一文盘点预训练神经语言模型

©PaperWeekly 原创 · 作者 | 西南交一枝花
学校 | 西南交通大学CCIT实验室
研究方向 | 命名实体识别
语言模型(Language Model, LM)包括统计语言模型和神经语言模型,能够表示自然语言文本在语料中的概率分布,可用于判断语句是否为正常描述,也可理解为判断文本是否为“人话”。
本文主要介绍了神经语言模型以及预训练语言模型 PTMs,首先列出所需的预备知识(只是简单介绍);紧接着,概述统计语言模型 n-gram;然后,以词向量为过渡引出神经语言模型;最后,对各种模型进行介绍(自回归语言模型:NNLM, Word2Vec, ELMO, GPT, XLNet、自编码语言模型:BERT)。
补充两个概念:
自回归语言模型:根据前一段文本序列预测下一词的概率(反之亦然,即根据后一段文本序列预测上一个词概率),这类语言模型被称为自回归语言模型。简单记之,单向语言模型。
有人可能会有疑问,ELMO 利用了上文和下文信息,应该是自编码模型。虽然 ELMO 是做了两个方向的信息整合(通过拼接),但是我认为两者并未交互,所以本质是一个自回归语言模型的结合。此外,在知乎的一个提问中,也进行了一些探讨,希望在评论区有一些新的讨论。
https://www.zhihu.com/question/337165915
目录
-
预备知识 -
n-gram 语言模型 -
词向量 -
神经概率语言模型 -
Word2Vec -
Glove -
ELMO -
BERT -
XLNET -
GPT-1, GPT-2, GPT-3 -
总结

预备知识
-
马尔科夫假设、马尔科夫链 -
贝叶斯公式 -
哈夫曼树 -
激活函数 sigmoid\softmax -
交叉熵损失函数 -
神经网络结构:CNN\LSTM\GRU\Transformer\Attention机制等

n-gram语言模型
以下主要参考 [1]《统计自然语言处理》。
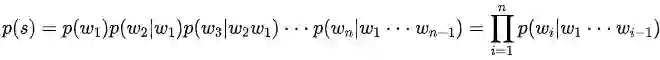
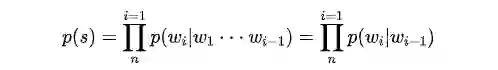

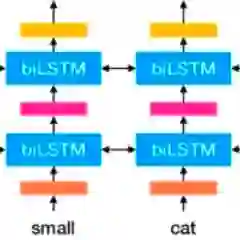
之所以先提一下词向量,主要是为下面章节做个铺垫。构造词向量的方法有很多,下面主要基于的神经网络语言模型角度出发进行介绍。
词,可以看作一个输入单元,在英文当中一个单词为一个单元,中文中词语或字可以看作一个单元。词的嵌入表示从独热编码到词向量(分布式表示),使得现在 NLP 中各个领域的表现性能有了很大的进展。
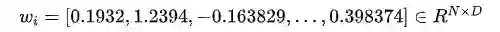
N 表示词的个数,D 表示向量的维度,D 远远小于 N,即低维、稠密、实值表示。
词向量是在 word2vec 之后,被大家所熟知(可能一致专注于该研究的学者一直都熟知,但对于类似我这种萌新,以为词向量是从 word2vec 开始的),最早由Hinton [2] 于 1986 年提出。
那么在神经语言模型之前,如何得到词向量呢?
介绍两种方式:LSA 潜在语义分析、LDA 隐含狄利克雷分布主题模型。

神经概率语言模型
Bengio [3] 在 2013 年发表了该工作,提出了基于神经网络的语言模型,其中词向量是语言模型的副产物。
该模型很简单,包括:输入层、投影层、隐藏层、输出层。该方面的解读已经很多了,这里也不多加赘述,主要说一下该模型相对于 n-gram 模型的优点:
-
词的相似性,在 n-gram中 无法捕获词语之前的相似性,举例:A cat is running in the room 和 A dog is running in the room。如果前者在语料中出现 1000 词,后者出现一次。p(前者)远远大于 p(后者)。但在神经概率语言模型中,这两者应该是大致相等的。
-
词向量的平滑性,n-gram 在计算时对于统计频次出现 0 的情况,需要进行数据平滑。

