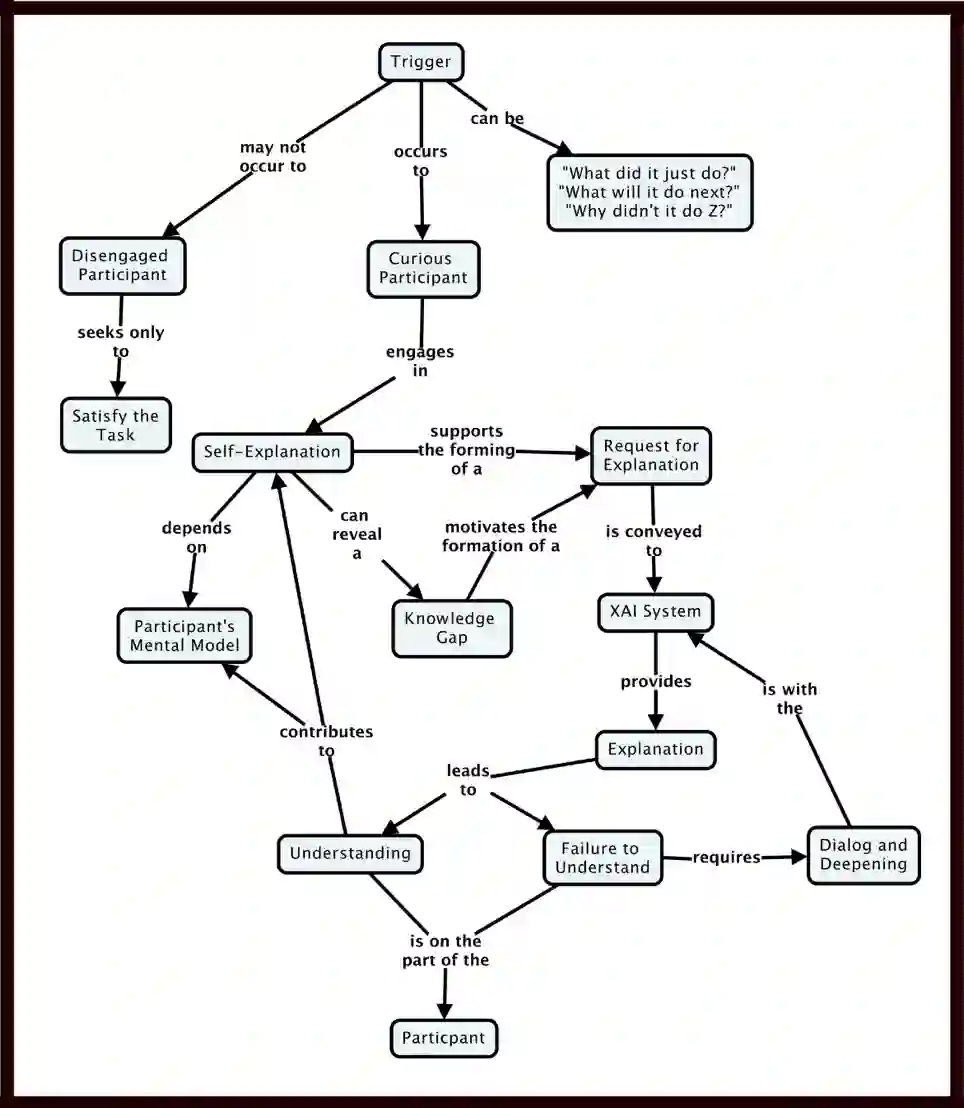
The question addressed in this paper is: If we present to a user an AI system that explains how it works, how do we know whether the explanation works and the user has achieved a pragmatic understanding of the AI? In other words, how do we know that an explanainable AI system (XAI) is any good? Our focus is on the key concepts of measurement. We discuss specific methods for evaluating: (1) the goodness of explanations, (2) whether users are satisfied by explanations, (3) how well users understand the AI systems, (4) how curiosity motivates the search for explanations, (5) whether the user's trust and reliance on the AI are appropriate, and finally, (6) how the human-XAI work system performs. The recommendations we present derive from our integration of extensive research literatures and our own psychometric evaluations.
翻译:本文所讨论的问题是:如果我们向用户提供一个解释其如何运作的AI系统,我们如何知道解释是否有效,用户是否对AI取得了务实的理解?换句话说,我们如何知道一个可排除的AI系统(XAI)是好的?我们的重点是衡量的关键概念。我们讨论了评估的具体方法:(1) 解释的好坏,(2) 用户是否对解释感到满意,(3) 用户如何理解AI系统,(4) 好奇心如何促使寻找解释,(5) 用户的信任和对AI的依赖是否适当,以及(6) 人类-XAI工作系统如何运作。我们所提出的建议来自我们广泛研究文献的整合和我们自己的精神评估。