人工智能
·

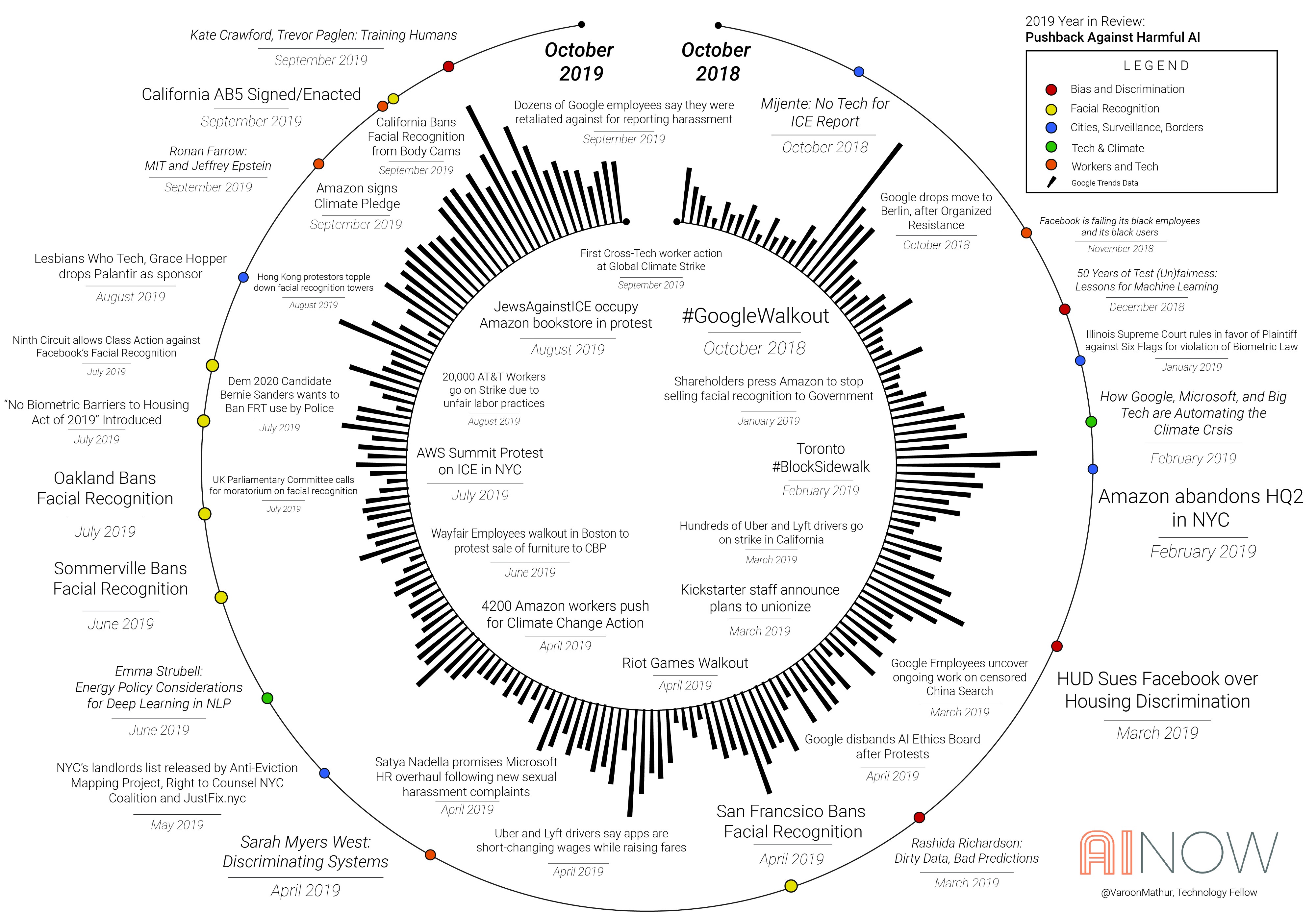
The Growing Pushback Against Harmful AI,AI Now co-founders Kate Crawford and Meredith Whittaker opened the Symposium with a short talk summarizing some key moments of opposition over the year, focusing on five themes: (1) facial and affect recognition; (2) the movement from “AI bias” to justice; (3) cities, surveillance, borders; (4) labor, worker organizing, and AI, and; (5) AI’s climate impact. Below is an excerpt from their talk.
相关内容
专知会员服务
38+阅读 · 2020年5月30日
相关主题

相关VIP内容
专知会员服务
38+阅读 · 2020年5月30日
相关资讯
相关论文