为了应对在未来复杂的战场环境下, 由于通信受限等原因导致的集中式决策模式难以实施的情况, 提出了一个基于多智 能体深度强化学习的分布式作战体系任务分配算法, 该算法为各作战单元均设计一个独立的策略网络, 并采用集中式训练、分布 式执行的方法对智能体的策略网络进行训练, 结果显示, 经过学习训练后的各作战单元具备一定的自主协同能力, 即使在没有中 心指挥控制节点协调的情况下, 依然能够独立地实现作战任务的高效分配.
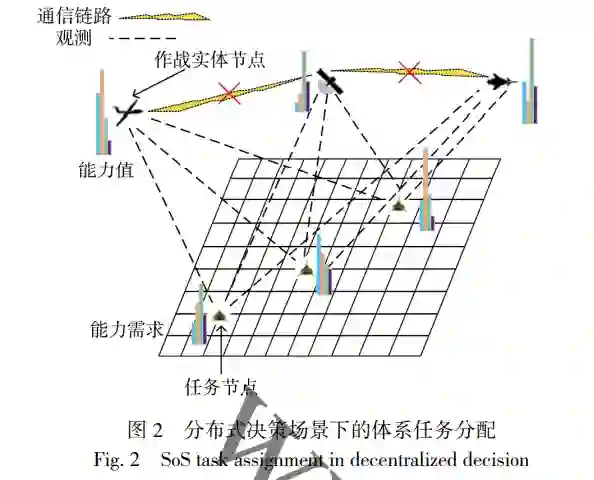
马赛克战[1]、联合全域指挥控制[2]等新型作战概 念所构想的未来作战场景中, 传统的多任务平台被 分解为了众多的小型作战单元, 这些小型作战单元 通常具备更高的灵活性, 能够根据战场环境的变化 快速对自身所承担的任务进行调整, 以实现更好的 整体作战效果. 在未来的新型作战场景中, 传统的集 中式指挥控制模式存在着指挥链路过长、决策复杂 度过高等问题, 从而导致决策时效性和决策质量难 以满足要求[3] . 近年来, 边缘指挥控制等新型指挥控制 模式应运而生, 边缘节点也即各作战实体将具备一 定程度的自主决策能力[4] . 由于战场环境的复杂多变 特性, 以及作战实体的小型化、智能化发展趋势, 分 布式决策的模式将在未来的战场决策中发挥越来越 重要的作用. 作战体系是为了完成特定的作战任务由一系列 具备各项能力的作战单元动态构建而成, 在以往的 集中式决策模式下, 体系设计人员会根据作战任务 的能力需求以及作战单元所具备的各项能力, 以最 大化作战效能或最小化作战单元的使用成本等为目 标, 来统一地对各作战任务和作战单元进行匹配. 作 战体系的“作战任务—作战单元”匹配问题可以建模 为一个优化问题, 当问题规模较小时, 可以采用集中 式决策的模式运用整数线性规划等运筹学方法快速 得到全局最优解[5] , 而当问题规模较大时可以采用遗 传算法等启发式算法[6]或者强化学习算法[7] , 得到问 题的近似最优解. 采用集中式决策的一个重要前提 条件是中心决策节点和作战单元叶节点之间的通信 畅通, 因为叶节点需要将自身的状态信息和观测信 息发送给中心决策节点, 而中心节点需要将决策命 令发送给叶节点. 然而在未来的作战场景中, 由于敌 方的通信干扰等原因, 中心节点和叶节点之间的通 信链接很难保证连续畅通, 同时频繁的信息交互会 造成一定的通信负载和通信延迟, 因此, 在未来很多 的任务场景中, 需要作战单元根据自身的状态信息 和观测到的信息独立地进行决策.
强化学习是一种利用智能体与环境的交互信息 不断地对智能体的决策策略进行改进的方法, 随着深度强化学习技术的快速发展, 强化学习算法在无 人机路径规划[8]、无线传感器方案调度[9]等领域都取 得了非常成功的应用, 同时近年来多智能体强化学 习算法在 StarCraft域[10]等环境中也取得了很好的效 果. 在作战体系任务分配场景中, 可以将各作战单元 视为多个决策智能体, 那么“作战任务—作战单元” 的匹配任务可以视为一个多智能体强化学习任务. 而当前尚未有将多智能体强化学习方法应用到类似 作战体系的任务分配环境中的先例. 本文的主要工 作如下: 1)建立一个通信受限情况下的作战体系“作 战任务—作战单元”匹配的任务场景;2)提出了一 个基于多智能体强化学习技术的作战体系任务分配 算法;3)通过实验验证了采用上述算法训练的各智 能体, 可以在通信受限的场景下, 实现一定程度的自 主协同, 在没有中心决策节点的情况下依然能够实 现作战体系任务的有效分配