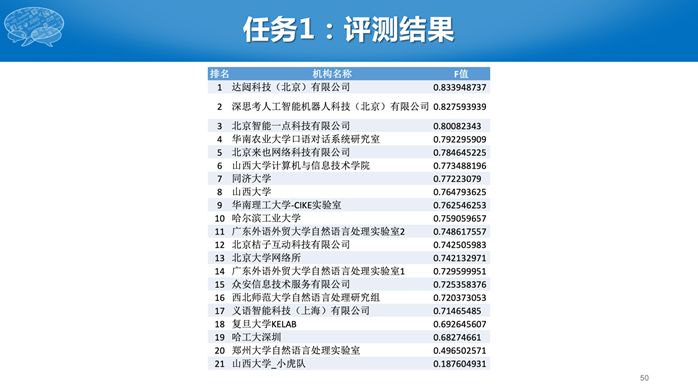
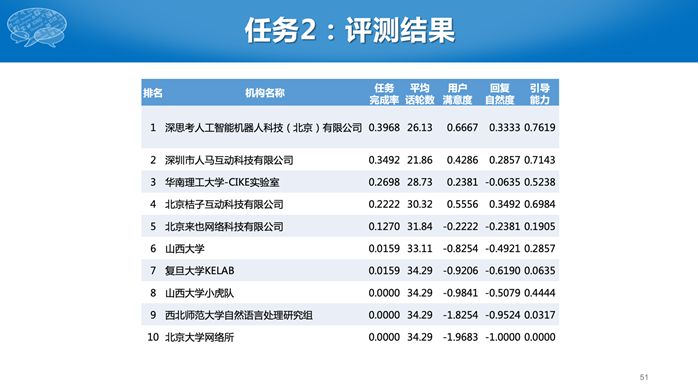
今年的评测虽然结束了,我们没有公开测试数据,而是基于Codalab构建了一个在线评测系统,这样很多没有参赛的单位和个人,后续还可以陆续提交自己的系统,并参与到排行里面。

最后做一个总结:我们首先介绍了什么是任务型对话系统以及常用的技术方案;接着介绍了我们构建的对话技术平台DTP,它能够帮助开发者,快速构建任务型对话系统;然后介绍了我们近期的两个工作,主要为了解决对话系统中数据不足的问题。第一是帮助用户自动扩充数据,第二是不用标数据,直接端到端的构建任务型对话系统;最后介绍了我们组织的SMP人机对话评测,目前该评测仍需要人来参与,挑战比较大。未来我们主要关注于多领域之间的快速移植,以及对话系统的自动评价。谢谢大家!


本期责任编辑:张伟男
本期编辑:蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