Word2Vec
一句话说明 word2vec 思想:word2vec 可以理解为模型在学习 word 和 context 的 co-occurrence。 非原创,忘记在哪里看到的。
首先,推荐以下文献或解读,在整个过程中,确实看了很多参考文献。
-
论文 [4] 提出了两种框架 CBOW 和 Skip-gram。 -
论文 [5] 提出了两种提高词向量训练的方式 Hierarcial Softmax 和 Negative sampling。 -
解读 [6] ,强推!讲的很系统,清晰,也是本文上半部分的主要参考。这里给出百度网盘的链接。 链接:https://pan.baidu.com/s/1MJmi-jOKshOGuF9VEpyoHQ提取码:ba8y
-
解读 [7] 讲的也是很清楚,总体推导不错。
1. 改变了原有的投影层之后的拼接操作,改为累加求和,无需隐藏层,输出为层次 softmax,结构上来说,从线性结构转树形结构。
上述操作,带来一个问题,在后向传播时,由于取得是各个词向量之和,每个词向量表示如何更新呢?原文中使用的方法很简单,正向的时候用的是各个词向量的求和,那么后向传播的时候将总梯度依次对所有词向量进行更新,即把总和的梯度贡献到每一个词的向量表示。
2. sigmoid 函数的近似计算,使用查表方式计算,省去了大量的计算。
3. 哈希表存储词典
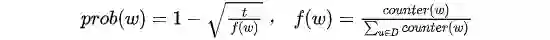
-
自适应学习率
-
多线程并行

GloVe [8]
GloVe 全称 Global Vectors for Word Representation,结合了全局词频统计信息和局部上下文信息,可以理解为了综合了 LSA 和 word2vec 的词向量表示。
文中使用全局矩阵分解和局部上下文窗口方法,主要解决了两个问题:
1. LSA 在分解 cooccurrence matrix 时,使用了 SVD 方法,该方法在处理大语料时存在计算代价过高的不足,此外,LSA 中所有单词的统计权重都是一样的。还有一点很重要基于词频统计的语言模型不具备 word analogy 能力,举例说明 king - queen = man - woman。
2. Word2Vec 无论是 CBOW 还是 Skip-gram 框架都是基于局部的上下文信息,没有利用到全局的统计信息。
6.1 GloVe工作流程
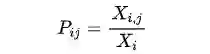
上述表示单词 j 出现在单词 i 上下文中的概率。
文中引入了探测词(Probe words)k,并以此定义了 k 与 i 和 j 关系。分为了四种情况:1. 单词 i , k 相关; 2. 单词 i, k 不相关;3. 单词 j, k 相关;4. 单词j, k 不相关。
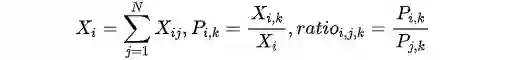

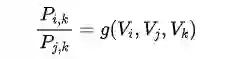
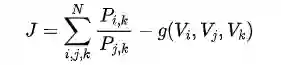
主要考虑了一下几点(总结文中给出的解读):
-
计算复杂度,上述为 NNN; -
函数需要保持向量的相似性; -
ratio 值为标量,函数需要保持一致。
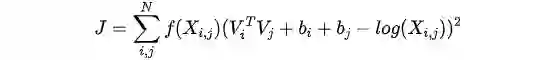

