成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
RDF
关注
5
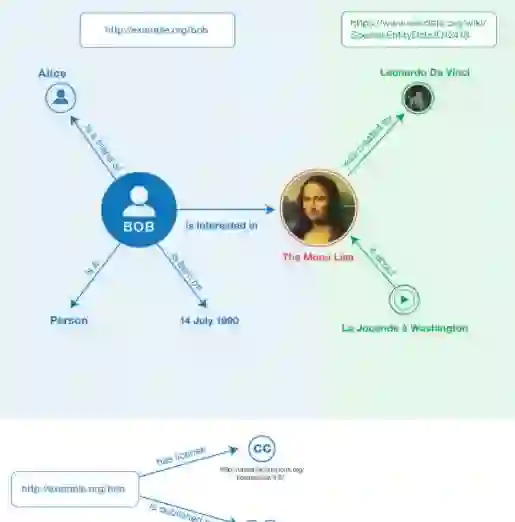
资源描述框架(英语:Resource Description Framework,缩写为RDF),是万维网联盟(W3C)提出的一组标记语言的技术规范,以便更为丰富地描述和表达网络资源的内容与结构。
综合
百科
VIP
热门
动态
论文
精华
虚拟专辑丨知识图谱
开放知识图谱
1+阅读 · 2022年11月9日
【密苏里大学博士论文】《使用机器学习技术丰富知识图谱》
专知
1+阅读 · 2022年8月26日
北大关于知识图谱与图数据库的研究工作
专知
2+阅读 · 2022年8月13日
【博士论文】《评估、创建和使用知识图谱的限制》2022最新230页博士论文,根特大学
专知
1+阅读 · 2022年8月9日
技术动态 | W3C计划成立RDF-star工作组
开放知识图谱
0+阅读 · 2022年4月18日
图谱实战 | 基于半结构化百科的电影KG构建、查询与推理实践记录
开放知识图谱
1+阅读 · 2021年12月15日
领域应用 | 完备的娱乐行业知识图谱库如何建成?爱奇艺知识图谱落地实践
开放知识图谱
0+阅读 · 2021年8月5日
新瓶装旧酒:实践篇(四)Apache jena SPARQL endpoint及推理
AINLP
1+阅读 · 2020年9月25日
论文浅尝 - WSDM2020 | QAnswer KG: 基于RDF数据设计一个可移植问答系统
开放知识图谱
1+阅读 · 2020年8月19日
新瓶装旧酒:实践篇(三)D2RQ SPARQL endpoint与两种交互方式
AINLP
1+阅读 · 2020年7月24日
新瓶装旧酒:RDF查询语言SPARQL
AINLP
0+阅读 · 2020年7月21日
《人工智能之图数据库》报告重磅发布
学术头条
2+阅读 · 2020年7月20日
论文浅尝 - ESWC2020 | ESBM:一个面向实体摘要的评测集
开放知识图谱
1+阅读 · 2020年7月18日
新瓶装旧酒:实践篇(二)关系数据库到RDF
AINLP
0+阅读 · 2020年7月15日
新瓶装旧酒:知识图谱基础之RDF,RDFS与OWL
AINLP
3+阅读 · 2020年7月12日
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top