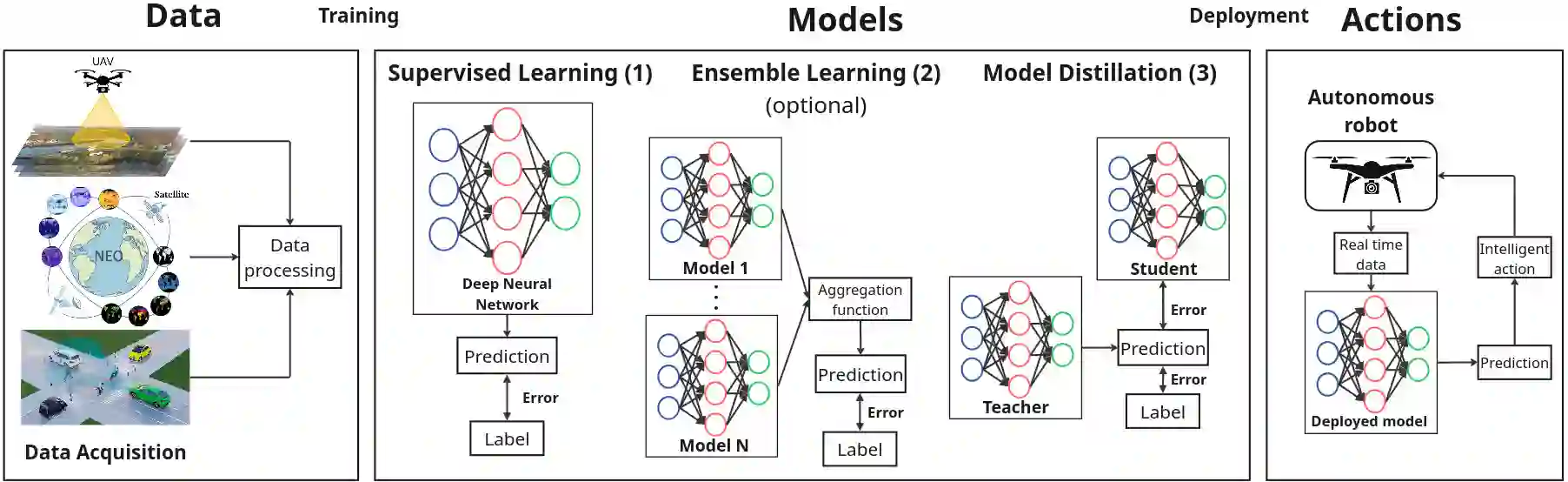
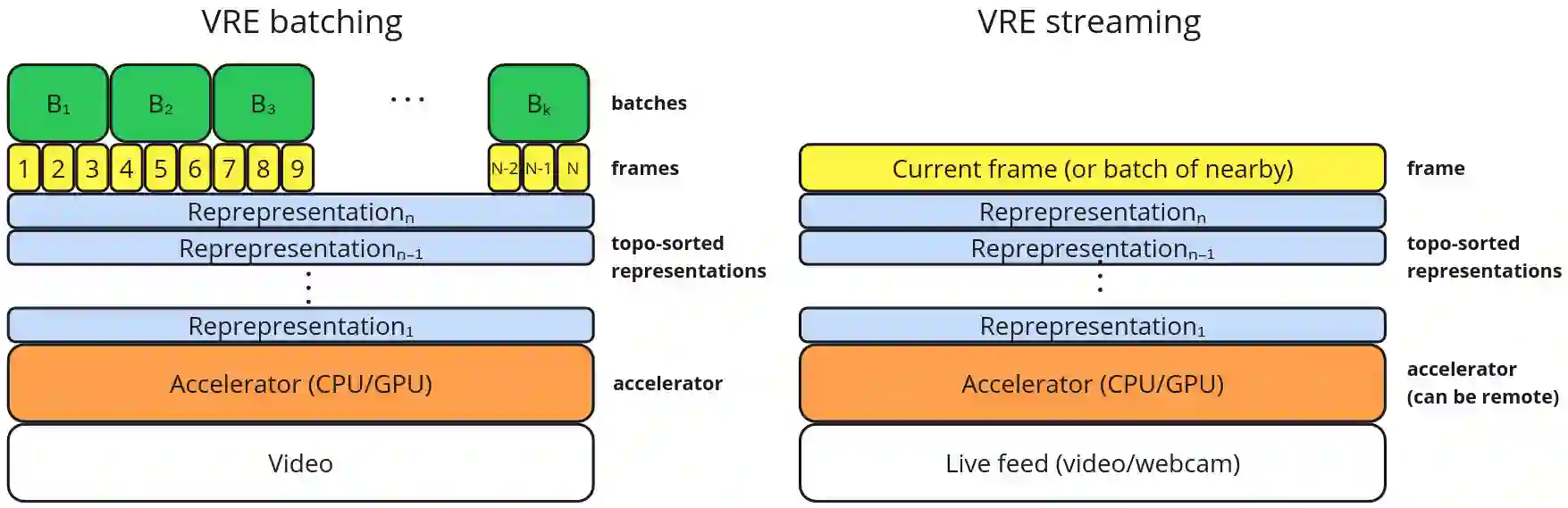
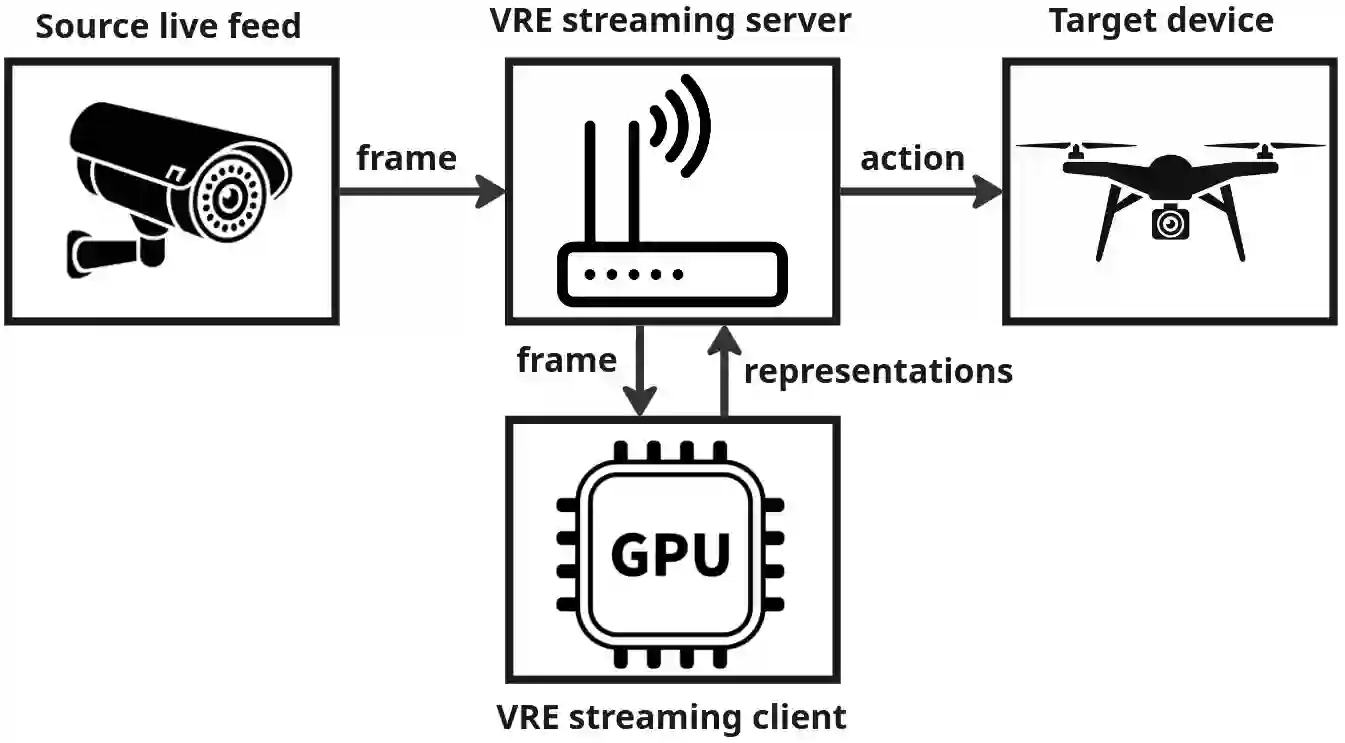
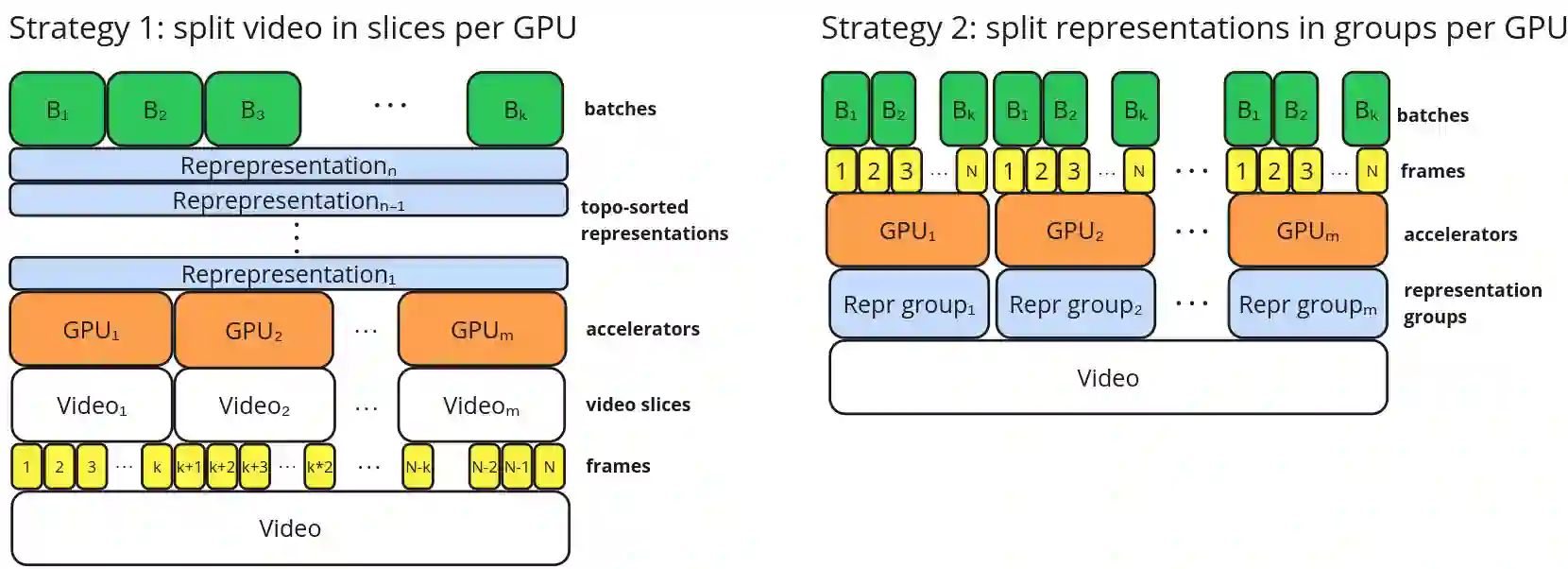
The real-world is inherently multi-modal at its core. Our tools observe and take snapshots of it, in digital form, such as videos or sounds, however much of it is lost. Similarly for actions and information passing between humans, languages are used as a written form of communication. Traditionally, Machine Learning models have been unimodal (i.e. rgb -> semantic or text -> sentiment_class). Recent trends go towards bi-modality, where images and text are learned together, however, in order