官方解读:https://allennlp.org/elmo
一句话介绍:ELMo是一个深度的、上下文相关的词表示模型。
三个主要特点:
动态词向量表示,当前词向量与当前句子语义相关,并非一成不变。
-
深度,词表示使用了所有层的信息,(个人感觉不算深度,官方用的 Deep 概括该特点)。 -
字符嵌入,完全基于字符嵌入,便于处理 OOV。
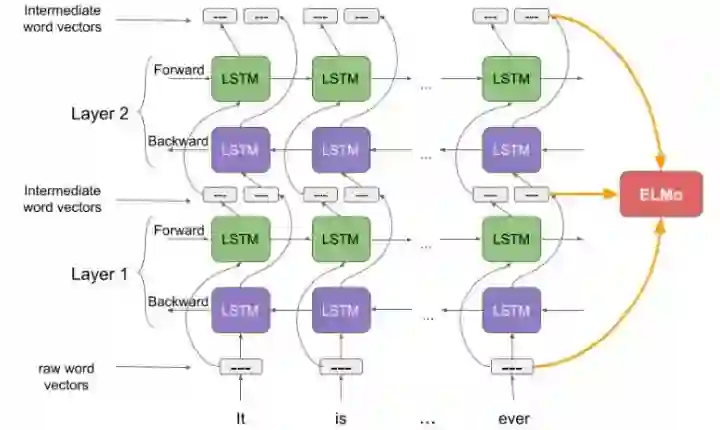
所有词以字符方式输入,经过 n-gram CNN 之后,再经过全连接层降维,作为 LSTM 层的输入。

