「基于通信的多智能体强化学习」 进展综述

强化学习 (reinforcement learning, RL) 技术经历了数十年的发展, 已经被成功地应用于连续决 策的环境中. 如今强化学习技术受到越来越多的关注, 甚至被冠以最接近通用人工智能的方法之一. 但 是, 客观环境中往往不仅包含一个决策智能体. 因此, 我们更倾向于以多智能体强化学习 (multi-agent reinforcement learning, MARL) 为技术手段, 应对现实的复杂系统. 近十年来, 多智能体系统 (multiagent system, MAS) 和强化学习的结合日渐紧密, 逐渐形成并丰富了多智能体强化学习这个研究方向. 回顾 MARL 的相关工作, 我们发现研究者们大致从学习框架的讨论、联合动作学习, 以及基于通信的 MARL 这 3 个角度解决 MARL 的问题. 而本文重点调研基于通信的 MARL 的工作. 首先介绍选取基 于通信的 MARL 进行讨论的原因, 然后列举出不同性质的多智能体系统下的代表性工作. 希望本文能 够为 MARL 的研究者提供参考, 进而提出能够解决实际问题的 MAS 方法.
1 引言
如今, 强化学习 (reinforcement learning, RL) 作为人工智能领域中的热门话题之一, 吸引了很多不 同专业领域学者的关注. 强化学习的本质 [1] 是让智能体在与环境的不断交互中, 通过尝试和犯错, 学 习如何在特定的时间段中作出合适的序列性决策以解决社会和工程中遇到的问题. 强化学习的发展过程有着鲜明的特征. 在 20 世纪 50 ∼ 60 年代以前, 关于 RL 的探索都局限于 反复的试错. 而后, 贝尔曼提出贝尔曼方程 (Bellman equation) 以及离散的动态系统中的最优控制理 论并且将其建模为马尔可夫决策过程 (Markov decision process, MDP). 然而最优控制的潜在前提是我 们知道系统相关的所有特性, 实际上这个前提往往是无法满足的. 这一点恰恰是强化学习的独特研究 背景之一. 在 20 世纪 60 年代, “Reinforcement Learning” 第一次出现在了工程领域的试错方法总结 中. 其中影响最深远的就是 Minsky 的工作 [2], 其中提到了试错和信任分配 (credit assignment) 的问题, 这些都是强化学习的起源. 此后研究者们从未知环境中试错的出发点提出了基于时序差分的方法 (temporal differences, TD) [3]、Q- 学习 [4] 和 SARSA [5] . 当时的 RL 技术还处于比较朴素的阶段, 主要针对的是规模较小的离散状态离散动作的场景. 当 状态或者动作空间连续时, 便无法得到准确的值函数. 这时就需要对值函数进行近似, 从而产生了基 于值函数 (value based) 的强化学习方法. 此外, 如果直接对策略进行近似, 学习的目标就可以直接定 义为最优策略搜索 (policy search) 的性能. 如果在策略近似的同时还引入了值函数的近似, 并且策略 是基于值函数的评价而更新的, 这类方法属于策略近似的一种特殊形式, 称为 Actor-Critic 方法, 其中 的 Actor 指的是策略, Critic 指的是值函数.