to truly understand the world, we need to integrate all these independent modalities. In this work we try to combine as many visual modalities as we can using little to no human supervision. In order to do this, we use pre-trained experts and procedural combinations between them on top of raw videos using a fully autonomous data-pipeline, which we also open-source. We then make use of PHG-MAE, a model specifically designed to leverage multi-modal data. We show that this model which was efficiently distilled into a low-parameter (<1M) can have competitive results compared to models of ~300M parameters. We deploy this model and analyze the use-case of real-time semantic segmentation from handheld devices or webcams on commodity hardware. Finally, we deploy other off-the-shelf models using the same framework, such as DPT for near real-time depth estimation.
翻译:现实世界本质上是多模态的。我们的工具以数字形式(如视频或声音)观察并记录其快照,然而大量信息在此过程中丢失。类似地,在人类之间的行动与信息传递中,语言被用作书面的沟通形式。传统上,机器学习模型通常是单模态的(例如:RGB图像→语义分割 或 文本→情感分类)。当前趋势正朝向双模态发展,即图像与文本被联合学习,然而,为了真正理解世界,我们需要整合所有这些独立的模态。在本工作中,我们尝试在极少或无需人工监督的情况下,尽可能多地结合视觉模态。为此,我们利用预训练的专家模型,并通过完全自动化的数据流水线(我们已将其开源)在原始视频上实现这些模型之间的程序化组合。随后,我们采用专为利用多模态数据而设计的PHG-MAE模型进行实验。研究表明,经高效蒸馏至低参数量(<100万)的该模型,能够与参数量约3亿的模型取得具有竞争力的结果。我们部署了该模型,并分析了在商用硬件上通过手持设备或网络摄像头实现实时语义分割的应用场景。最后,我们使用同一框架部署了其他现成模型,例如用于近实时深度估计的DPT模型。