成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
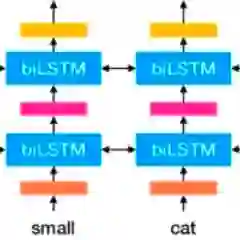
ELMo
关注
19
近年来,研究人员通过文本上下文信息分析获得更好的词向量。ELMo是其中的翘楚,在多个任务、多个数据集上都有显著的提升。所以,它是目前最好用的词向量,the-state-of-the-art的方法。这篇文章发表在2018年的NAACL上,outstanding paper award。下面就简单介绍一下这个“神秘”的词向量模型。
综合
百科
VIP
热门
动态
论文
精华
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(三)
机器之心
0+阅读 · 2022年10月2日
冯仕堃:预训练模型哪家强?百度知识增强大模型探索实践!
专知
0+阅读 · 2022年1月2日
使用上下文信息优化CTR预估中的特征嵌入
机器学习与推荐算法
0+阅读 · 2021年8月20日
【斯坦福CS224N硬核课】如何融合知识到语言模型中,60页ppt
专知
1+阅读 · 2021年3月8日
主流Embedding技术解析
DataFunTalk
1+阅读 · 2020年12月1日
用万字长文聊一聊 Embedding 技术
图与推荐
0+阅读 · 2020年11月25日
图解 BERT 预训练模型!
AINLP
1+阅读 · 2020年11月9日
【NLP专栏】图解 BERT 预训练模型!
深度学习自然语言处理
0+阅读 · 2020年11月3日
从word2vec开始,说下GPT庞大的家族系谱
机器之心
1+阅读 · 2020年10月4日
按照时间线帮你梳理10种预训练模型
AINLP
1+阅读 · 2020年9月25日
按照时间线帮你梳理10种预训练模型
深度学习自然语言处理
1+阅读 · 2020年9月19日
一文盘点预训练神经语言模型
PaperWeekly
0+阅读 · 2020年8月1日
ACL 2020 | 基于多级排序学习的层次化实体标注
PaperWeekly
0+阅读 · 2020年6月12日
【Papernotes】BERT
AINLP
0+阅读 · 2020年6月11日
60分钟详解Bert原理及京东商城的应用实践
专知
0+阅读 · 2020年5月28日
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top