自从 2015 年, Mnih 等 [6] 在 Atari 环境中利用深度 Q- 学习取得了突破性进展之后, 深度强化学 习 (deep reinforcement learning, DRL) 便开始在机器学习、人工智能领域掀起了一阵热潮. 研究者们 不断发现 DRL 的巨大潜力, 不论是机器人控制 [7]、优化与调度 [8] , 或者是游戏和博弈 [6, 9] 等方面都 能够借助于 DRL 来解决. 而当 DRL 在解决现实问题的时候, 研究者们往往高估了它的能力, 低估了 实现它的难度 [10] . 事实上, 现实世界中的问题是十分复杂的. 本文总结, 现实世界的复杂性很大程度上体现在: 多 数任务所涉及的系统规模较为庞大, 并且根据一些规则或者常识可以分解为多个完成不同子任务的个 体. 为了完成某个任务, 系统需要多个智能体同时参与, 它们会在各自所处的子空间分散执行任务, 但 从任务层面来看, 这些智能体需要互相配合并且子决策的结果会互相影响. 这样的系统可以被称为多 智能体系统 (multi-agent system, MAS). 在多智能体系统中, 各个智能体需要在环境不完全可知的情 况下互相关联进而完成任务. 简而言之, 它们可以互相协同, 或者互相竞争, 也可以有竞争有合作. 如 果将强化学习技术用于上述场景中, 相异于传统强化学习场景的是, 在这种系统中, (1) 至少有两个智 能体; (2) 智能体之间存在着一定的关系, 如合作关系、竞争关系, 或者同时存在竞争与合作的关系; (3) 每个智能体最终所获得的奖赏会受到其余智能体的影响. 通常, 我们将这种场景下的强化学习技术称 为多智能体强化学习 (multi-agent RL, MARL). MARL 场景中的环境是复杂的、动态的. 这些特性给 学习过程带来很大的困难, 例如, 随着智能体数量的增长, 联合状态及动作空间的规模会呈现出指数扩 大, 带来较大的计算开销; 多个智能体是同时学习的, 当某个智能体的策略改变时, 其余智能体的最优 策略也可能会变化, 这将对算法的收敛性和稳定性带来不利的影响。
针对上述 MARL 的困难, 研究者们提出智能体可以在动态的环境中借助于一些辅助信息弥补其 不可见的信息, 从而高效学得各自的策略. 为了达到这个目的, 研究者们提出了一些方法, 可以大致被 分为以下几类: (1) 学习框架的讨论, 这类工作意在探索一种可行的学习框架, 因此这类工作更多地 偏向于将已有的机器学习 (machine learning, ML) 研究背景或者 RL 技术向 MAS 的场景中作融合; (2) 联合动作学习, 这类方法基于单智能体的视角, 即将多个智能体合并为一个整体, 而原本各个智能 体的动作则被视为系统 “子部件” 的动作, 但是这类方法在状态动作空间维数较高时会面临学习效率 不高的问题; (3) 智能体之间的通信, 即智能体通过发送和接收抽象的通信信息来分析环境中其他智能 体的情况从而协调各自的策略. 学习框架和联合的多动作学习算法主要依赖于集中式的训练学习或者 直接共享某些局部信息等条件. 不难发现, 更容易适应于现实系统的是基于通信的这类方法: 集中各 个智能体, 并使各个智能体分享的局部信息的训练模式在实际应用中很难满足. 因此, 我们希望智能 体之间可以不依赖于集中式的训练学习方式, 依旧能够在不完全可知的环境中分析感知其他智能体的 信息, 从而完成任务. 所以, 通过通信信息来补充环境的缺失信息的这种思路更容易被泛化. 近期, 更 为迫切的实际需求是参与任务的多个智能体不愿意进行诸如策略参数等信息的共享. 这就是联邦学习 (federated learning, FL) 的要求. 在这种情况下, 算法更需要保证智能体之间只有有限的抽象信息用来传输, 从而满足各个智能体对于隐私的需求。
在多智能体系统中, 如果对智能体的保护程度较高, 即智能体不会直接分享重要的内部信息, 智能 体则需要一些辅助的信息来补充这一部分缺失的不可观测状态. 最直观的做法就是互相传递有意义的 通信信息, 这种信息可以在一定程度上帮助智能体对环境进行理解. 但是, 在满足严格的互相不可见, 且有限信息共享的要求的前提下, 智能体之间要做到完全的独立学习与通信是十分困难的事情. 即便 是在基于通信的 MARL 的工作中, 也有很大一部分工作依赖于集中式的训练学习或者依赖于智能体 之间重要信息的共享 (例如智能体的动作). 而这样的学习方式有悖于实际的需求. 因此, 智能体需要 能够自主地在更新策略的同时自行调整通信信息, 从而做到完全的不依赖于集中式的或基于局部信息 共享的学习. 本文重点回顾基于通信的 MARL 的工作. 我们总结了基于通信的 MARL 的发展历程, 以及不同 性质的多智能体系统场景下的代表性工作, 进一步给出不同工作的分析以及适用条件. 最后, 我们总结 并展望未来可能进行的探索方向. 我们由衷希望本文能够为对研究 MARL 的读者提供帮助.
