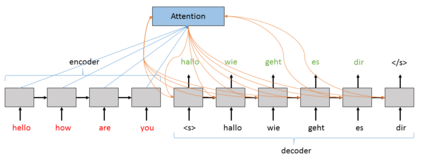
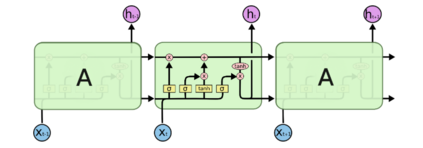
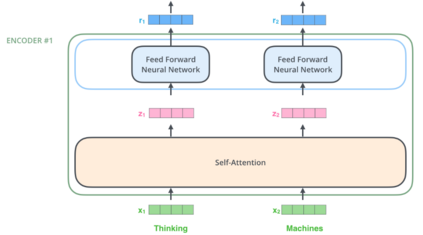
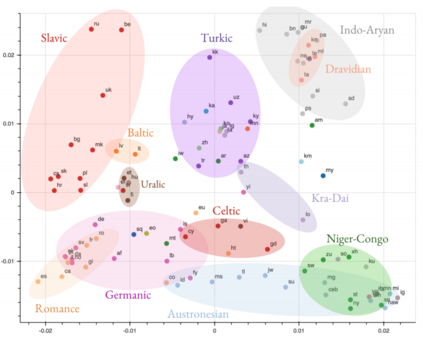
Over the past few years, we have seen fundamental breakthroughs in core problems in machine learning, largely driven by advances in deep neural networks. At the same time, the amount of data collected in a wide array of scientific domains is dramatically increasing in both size and complexity. Taken together, this suggests many exciting opportunities for deep learning applications in scientific settings. But a significant challenge to this is simply knowing where to start. The sheer breadth and diversity of different deep learning techniques makes it difficult to determine what scientific problems might be most amenable to these methods, or which specific combination of methods might offer the most promising first approach. In this survey, we focus on addressing this central issue, providing an overview of many widely used deep learning models, spanning visual, sequential and graph structured data, associated tasks and different training methods, along with techniques to use deep learning with less data and better interpret these complex models --- two central considerations for many scientific use cases. We also include overviews of the full design process, implementation tips, and links to a plethora of tutorials, research summaries and open-sourced deep learning pipelines and pretrained models, developed by the community. We hope that this survey will help accelerate the use of deep learning across different scientific domains.
翻译:在过去几年里,我们看到了机器学习核心问题的根本性突破,这主要是由深神经网络的进步驱动的。与此同时,在一系列广泛的科学领域收集的数据数量在规模和复杂性两方面都急剧增加。加在一起,这表明在科学环境中深层学习应用有许多令人振奋的机会。但这方面的一个重大挑战是知道从何开始。不同深层次的学习技术的广度和多样性使得难以确定哪些科学问题最容易采用这些方法,或者哪些具体的方法组合可能提供最有希望的第一个方法。在本次调查中,我们侧重于解决这一核心问题,对许多广泛使用的深层学习模型、横跨视觉、顺序和图表结构数据、相关任务和不同培训方法进行概述,以及利用较少数据的深度学习和更好解释这些复杂模型的技术 -- -- 许多科学使用案例的两个中心考虑因素。我们还包括全面设计过程的概览、实施提示和与过多的辅导、研究摘要和公开来源的深层次学习管道以及社区开发的预设模型的链接。我们希望这项调查将有助于在不同的领域加速进行深层次的科学学习。