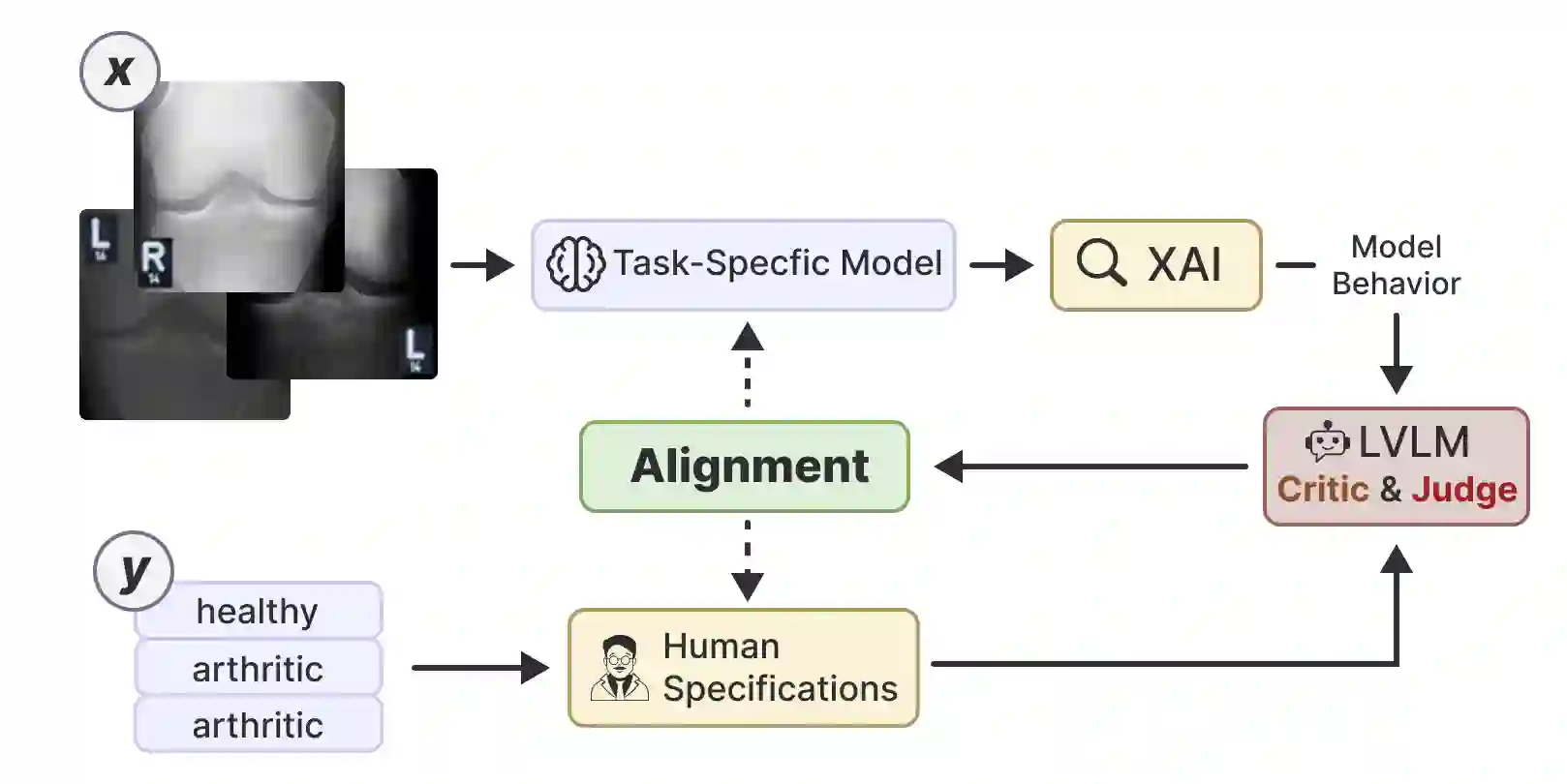
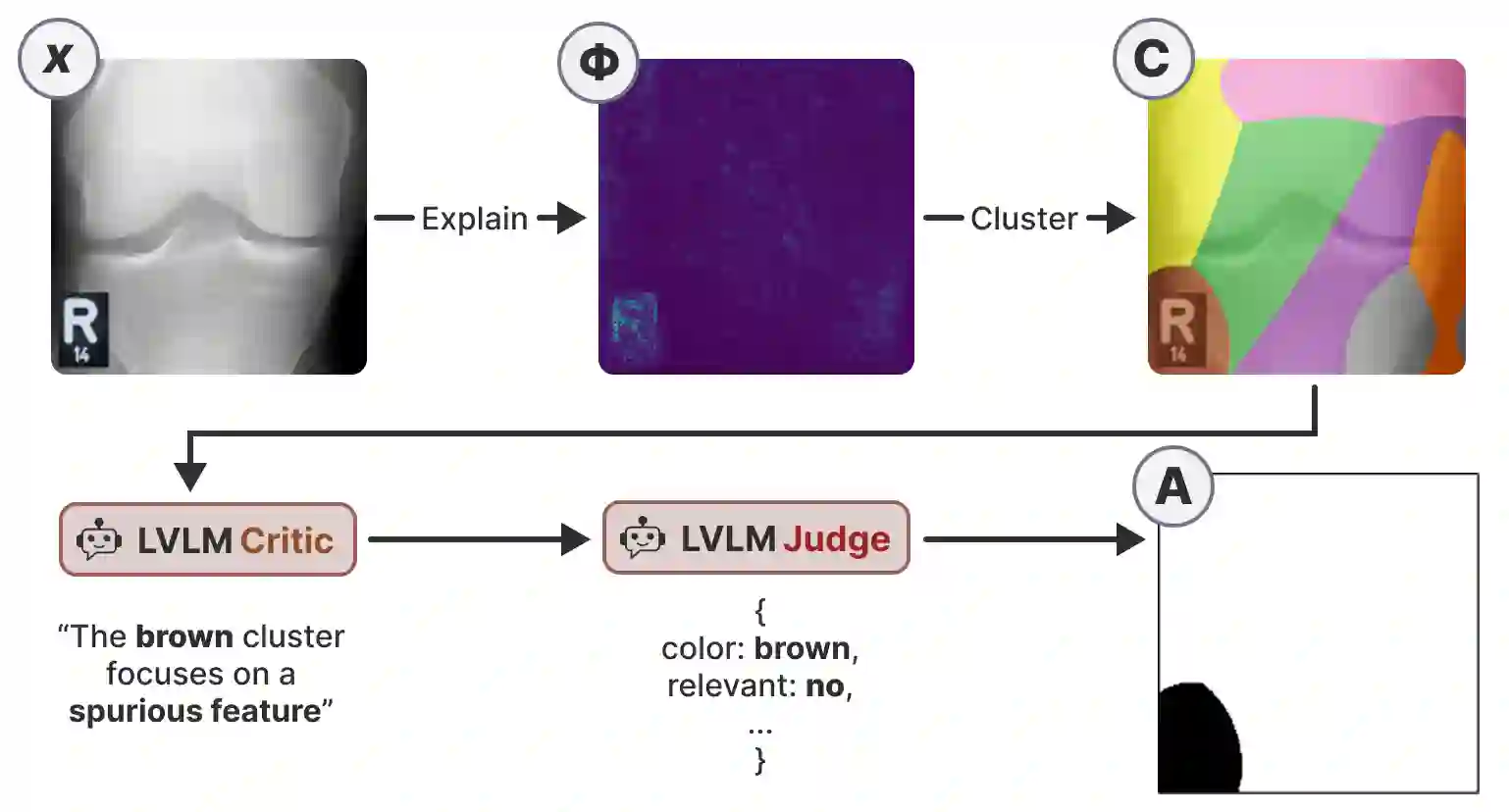
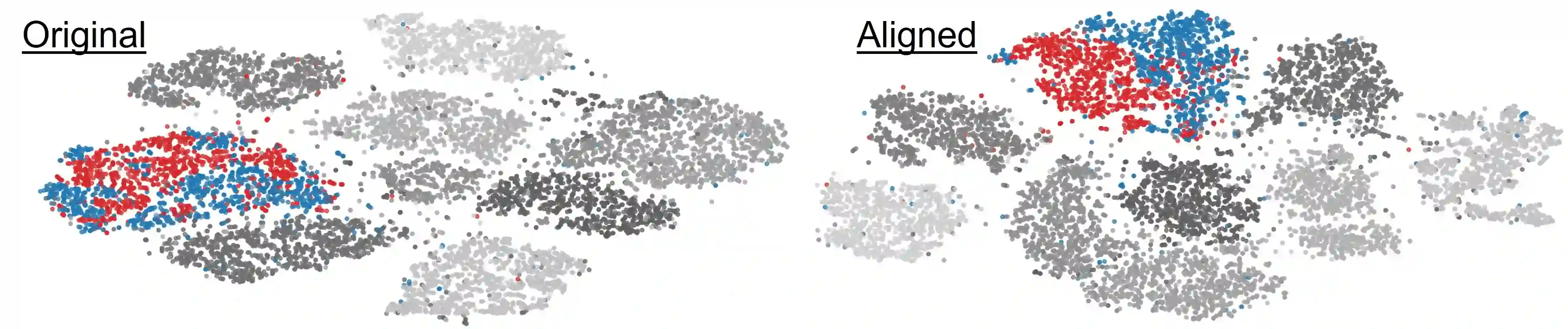
In high-stakes domains, small task-specific vision models are crucial due to their low computational requirements and the availability of numerous methods to explain their results. However, these explanations often reveal that the models do not align well with human domain knowledge, relying instead on spurious correlations. This might result in brittle behavior once deployed in the real-world. To address this issue, we introduce a novel and efficient method for aligning small task-specific vision models with human domain knowledge by leveraging the generalization capabilities of a Large Vision Language Model (LVLM). Our LVLM-Aided Visual Alignment (LVLM-VA) method provides a bidirectional interface that translates