

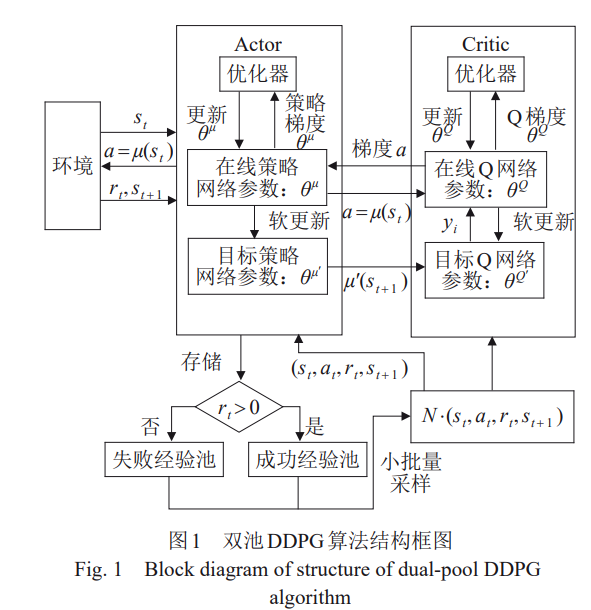
针对无人机在复杂环境下进行路径规划时,存在收敛性差和无效探索等问题,提出一种改进型深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法。采用双经验池机制,分 别存储成功经验和失败经验,算法能够利用成功经验强化策略优化,并从失败经验中学习避免错 误路径;引入人工势场法为规划增加引导项,与随机采样过程中的探索噪声动作相结合,对所选 动作进行动态整合;通过设计组合奖励函数,采用方向、距离、障碍躲避及时间奖励函数实现路 径规划的多目标优化,并解决奖励稀疏问题。实验结果表明:该算法的奖励和成功率能够得到显 著提高,且能够在更短的时间内达到收敛。
成为VIP会员查看完整内容
相关内容

Arxiv
38+阅读 · 2023年4月19日
Arxiv
205+阅读 · 2023年4月7日
Arxiv
141+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
205+阅读 · 2023年4月7日
Arxiv
141+阅读 · 2023年3月29日