2 单智能体强化学习
本节主要介绍单智能体 DRL 的基础知识. 首先, 回顾传统的强化学习, 即单智能体 (single-agent RL, SARL) 的相关概念, 然后, 介绍深度强化学习的兴起、前沿的算法和现存的问题以及挑战. 方便后 续章节为大家引入多智能体 RL 的问题设定、前沿研究的大致分类和框架.
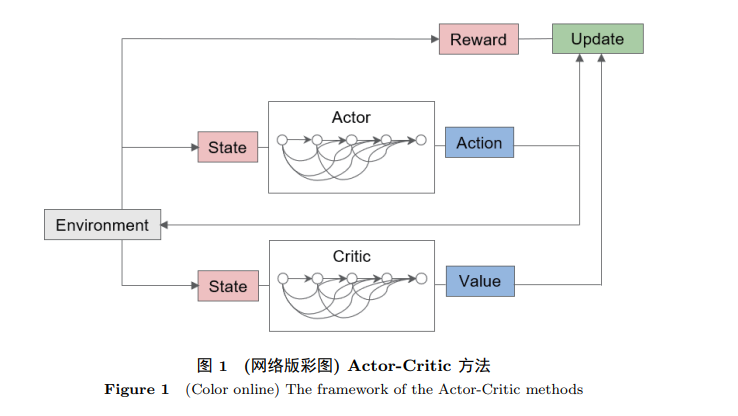
3 多智能体强化学习
MARL DRL 面对的问题的复杂性很大程度上体现在: 多数任务所涉及的系统结构较为繁杂, 往往根据一 些规则或者常识可以分解为多个完成不同子任务的个体. 也就是说, 为了完成某个任务, 系统需要多个 智能体同时参与, 它们会在各自所处的子空间分散执行任务, 但从任务层面来看, 它们需要互相配合并 且这些智能体各自的子决策结果会互相影响. 在这样的多智能体系统中, 各个智能体需要在环境不完全可知的情况下互相关联, 进而完成任务. 它们需要互相配合. “配合” 没有限定一定要合作, 可以互相竞争也可以有竞争有合作, 依据任务本身 来定. 对于 MAS 的场景, 同样需要对这类问题进行建模然后探索解决问题的方法.
4 基于通信的多智能体强化学习
在实际系统中, 参与任务的各个智能体往往会考虑安全或者隐私, 不希望过多地依赖于直接共享 各自领域的局部信息来完成任务. 这些关键的局部信息可能包括: 各个智能体的动作, 或者直接共享 同样的策略网络结构, 甚至是集中起来共享经验池以更新各个智能体的策略, 也就是中心化的学习 (centralized learning) 的概念. 下面我们简要地将现有的基于通信的 MARL 或者 MADRL 算法归类, 然后列举现在每一类的研究进展. 依据算法利用的 DRL 技术, 现有的基于通信的多智能体深度强化 学习算法 (communication-based multi-agent deep reinforcement learning, CB-MADRL) 大致可以分为 以下几类:
