

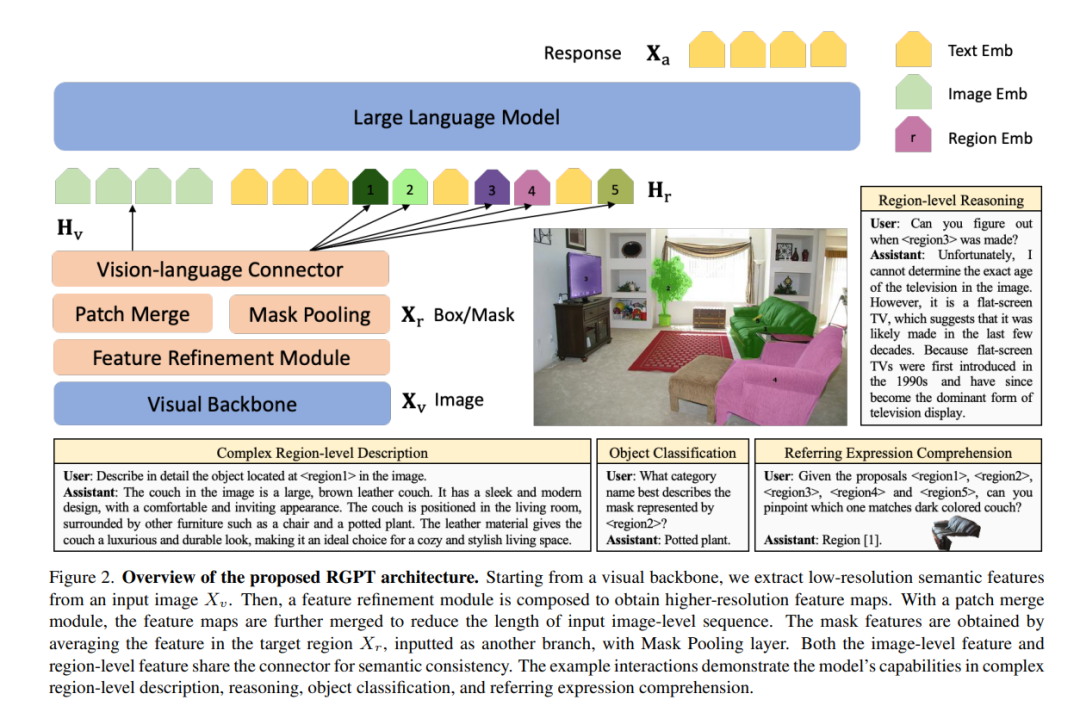
视觉语言模型(VLMs)通过将大型语言模型(LLMs)与图文对集成在一起,经历了迅速的发展,但由于视觉编码器的空间意识有限,以及使用缺乏详细、特定区域字幕的粗粒度训练数据,它们在详细区域视觉理解方面面临挑战。为了解决这一问题,我们介绍了RegionGPT(简称为RGPT),这是一个为复杂区域级字幕和理解而设计的新颖框架。RGPT通过对现有VLMs中的视觉编码器进行简单而有效的修改,增强了区域表示的空间意识。我们进一步通过在训练和推理阶段整合任务引导的提示(提示),提高了对特定输出范围任务的性能,同时保持了模型对通用任务的多功能性。此外,我们开发了一个自动化的区域字幕数据生成管道,丰富了训练集,增加了详细的区域级字幕。我们展示了一个通用的RGPT模型可以有效地应用,并显著提高了一系列区域级任务的性能,包括但不限于复杂区域描述、推理、对象分类和指代表达理解。代码将在项目页面发布。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
216+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
147+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
216+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
147+阅读 · 2023年3月29日