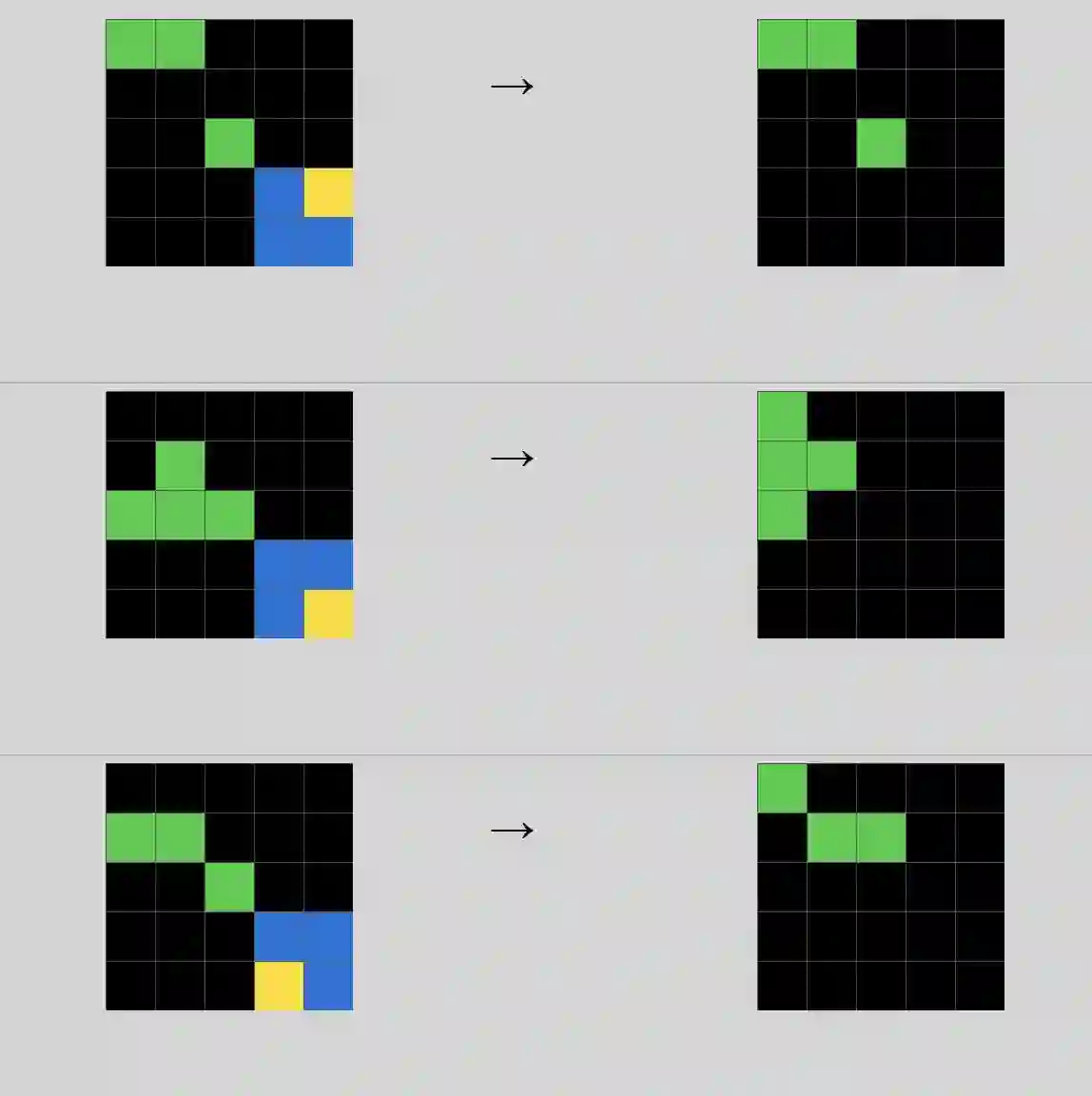
Reasoning benchmarks such as the Abstraction and Reasoning Corpus (ARC) and ARC-AGI are widely used to assess progress in artificial intelligence and are often interpreted as probes of core, so-called ``fluid'' reasoning abilities. Despite their apparent simplicity for humans, these tasks remain challenging for frontier vision-language models (VLMs), a gap commonly attributed to deficiencies in machine reasoning. We challenge this interpretation and hypothesize that the gap arises primarily from limitations in visual perception rather than from shortcomings in inductive reasoning. To verify this hypothesis, we introduce a two-stage experimental pipeline that explicitly separates perception and reasoning. In the perception stage, each image is independently converted into a natural-language description, while in the reasoning stage a model induces and applies rules using these descriptions. This design prevents leakage of cross-image inductive signals and isolates reasoning from perception bottlenecks. Across three ARC-style datasets, Mini-ARC, ACRE, and Bongard-LOGO, we show that the perception capability is the dominant factor underlying the observed performance gap by comparing the two-stage pipeline with against standard end-to-end one-stage evaluation. Manual inspection of reasoning traces in the VLM outputs further reveals that approximately 80 percent of model failures stem from perception errors. Together, these results demonstrate that ARC-style benchmarks conflate perceptual and reasoning challenges and that observed performance gaps may overstate deficiencies in machine reasoning. Our findings underscore the need for evaluation protocols that disentangle perception from reasoning when assessing progress in machine intelligence.
翻译:诸如抽象与推理语料库(ARC)和ARC-AGI等推理基准被广泛用于评估人工智能的进展,并常被解读为对核心的所谓“流体”推理能力的探测。尽管这些任务对人类而言看似简单,但对前沿的视觉-语言模型(VLMs)来说仍然具有挑战性,这一差距通常被归因于机器推理能力的不足。我们质疑这一解读,并提出假设:该差距主要源于视觉感知的局限性,而非归纳推理的缺陷。为验证此假设,我们引入了一个两阶段实验流程,明确地将感知与推理分离。在感知阶段,每张图像被独立地转换为自然语言描述;而在推理阶段,模型则利用这些描述进行归纳并应用规则。这种设计防止了跨图像归纳信号的泄露,并将推理与感知瓶颈隔离开来。通过在三个ARC风格的数据集(Mini-ARC、ACRE和Bongard-LOGO)上比较两阶段流程与标准的端到端单阶段评估,我们表明感知能力是导致所观察到性能差距的主导因素。对VLM输出中推理轨迹的人工检查进一步揭示,约80%的模型失败源于感知错误。综合来看,这些结果表明ARC风格的基准混淆了感知与推理的挑战,并且观察到的性能差距可能夸大了机器推理的缺陷。我们的发现强调,在评估机器智能进展时,需要采用能够区分感知与推理的评估协议。