论文题目: Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation
论文摘要:
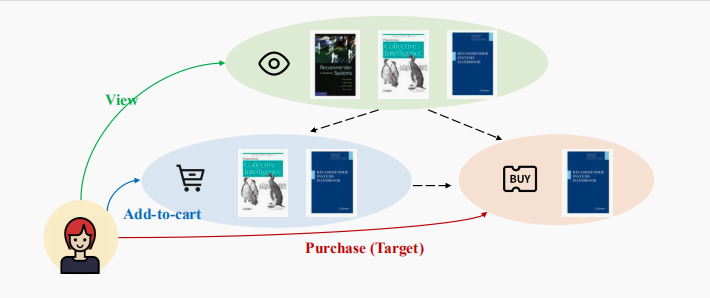
最近关于推荐的研究主要集中在探索最先进的神经网络,以提高模型的表达能力,同时通常采用负抽样(NS)策略来提高学习效率。尽管有效,现有方法中有两个重要问题没有得到充分考虑:1) NS波动剧烈,基于抽样的方法在实际应用中难以获得最优的排序性能;2)尽管异构反馈(如查看、单击和购买)在许多在线系统中广泛存在,但大多数现有方法仅利用一种主要类型的用户反馈,如购买。在这项工作中,我们提出了一种新的非抽样转移学习解决方案,命名为高效异构协同过滤(EHCF),用于Top-N推荐。它不仅可以对细粒度的用户-项目关系进行建模,而且可以从整个异构数据(包括所有未标记的数据)中高效地学习模型参数,并且具有较低的时间复杂度。对三个真实数据集的大量实验表明,EHCF在传统(单一行为)和异构场景中都显著优于最先进的推荐方法。此外,EHCF在培训效率方面有显著的改进,使其更适用于真实世界的大型系统。我们的实现已经发布,以促进更有效的基于全数据的神经方法的进一步发展。
论文作者:
张敏博士是清华大学计算机科学与技术系的终身副教授,专门从事网络搜索和推荐以及用户建模。她是计算机系智能技术与系统实验室副主任,清华-MSRA媒体与搜索实验室执行主任。她还担任ACM信息系统事务(TOIS)的副编辑,SIGIR 2019教程主席,SIGIR 2018短论文主席,WSDM 2017项目主席等。发表论文100余篇,被引用次3500余次,H指数32分。2016年获北京市科技奖(一等奖),2018年获全国高校计算机科学优秀教师奖等。她还拥有12项专利,并与国内外企业进行了大量的合作。
马少平是清华大学智能技术与系统国家重点实验室计算机科学与技术系教授,研究领域为智能信息处理, 信息检索。主要研究兴趣是智能信息处理,主要集中在信息检索与Web信息挖掘等方面,尤其研究基于网络用户行为分析的语义挖掘,以改进搜索引擎的性能。