最后,使用最大化对数似然函数,同时优化双层 BiLSTM。
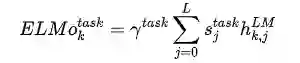

BERT [10]
按照时间顺序应该是 GPT-1 的介绍,但最后决定将 GPT 当作系列来讲,所以放到了后面。
BERT 全称:Bidirectional Encoder Representations from Transformers 不得不说,google 真是起名界的 master,参照 5T、4C。
http://nlp.seas.harvard.edu/2018/04/03/attention.html
关键词:双向语言模型、自编码语言模型、掩码语言模型 MLM,下句预测 NSP 任务。
本文首先从两个部分介绍 BERT 的模型结构,包括:1. 核心结构、输入结构、输出结构。如下图所示。
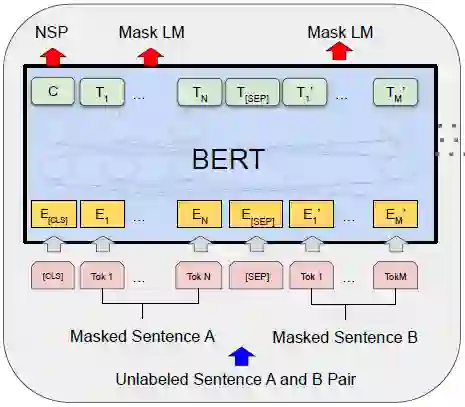 ▲ BERT模型结构
▲ BERT模型结构
BERT的核心结构为基于 Transformer 的、多层的、双向的、编码结构。包含了两个版本的 BERT_base(L=12, H=768, A=12)和 BERT_large(L=24, H=1024, A=16),L 表示 Transformer 的层数,H 表示隐藏层大小,A 表示多头注意力的头数。
除此之外,包含了三个嵌入:Token Embedding、Segment Embeddings 和 Position Embeddings。值得注意的是,Token 不是 word 级别,而是使用 WordPiece 切分的,共包含了 30000 个子词。该操作可以有效降低 OOV。
[CLS] 为分类占位 Token,与该嵌入相关的最后隐层状态表示分类;[SEP] 为句子分割标识。
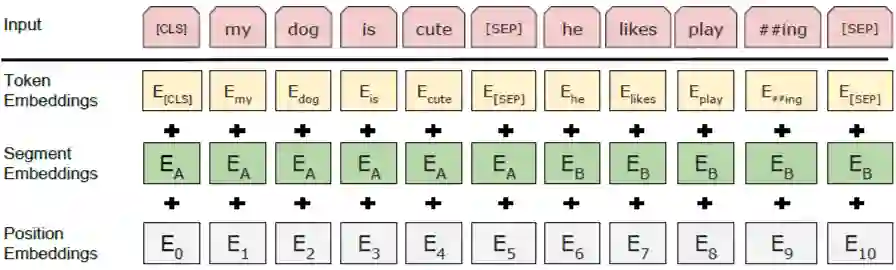
最后结合模型的两个任务,介绍输出层。
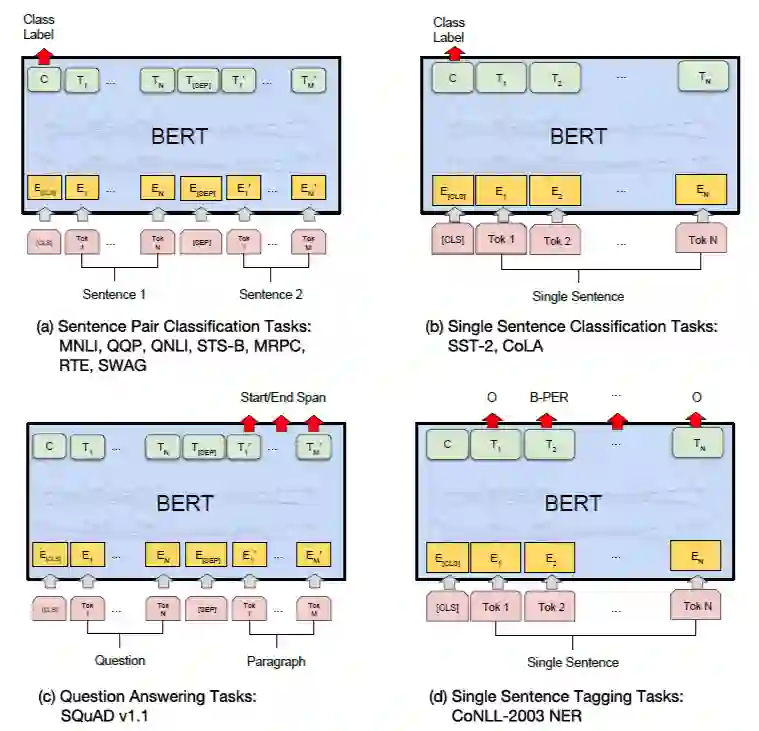
1. 掩码语言模型,常规的条件概率语言模型只能为单向的(从左到右或从右到左),这是因为如果双向的话,会使得每个词间接地看到自己,造成信息穿越。
本文所采用的方案为随机 mask 一些词,然后使用上下文去预测这些词。在一个序列中随机选择 15% 的词进行 mask。但这样会造成一个问题,训练和在下游任务微调时不一致,因为下游任务中不会出现 [mask]。
论文采取一个策略来缓解,当选择第i个词做掩码时,该词 80% 用 [mask] 替代,10% 随机从词汇表中选择一个词替代,还有 10% 保持不变。
2. 上句预测下句,文中介绍是通过建模 QA 和推理任务提出的 NSP,为了更好地理解句子之间的关系。在构造训练集时,A 句子和 B 句子,选择 50%B 为真实下一句,另外 50% 随机选择不是下一句。虽然非常简单,但是文中实验表明在 QA 和推理任务上表现有不错提升。

