

摘要
近年来,随着 ChatGPT 等服务推动大语言模型(LLM)的快速普及,一批专门面向 LLM 推理的系统相继涌现,如 vLLM、SGLang、Mooncake 和 DeepFlow。这些系统设计工作的核心动因是 LLM 请求处理过程中所特有的自回归特性,该特性促使研究者提出多种新技术,以在应对高吞吐量与高并发负载的同时,兼顾推理性能与结果质量。尽管相关技术在文献中已有广泛讨论,但尚未在完整推理系统的框架下进行系统性分析,现有系统之间也缺乏深入的对比与评估。 本综述系统梳理了上述技术,内容涵盖从请求处理所涉及的算子与算法出发,逐步延伸至模型优化与执行相关技术(包括算子内核设计、批处理机制与调度策略),最后探讨内存管理方面的方法,例如分页内存、淘汰与卸载策略、量化和缓存持久化。通过上述分析,我们指出这些技术在本质上依赖于负载预测、自适应机制与成本优化,以克服自回归生成所带来的挑战,并实现系统设计目标。随后,我们进一步探讨了如何将这些技术组合构建单副本与多副本推理系统,其中包括资源解耦型推理系统(disaggregated inference systems),它们可实现更灵活的资源分配,以及可部署于共享硬件基础设施上的无服务器系统(serverless systems)。最后,我们讨论了该领域仍然面临的若干关键挑战。
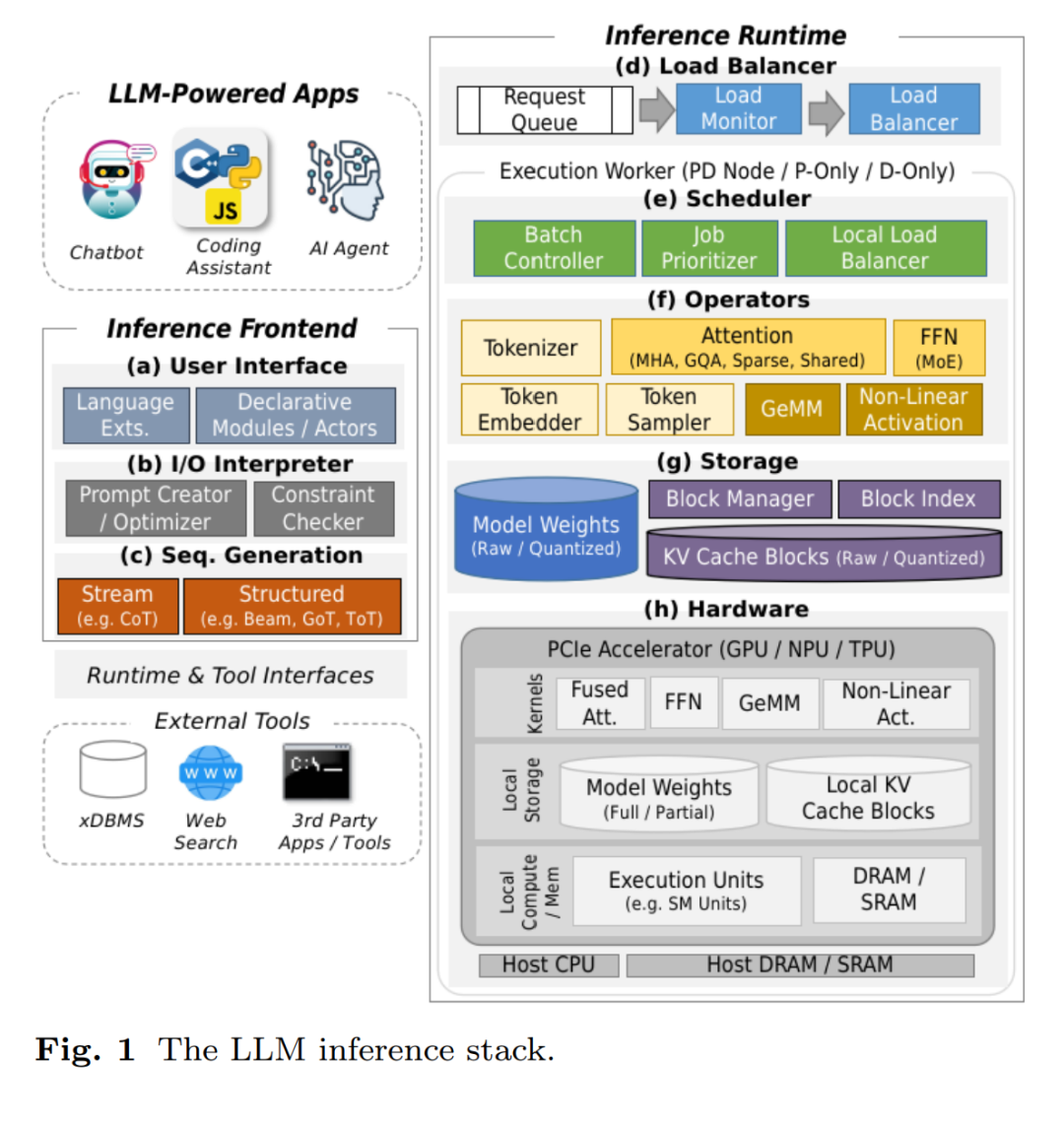
1 引言
自从序列生成任务从循环神经网络(RNN)转向 Transformer 架构以来 [97],大语言模型(LLM)的质量已显著提升,使其能够胜任各类任务,包括通用交互式问答 [9]、文档摘要与分类 [96]、语言翻译 [27]、代码生成 [16]、数据整理 [72] 以及非结构化数据分析 [100]。这一技术突破推动了 LLM 在工业界和消费市场的指数级增长,ChatGPT、Gemini、Claude、Grok、Kimi 和 DeepSeek 等服务的迅速普及也对高性能模型服务系统提出了更高要求。 为了满足这一需求,研究者开发了专门的 LLM 推理系统,用于管理模型执行的各个方面。这不仅包括基本的 LLM 推理流程,还涵盖系统层面的负载均衡、任务批处理、调度策略以及内存管理等,借鉴了早期高吞吐量、高速数据处理系统的设计经验。然而,由于基于 Transformer 的 LLM 推理具有自回归生成这一独特特性,导致上述各方面均需采用新技术进行改造。 与传统数据处理系统通过单次执行一系列算子完成请求处理不同,LLM 推理通常需要多轮执行,次数与输出长度成正比。每个请求的输入形式都是文本字符串,输出长度则以非确定性的方式依赖于文本内容。由于用户可以输入任意内容,几乎无法定义“典型”的输出长度,因此请求处理成本(尤其是内存成本)在不同请求之间可能出现极大差异,即使它们的输入表面上相似1。 