自然语言处理(二)机器翻译 篇 (NLP: machine translation)
上篇给大家介绍了几种 NLP 中的语言模型,其中 RNN 比 neural network language model (NNLM) 和 n-gram language model 有明显的优势:RNN 考虑到前面所有的 word,而 NNLM 和 n-gram 都是基于马可夫假设的,所以第 n +1 个 word 的概率只取决于它的前 n 个 word。不过常规 RNN 的问题是:在参数学习阶段,通过 back propagation 来更新参数时,会有 gradient explosion / vanishing 问题。后期学者们提出的 LSTM (long-short term memory) 和 GRU (gated recurrent unit) 都是用来解决这个问题的,而 LSTM 和 GRU 本质上仍然属于 RNN。
我们首先介绍 RNN 与 HMM 和 LDS 的区别和联系,然后讲述怎样用 RNN 来建立机器翻译模型。
(1) RNN vs. HMM / LDS
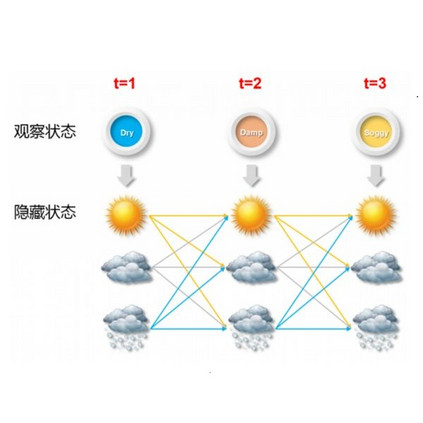
如果把 RNN 在时间维度展开,它也是一条 linear chain,它与 Hidden Markov Model (HMM) 和 Linear Dynamic System (LDS) 有着相似的结构。那么 RNN 跟 HMM 和 LDS 的区别和联系是什么呢?
HMM 与 LDS 是两种简单的 Dynamic Bayesian Network (DBN)。HMM 的 state space 是离散随机变量,而 LDS 的 state space 是连续随机变量,并且服从高斯分布。线性离散和高斯分布都会给 inference 带来便利,所以它们都有 exact inference 算法,如 Viterbi algorithm, Kalman filter 等。如果 hidden state 是连续但不服从高斯分布的话,那么 exact inference 就是一个大问题,这时我们需要使用 approximate inference 算法,如 particle-based inference (e.g. MCMC) 和 variational inference (e.g. EM)。在 HMM 或 LDS 的参数学习阶段,目标是 maximize marginal likelihood,其中观测值 (observed variable) 的 marginal probability 需要通过对 hidden state 积分得到。
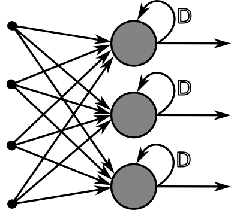
再说 RNN,它虽然也是一条 linear chain,但它是 deterministic 的:hidden state 到 hidden state 的 transition 是固定的而不是随机的,hidden state 到 observation state 也是固定的。既然 RNN 是一个 deterministic parametric model,一旦通过 back propagation 学习参数后,inference 就相当容易了,不需要对 hidden state 积分或求和。所以,RNN 中 hidden state 可以是任意连续的向量,不需要对它的分布做任何假设。我们今后会特别讲解 RNN 的技术细节。
(2) 机器翻译 (machine translation)
机器翻译就是把A语言翻译成B语言。目前最好的机器翻译模型 (translation model) 是基于 Neural Nets 的,它使用 neural network 建立了一个条件概率 (conditional distribution) 模型:给定一个 source sentence - Sa (A语言),那么 target sentence - Sb (B语言) 的条件概率是多少,也就是 p( Sb | Sa )。在2014年的NIPS会议上,Ilya Sutskever et al. 发表了一篇关于机器翻译的经典文章:Sequence to Sequence Learning with Neural Networks。文章中将机器翻译分为两个阶段,encode source sentence 和 decode target sentence。首先用一个 encoding LSTM 来对 source sentence 进行编码,得到一个固定维数的向量 C;然后,以 C 为输入,用另一个 decoding LSTM 来解码得到 target sentence。
在参数学习阶段,通过 back propagation 来联合训练两个 LSTM 里面的参数。在翻译阶段,给定A语言的一句话,如何把它翻译成B语言呢?先通过 encoding LSTM 得到 A 的编码后,把该编码输入到 decoding LSTM 中,就可以按顺序地得到每个词了,这一系列词就组成了 target sentence。想得到条件概率最大的 target sentence,也就是使 p( Sb | Sa ) 最大的 Sb,brute force search 是不可取的,实际中一般使用 beam search algorithm 来得到若干个条件概率较大的 candidate sentences。这种 encoding-decoding 模式是解决 机器翻译 问题非常有效的框架,它不仅启发了后续一系列的改进模型,还启发了计算机视觉领域中的 image / video description 研究。
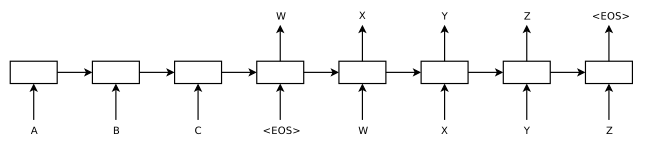
基于以上的 encoding-decoding 框架的 翻译模型 有一个突出的问题:使用 encoding LSTM 模型,把整个 source sentence 压缩成了一个固定长度的向量 C,而这个向量 C 是下一个 decoding LSTM 的唯一输入。这样导致的问题是,对于短句子的翻译效果不错,可是翻译长句子时,BLUE score 明显下降 (BLUE score 是一种度量机器翻译质量的测度)。直观上其实很好理解:如果以整个 source sentence 的编码向量作为 decoding LSTM 的输入,那么 source sentence 中的 temporal 信息以及每个词自身的信息都丢失掉了。为了解决这个问题,Dzmitry Bahdanau et al. 在 Neural Machine Translation by Jointly Learning to Align and Translate 文章中提出了 jointly align and translate 机器翻译模型。它仍然是基于 encoding-decoding 框架的,核心的不同是,decoding LSTM 的输入不是整个 source sentence 的编码向量 C,而是 encoding LSTM 得到的 source sentence 里每个词的编码向量,这样每个词的信息都保留了下来。他们的模型不仅可以翻译整个句子,而且还可以把翻译得到的每个词对应到 source sentence 的每个词。这篇文章值得好好读一读。
好了,这里我们主要给大家讲解了目前最优的机器翻译模型。大家对模型的细节可能还存在不少疑惑。在后面的文章里 (不一定在“自然语言处理”系列),我们会深入到 RNN 和 LSTM 的技术细节里。
DeepLearning中文论坛公众号的原创文章,欢迎转发;如需转载,请注明出处。谢谢!
长按以下二维码,轻松关注DeepLearning