XLNET [12]
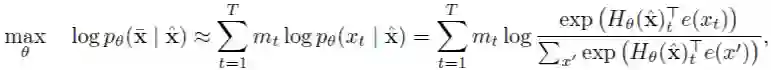
基于上述问题,Carnegie Mellon 和 Google AI Brain 提出了 XLNet。在介绍 XLNet 之前,先提一下所使用的基础模块 Transformer-XL。
Transformer-XL [13] 作为 Transformer 的改进版,主要解决 Transformer 需要输入序列固定长度的问题,即长于输入设定长度的序列只能被截断,或放到下一个 segment。但这样会使得原本的序列信息被切断,因为 segment 之间无法交互。
为解决上述问题,Trm-XL 提出了 segment 级别的递归机制和相对位置编码。Segment-level Recurrence 的大致思想为:当一个输入序列过长时,分割为两个 segments,在计算当前 segment 时,将缓存的上一个 segment 隐层状态拿出,但上层信息仅做前向计算,不再进行反向传播优化。
第二,基于 transformer 的特征抽取网络由于使用自注意力机制无法捕获位置信息,需要在输入端加入位置编码信息,Transformer 使用的绝对位置编码。
Transformer-XL 认为当切分序列后,如果还是用绝对位置编码,第二个 segment将无法区分与第一个 segment 的位置信息。于是提出了相对位置编码,在计算每一层的 attention score 时仅考虑 query 和 key 的相对位置关系。