这种输出的根本非确定性为 LLM 推理系统带来了三大关键挑战:(1)尽管近期取得了显著进展,但模型输出的质量(即输出是否满足请求表达的任务目标)仍无法保证,因为其生成过程基于随机采样而非确定性数据构建;(2)执行轮数的不确定性使得每个请求的最终内存使用量难以预估,给多请求并发处理带来分配难题;(3)同样地,请求处理所需时间也不可预知,因此在设计批处理与调度策略时,必须考虑如何避免“拖后腿请求”(straggler)与“队头阻塞”(head-of-line blocking)等问题。 为应对上述挑战,LLM 推理系统采用了一系列贯穿前端与运行时的技术策略,如图 1 所示。为了提升推理质量,系统支持包括 beam search、思维树(Tree-of-Thoughts)、思维图(Graph-of-Thoughts)与自一致性(self-consistency)等多种序列生成方法(图 1(c)),还结合多种提示工程技巧。同时,前端设计也趋于多样化,以简化用户交互流程(图 1(a)),支持如自动提示优化与受控输出生成(图 1(b))等功能,从而减轻提示设计与流程协调的负担。 为了适应动态内存需求,推理系统使用基于页的块式内存分配策略,辅以缓存持久化与量化技术,以降低整体内存消耗(图 1(g))。而面对动态请求生命周期,系统依赖基于负载预测机制的动态任务调度、动态批处理与灵活负载均衡策略(图 1(d, e)),并通过专用算子与高效内核实现来降低总体推理成本(图 1(f, h))。 本综述将在一个完整推理系统的框架下系统性地讨论这些技术。在第 2 节中,我们介绍实现高质量 LLM 推理所需的基本算子与序列生成算法;第 3 节聚焦批处理与调度技术,以及面向专用硬件的高效内核设计;第 4 节则讨论内存管理策略,包括页式内存、支持请求抢占与长上下文的淘汰与卸载机制、量化方法,以及缓存持久化与重建技术。随后在第 5 节,我们探讨如何将上述技术整合,构建当前主流的 LLM 推理系统,包括部署单个模型副本的系统与支持多副本请求调度的系统,后者特别适用于构建具备资源解耦能力的系统架构,可更灵活地进行硬件资源分配。
相关综述工作
虽然已有一些综述涵盖文中提及的部分技术,但多数研究是在缺乏完整系统框架的前提下对这些技术进行孤立讨论。例如,[47, 54, 116, 139] 涉及稀疏注意力、专家混合(MoE)、解码策略、KV 缓存管理和量化技术等,但均未将其置于系统整体架构中加以讨论。[55] 从 KV 缓存管理的角度对若干技术进行了分类总结。[15] 等则主要关注模型架构方面,如模型剪枝、知识蒸馏与量化等优化技术。[48] 更专注于提升推理质量的方法。因此,本文的独特贡献在于将这些技术系统化地整合进完整推理系统设计中,并探讨它们在实际部署中的协同作用。
