成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
异构信息网络
关注
15
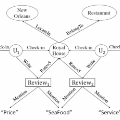
异构信息网络 (Hetegeneous Information Network 以下简称 HIN),是由 UIUC 的 Han Jiawei 和 UCLA 的 Sun Yizhou 在 2011 年的 VLDB 论文中首次提出。
综合
百科
VIP
热门
动态
论文
精华
精品内容
【UCLA-微软-WWW2020】异构图Transformer,Heterogeneous Graph Transformer
专知会员服务
137+阅读 · 2020年3月8日
AAAI 2020 | 滴滴自主提出基于注意力机制的异构图神经网络模型
专知会员服务
53+阅读 · 2020年2月26日
六篇 EMNLP 2019【图神经网络(GNN)+NLP】相关论文
专知会员服务
72+阅读 · 2019年11月3日
【KDD2019|讲座推荐】从海量文本中构建和挖掘异构信息网络:Constructing and Mining Heterogeneous Information Networks from Massive Text
专知会员服务
47+阅读 · 2019年12月11日
【清华大学博士论文】面向社会计算的网络表示学习,涂存超
专知会员服务
76+阅读 · 2019年11月7日
【CIKM2019 Tutorial】Recent Developments of Deep Heterogeneous Information Network Analysis(深度异构信息网络分析的最新进展),附157页PDF免费下载
专知会员服务
29+阅读 · 2019年11月3日
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top