model behavior into natural language and maps human class-level specifications to image-level critiques, enabling effective interaction between domain experts and the model. Our method demonstrates substantial improvement in aligning model behavior with human specifications, as validated on both synthetic and real-world datasets. We show that it effectively reduces the model's dependence on spurious features and on group-specific biases, without requiring fine-grained feedback.
翻译:在高风险领域中,小型任务专用视觉模型因其低计算需求以及存在多种可解释其结果的方 法而至关重要。然而,这些解释常揭示模型未能与人类领域知识良好对齐,反而依赖于虚假 相关性。这可能导致模型在真实世界部署时表现出脆弱性。为解决此问题,我们提出一种新 颖且高效的方法,通过利用大型视觉语言模型(LVLM)的泛化能力,将小型任务专用视觉 模型与人类领域知识对齐。我们的LVLM辅助视觉对齐(LVLM-VA)方法提供了一个双向接 口,可将模型行为转化为自然语言,并将人类类别级规范映射到图像级评判,从而实现领域 专家与模型之间的有效交互。我们的方法在合成数据集和真实世界数据集上的验证表明,其 在使模型行为与人类规范对齐方面取得了显著改进。我们证明,该方法有效降低了模型对虚 假特征和群体特定偏见的依赖,且无需细粒度反馈。