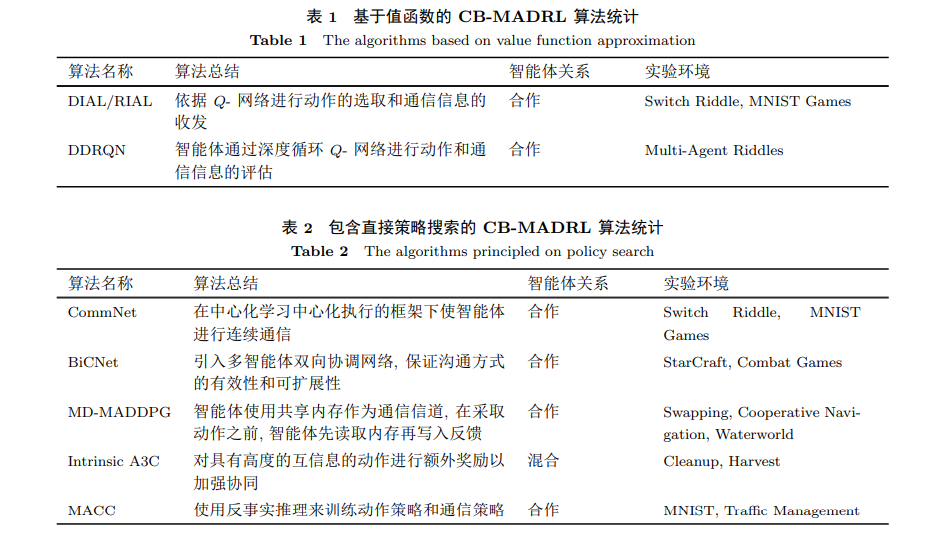
(1) 基于值函数的 CB-MADRL. 这种方法依靠对值函数 (以 Q- 值函数为主) 进行重构使之适用 于 MA 系统, 这部分工作在表 1 中总结.
(2) 包含直接策略搜索的 CB-MADRL. 由于表现不够稳定, 单纯使用直接策略搜索作 MAS 决策 的工作十分少见. 现在大多学者都倾向于选择基于 Actor-Critic 框架作 CB-MADRL 的研究, Actor 是 各个智能体的局部子策略, 通信的过程和效果主要依靠 Critic 来判定, 这部分算法在表 2 中总结.
(3) 提升通信效率的突破. 我们发现在以上两类方法逐渐发展的过程中, 学者们对这些算法也尝 试了改进, 意在提升通信的效率进而提升算法的学习性能, 相关工作总结于表 3.
(4) 关于应急通信的研究. 如今研究领域间的交叉已经极为常见, 很多语言研究领域的研究者们开 始尝试从通信语言如何产生, 以及通信信息的质量度量等方向进行研究, 从而丰富了多智能体通信的 研究方向, 相关工作总结于表 4.
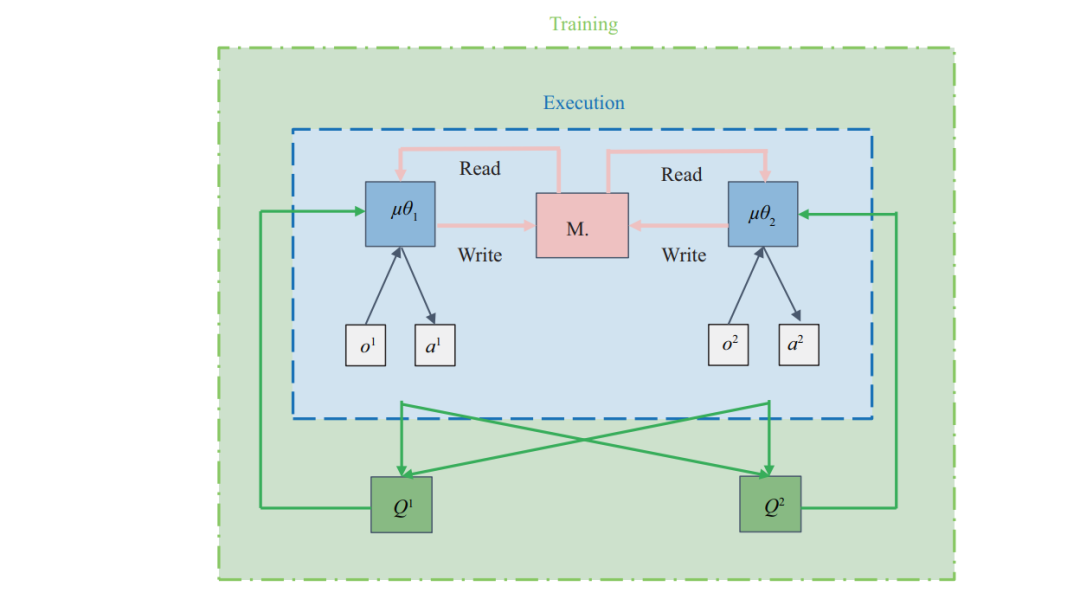
如果要求智能体通过通信的方式彼此协同完成一项任务, 智能体就需要通过将自己的信息, 例如 状态和动作等, 编码成一条有限长的信息, 传递给其余智能体, 同时也接受来自其余智能体的信息. 其 目的就是希望智能体能够将收到的信息作为观测的补充, 尽可能地还原不可见状态的信息, 进而得到 近似全局状态下的最优动作. 上述过程中, 通信的问题主要集中在如何传递高质量的通信信息, 具体来 说主要考虑: 通信信息需要包含哪些内容, 以及如何及时地更新通信信息. 在接下来的几个小节中, 我们将主要从以上两点为大家介绍并分析现有算法的特性.