简单介绍完 Transofmer,转回本小节的主题 XLNet。关于 XLNet 可以介绍两点,即排列语言模型(也可以称为乱序语言模型,因为输入序列是随机排列)和双自注意力通道。
作者为了使得自回归模型能够利用上下文信息,且又不想像 BERT 那样引入 [mask] 噪声,提出了一种序列因式分解进行重新排列的策略。下面将通过一个原文附录中一个例子说明:
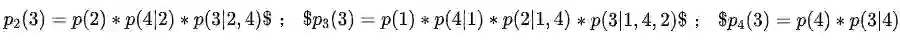
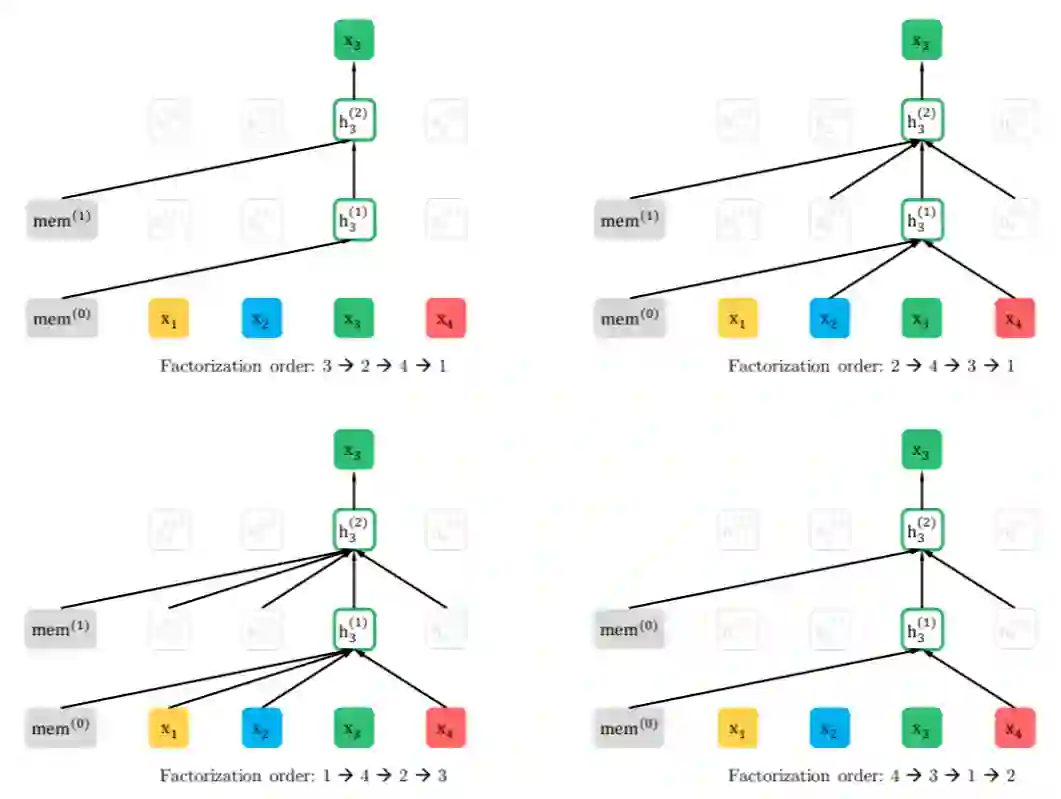
可以看出,通过这种方式不仅可以利用上下文信息,还没有引入 [mask] 噪声。
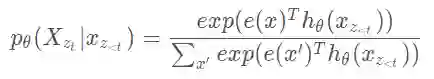
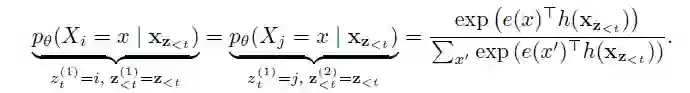
如 t=1 时,序列(1,2,3)和(1,3,2)。
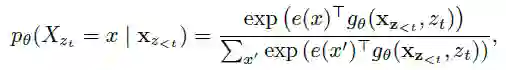
要实现该表示需要主要两个点:
-
预测 token 时,只能使用 位置信息,不能使用文本 ; -
预测 token 时,模型应该把 编码,这样才能包含所有的上下文信息。
-
文本表示 ,简写为 ;
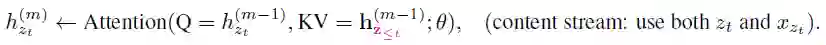
-
query表示 ,简写为 。
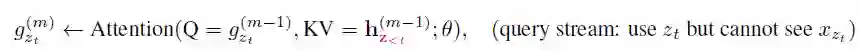
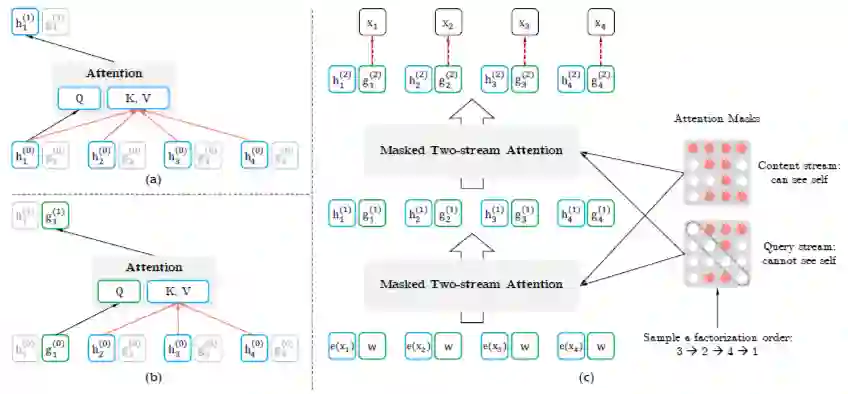
 ▲ Two-Stream Attention
▲ Two-Stream Attention

