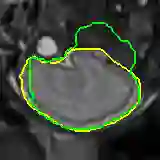
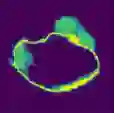
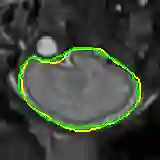
Data augmentation has been widely used for training deep learning systems for medical image segmentation and plays an important role in obtaining robust and transformation-invariant predictions. However, it has seldom been used at test time for segmentation and not been formulated in a consistent mathematical framework. In this paper, we first propose a theoretical formulation of test-time augmentation for deep learning in image recognition, where the prediction is obtained through estimating its expectation by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We then propose a novel uncertainty estimation method based on the formulated test-time augmentation. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions, and 2) it provides a better uncertainty estimation than calculating the model-based uncertainty alone and helps to reduce overconfident incorrect predictions.
翻译:数据增强被广泛用于培训医学图像分化的深层学习系统,在获得稳健和转化变异预测方面发挥重要作用,但很少在测试时用于分解,也没有在一致的数学框架内制定。在本文中,我们首先提出为在图像识别方面深层学习而进行测试-时间增强的理论性表述,通过蒙特卡洛模拟估计其预期值和图象获取模型中先前的参数分布,涉及图像转换和噪音。然后,我们根据已制定的测试-时间增强,提出新的不确定性估计方法。2D和3D磁共振图像对胎儿大脑和脑肿瘤的分解实验表明,1)我们的测试-时间增强超过单位基线和基于辍学的多重预测,2)它比仅仅计算基于模型的不确定性和帮助减少过分自信的不正确预测,提供了更好的不确定性估计。