5 归纳与展望
通过前面的回顾不难发现, 随着 DRL 技术的发展, MAS 场景的问题越来越多地可以利用 DRL技术的迁移得到解决. 并且在各种 MAS 环境中都得到了测试, 甚至在星际这样的游戏上也取得了胜 利. MADRL 的技术和突破是值得肯定的, 并且 MADRL 大背景下的现有工作已经有学者进行了总 结[62] . 我们更加希望各个智能体通过互相必要的沟通, 就能在不完全可知的环境中分析感知环境中其 他智能体的信息, 从而完成既定的任务. 本节主要对现存的 CB-MADRL 算法进行归纳, 然后进一步探 讨未来可能需要解决的问题和工作方向.
6 结束语
多智能体强化学习的发展离不开深度强化学习的突破性进展. 而从多智能体强化学习这个层面来 说, 在看到已有的成绩的同时, 提高学习效率、提高鲁棒性和泛化性的困难依旧存在. 这种困难是多智 能体系统本身固有的性质, 例如环境的非稳定性、奖赏的延迟性和稀疏性、奖赏分配的困难性等. 尽 管这些困难依旧是牵制这个领域发展的因素, 但多智能体强化学习服务于现实系统解决现实问题是学 界的目标. 选择基于通信的多智能体强化学习算法进行介绍的主要原因是通信本身更迎合实际的应用场景 的需求. 通信信息能够很自然地使得智能体摆脱中心化的学习的框架. 智能体之间的有效的信息传递 不是简单的私密的信息共享, 而是智能体在不断地跟环境交互中所给出的有意义的反馈. 这种反馈通 常是抽象的, 是需要协同的智能体互相理解的. 通过对现有的基于通信的多智能体深度强化学习算法的分析, 不难发现能用于现实多智能体系统 中的基于通信的多智能体强化学习算法需要尽可能摆脱其对信息共享的依赖, 也就是尽可能保证较少 的信息共享, 做到完全基于通信. 完全基于通信的隐含意义是智能体在互相不可知的情况下仅仅依靠 通信信息实现缺失信息的补充, 进而摆脱过多的内部信息交流以及中心化学习的需求. 从而有如下的 结果.
• 智能体的隐私需求得到保障: 智能体可以根据自身状态及接收的信息自行调整传送信息.
• 算法的泛化性得到提升: 如果智能体可以仅通过通信信息互相理解进而协同完成任务, 在面对不 同任务时智能体可以根据不同的任务需求, 自适应地调整通信信息.
最后, 希望通过我们的介绍能够对多智能体强化学习, 特别是基于通信手段的多智能体强化学习 方向有所关注的学者们提供一些帮助; 希望通过广大学者们的努力使得多智能体强化学习技术更快更好地服务于现实世界中的系统.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CRLS” 就可以获取《「基于通信的多智能体强化学习」 进展综述》专知下载链接