10.1 GPT
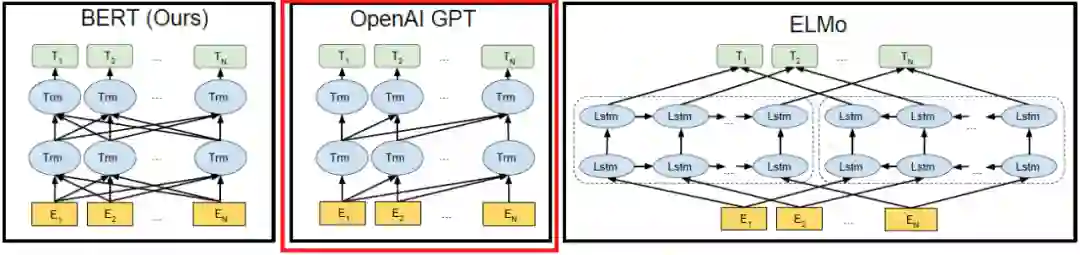 ▲ BERT-GPT-ELMO
▲ BERT-GPT-ELMO
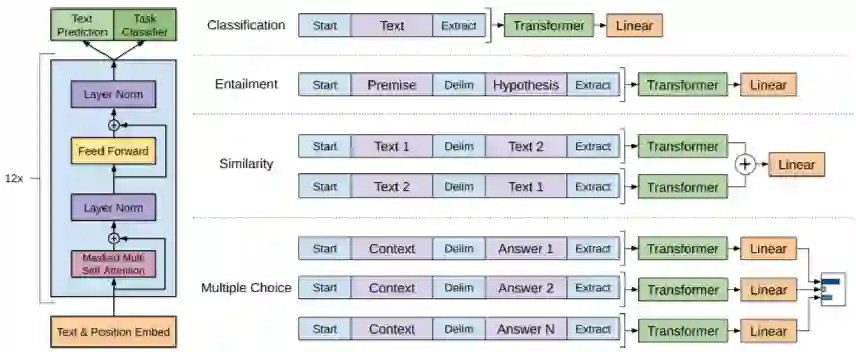
10.2 GPT-2
https://jalammar.github.io/illustrated-gpt2/
GPT-2 从名称可知论文认为语言模型本身蕴含了各种 NLP 的任务(Language Models are Unsupervised Multitask Learners),特别在摘要中提及使用爬取的百万网页训练的语言模型,可以在 CoQA 数据集上输入问题,得到 F155% 的答案。
总体看下来,相较 GPT,GPT-2 在模型上并无特别大的改进,主要是使用了更大的语料集、更大的模型,以及在输入和模型上做了一些改进。
语料集:通过爬虫获得了大量的网页文本,论文取名为 WebText,包含了 4500 万链接,经过去重及一些预处理操作,最终得到 8 百万的文本,共计 40GB 的数据。(为了测试下游任务,移除了 wikipedia 的文本)
输入表示:没有使用一些预处理操作:转小写、分词、等操作,而是使用 BPE(Byte Pair Encoding)做切分,BPE 的过程是按频率合并单个字母。
10.3 GPT-3
继续沿用陈述句标题,论文重心来到小样本学习。首先抛出两段式(预训练+微调)预训练语言模型的存在的问题:
1. 在下游任务上仍然需要一定量的标签数据;2. 微调阶段常规是先用大学习率预训练模型和下游模型一起训练,然后再固定预训练模型参数,用小学习率继续优化下游模型,如果下游任务数据较小时仍会过拟合,PTMs 此时的泛化能力并不好。
既然提到了上述问题,论文就着重在 Zero Shot, One Shot, few Shot 三个场景下进行 PTMs 的一系列验证,这里仅给出前三个图的对比。
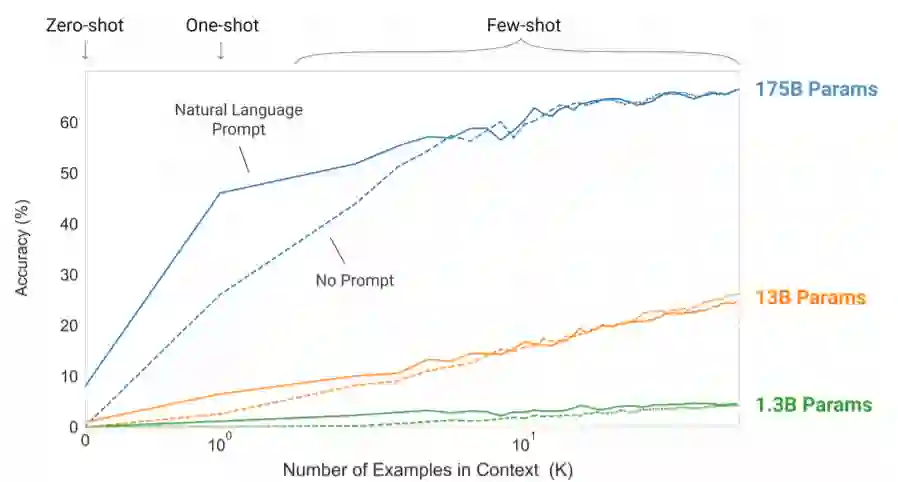
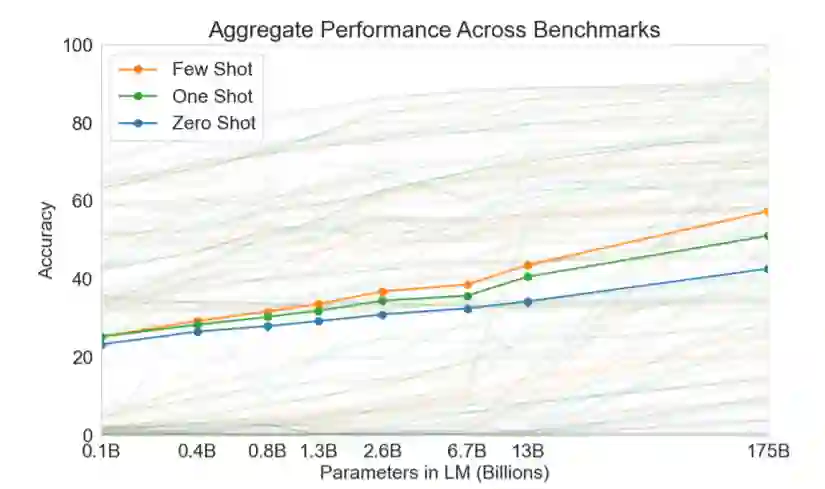
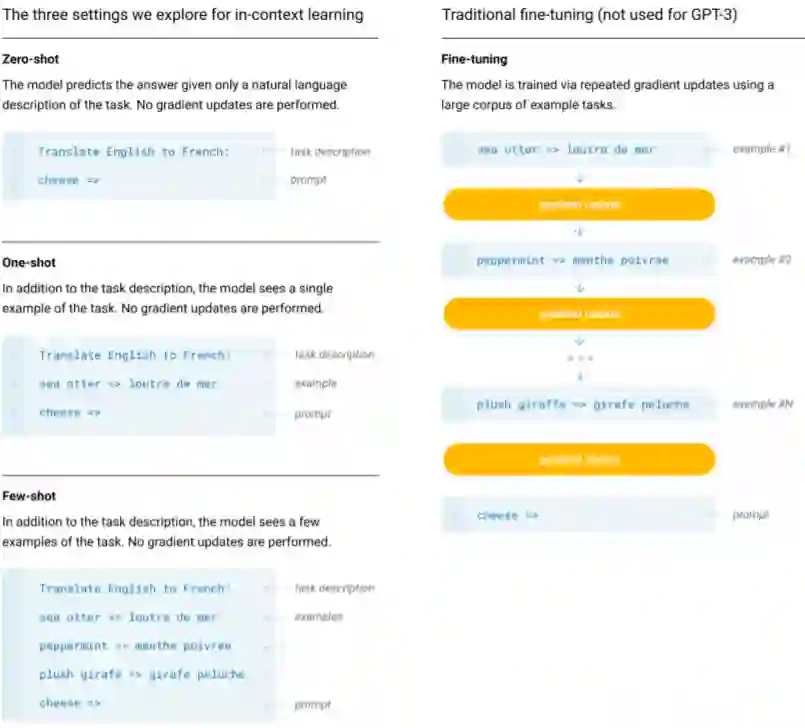
总得来说,当 GPT-3 出来后,一些人宣称无需再 finetune,GPT-3 就够了,就我看来仍有很长路要走,直接在下游任务上推理,工程应用就是一个很大的问题!

总结
本文是对神经网络语言模型的一份总结,特别是近两年较火的 PTMs,由于各个预训练语言模型迭代较快,仅对其中几个流行度较高的模型进行介绍(在中文上 ERINE 挺好)。

参考文献
[1] 宗成庆,《统计自然语言处理》
[2] Hinton,《Learning distributed representations of concepts》
[3] Benjio,《A neural probabilistic language model》
[4] 《efficient estimation of word representations in vector space》
[5] 《distributed representations of words and phrases and their compositionality》
[6] peghoty,《word2vec中的数学原理》
[7] 《word2vec parameter learning explained》
[8] 《GloVe: Global Vectors forWord Representation》
[9] 《Deep contextualized word representations》
[10] 《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
[11] 《Attention is all your need》
[12] 《XLNet: Generalized Autoregressive Pretraining for Language Understanding》
[13] 《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
[14] 《Improving Language Understanding by Generative Pre-Training》
[15] 《Language Models are Unsupervised Multitask Learners》
[16] 《Language Models are Few-Shot Learners》
更多阅读



#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。