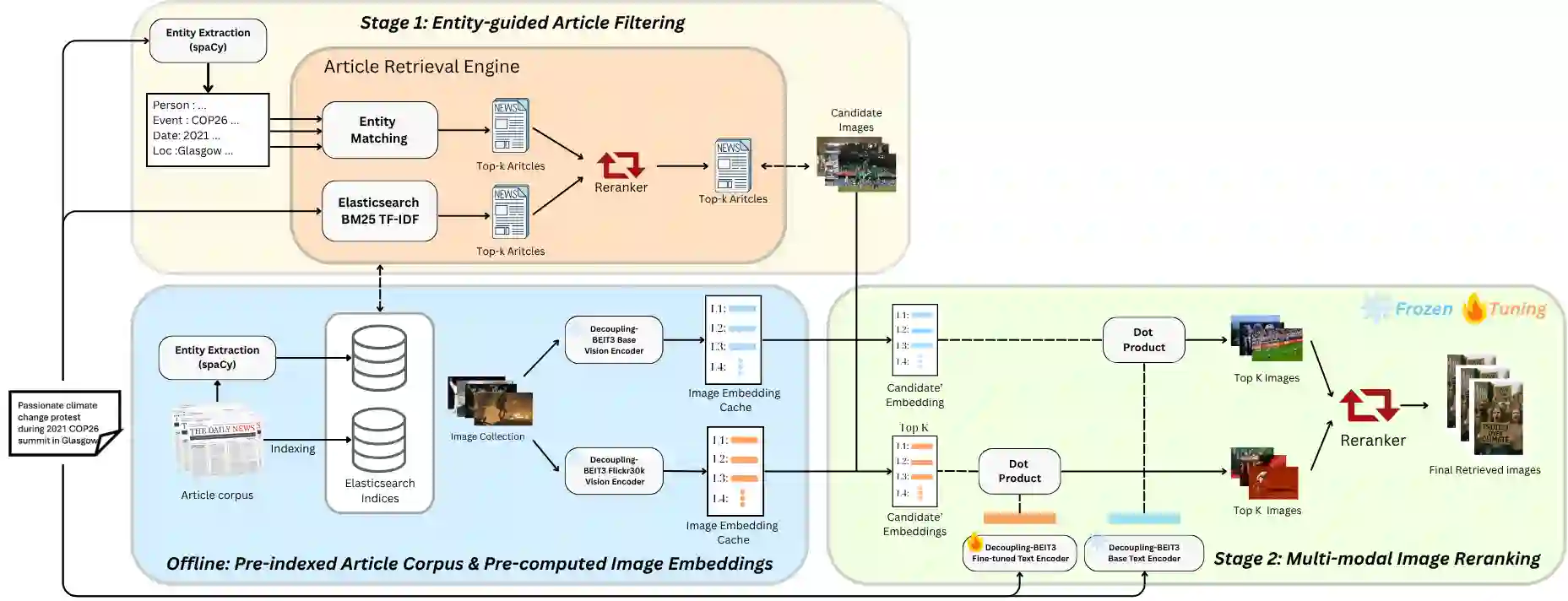
Retrieving images from natural language descriptions is a core task at the intersection of computer vision and natural language processing, with wide-ranging applications in search engines, media archiving, and digital content management. However, real-world image-text retrieval remains challenging due to vague or context-dependent queries, linguistic variability, and the need for scalable solutions. In this work, we propose a lightweight two-stage retrieval pipeline that leverages event-centric entity extraction to incorporate temporal and contextual signals from real-world captions. The first stage performs efficient candidate filtering using BM25 based on salient entities, while the second stage applies BEiT-3 models to capture deep multimodal semantics and rerank the results. Evaluated on the OpenEvents v1 benchmark, our method achieves a mean average precision of 0.559, substantially outperforming prior baselines. These results highlight the effectiveness of combining event-guided filtering with long-text vision-language modeling for accurate and efficient retrieval in complex, real-world scenarios. Our code is available at https://github.com/PhamPhuHoa-23/Event-Based-Image-Retrieval
翻译:从自然语言描述中检索图像是计算机视觉与自然语言处理交叉领域的核心任务,在搜索引擎、媒体归档和数字内容管理等领域具有广泛应用。然而,由于查询语句的模糊性、语境依赖性、语言表达的多样性以及可扩展性需求,现实场景中的图文检索仍面临挑战。本研究提出一种轻量级两阶段检索框架,通过事件中心实体提取技术,从现实世界图像描述中融合时序与上下文信息。第一阶段基于显著实体,采用BM25算法进行高效候选图像筛选;第二阶段运用BEiT-3模型捕获深度多模态语义特征并对结果重排序。在OpenEvents v1基准测试中,本方法实现了0.559的平均精度均值,显著超越现有基线模型。实验结果表明,结合事件引导过滤机制与长文本视觉语言建模,能够在复杂现实场景中实现精准高效的图像检索。代码已开源:https://github.com/PhamPhuHoa-23/Event-Based-Image-Retrieval