
报告主题: Neural Architecture Search and Beyond
报告简介:
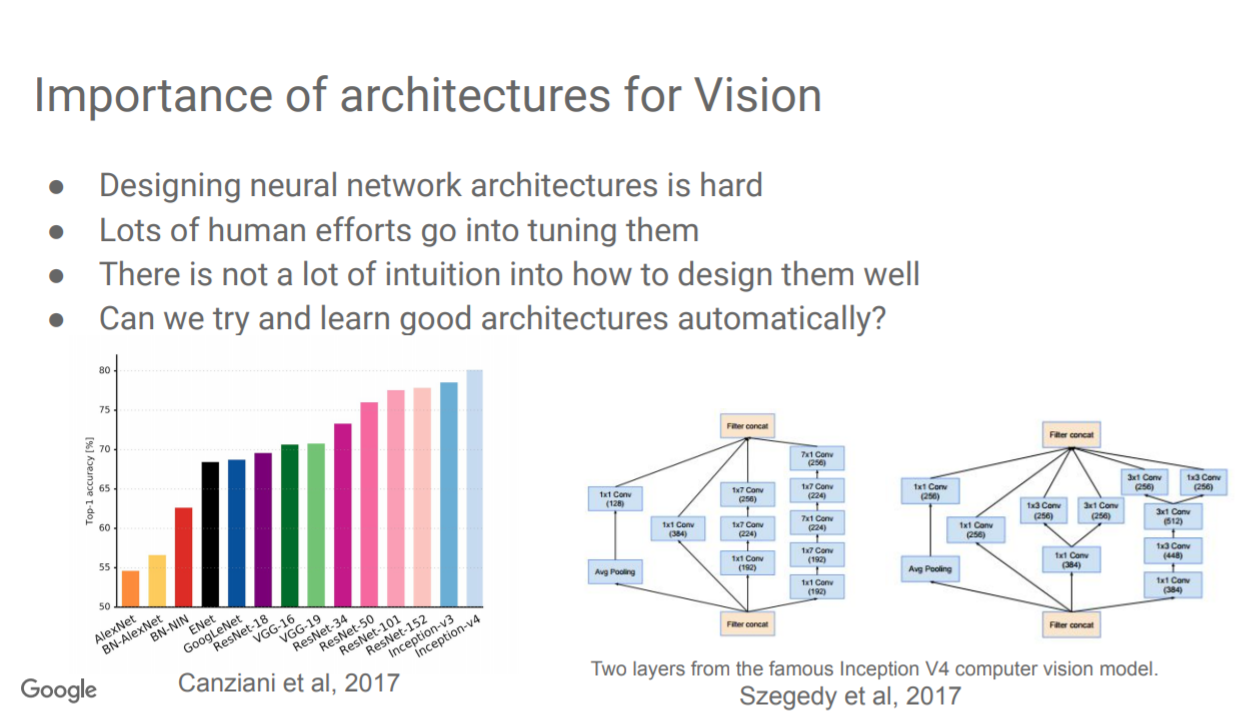
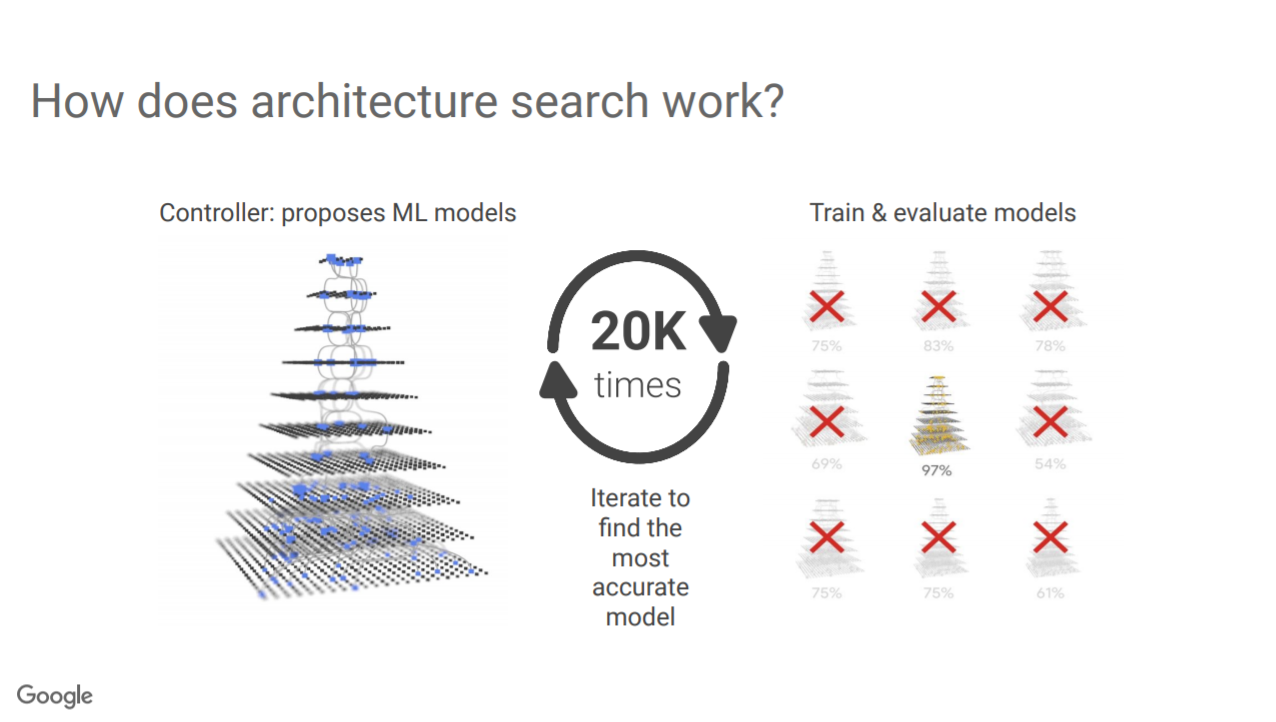
神经网络结构搜索(NAS)是一种自动化设计人工神经网络的技术。由于NAS能设计出与手工设计神经网络结构相当甚至优于手工设计结构的网络,而成为近两年深度学习社区的研究热点。来自Google的科学家Barret Zoph,ICCV2019上做了《Neural Architecture Search and Beyond》的报告,讲述了Google在NAS方面的最新研究进展。
嘉宾介绍:
Barret Zoph目前是谷歌大脑团队的高级研究科学家。之前,在信息科学研究所与Kevin Knight教授和Daniel Marcu教授一起研究与神经网络机器翻译相关的课题。
成为VIP会员查看完整内容


相关内容

Barret Zoph目前是谷歌大脑团队的高级研究科学家。之前,在信息科学研究所与Kevin Knight教授和Daniel Marcu教授一起研究与神经网络机器翻译相关的课题。
专知会员服务
49+阅读 · 2020年2月15日
专知会员服务
28+阅读 · 2019年11月26日
专知会员服务
23+阅读 · 2019年11月10日
Arxiv
7+阅读 · 2019年4月16日
相关主题



相关VIP内容
专知会员服务
49+阅读 · 2020年2月15日
专知会员服务
28+阅读 · 2019年11月26日
专知会员服务
23+阅读 · 2019年11月10日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月16日