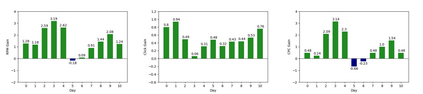
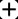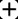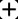The representation learning on textual graph is to generate low-dimensional embeddings for the nodes based on the individual textual features and the neighbourhood information. Recent breakthroughs on pretrained language models and graph neural networks push forward the development of corresponding techniques. The existing works mainly rely on the cascaded model architecture: the textual features of nodes are independently encoded by language models at first; the textual embeddings are aggregated by graph neural networks afterwards. However, the above architecture is limited due to the independent modeling of textual features. In this work, we propose GraphFormers, where layerwise GNN components are nested alongside the transformer blocks of language models. With the proposed architecture, the text encoding and the graph aggregation are fused into an iterative workflow, making each node's semantic accurately comprehended from the global perspective. In addition, a progressive learning strategy is introduced, where the model is successively trained on manipulated data and original data to reinforce its capability of integrating information on graph. Extensive evaluations are conducted on three large-scale benchmark datasets, where GraphFormers outperform the SOTA baselines with comparable running efficiency.
翻译:在文本图上进行演示学习是为了根据单个文本特征和周边信息为节点产生低维嵌入。在经过培训的语文模型和图形神经网络方面最近出现的突破推动了相应技术的开发。现有的工程主要依靠级联模型结构:节点的文本特征首先由语言模型独立编码;文体嵌入随后由图形神经网络汇总。然而,上述结构因文本特征的独立模型而受到限制。在这项工作中,我们提议了图格式,其中分层的GNN组件与变压器语言模型的块一起嵌入。随着拟议的结构,文本编码和图形组合被结合到一个迭接工作流程中,使每个节点的语义从全球角度得到准确理解。此外,还引入了一个渐进学习战略,在模型上连续对操纵的数据和原始数据进行培训,以加强其整合图形信息的能力。在三个大型基准数据集上进行了广泛的评估,其中,图形格式比SOTA基线的运行效率可比。