加固网络物理资产既重要又耗费人力。最近,机器学习(ML)和强化学习(RL)在自动化任务方面显示出巨大的前景,否则这些任务将需要大量的人类洞察力/智能。在RL的情况下,智能体根据其观察结果采取行动(进攻/红方智能体或防御/蓝方智能体)。这些行动导致状态发生变化,智能体获得奖励(包括正奖励和负奖励)。这种方法需要一个训练环境,在这个环境中,智能体通过试错学习有希望的行动方案。在这项工作中,我们将微软的CyberBattleSim作为我们的训练环境,并增加了训练蓝方智能体的功能。报告描述了我们对CBS的扩展,并介绍了单独或与红方智能体联合训练蓝方智能体时获得的结果。我们的结果表明,训练蓝方智能体确实可以增强对攻击的防御能力。特别是,将蓝方智能体与红方智能体联合训练可提高蓝方智能体挫败复杂红方智能体的能力。
问题描述
由于网络威胁不断演变,任何网络安全解决方案都无法保证提供全面保护。因此,我们希望通过机器学习来帮助创建可扩展的解决方案。在强化学习的帮助下,我们可以开发出能够分析和学习攻击的解决方案,从而在未来防范类似威胁,而不是像商业网络安全解决方案那样简单地识别威胁。
工程描述
我们的项目名为MARLon,探索将多智能体强化学习(MARL)添加到名为CyberBattleSim的模拟抽象网络环境中。这种多智能体强化学习将攻击智能体和可学习防御智能体的扩展版本结合在一起进行训练。
要在CyberBattleSim中添加MARL,有几个先决条件。第一个先决条件是了解CyberBattleSim环境是如何运行的,并有能力模拟智能体在做什么。为了实现这一点,该项目的第一个目标是实现一个用户界面,让用户看到环境在一个事件中的样子。
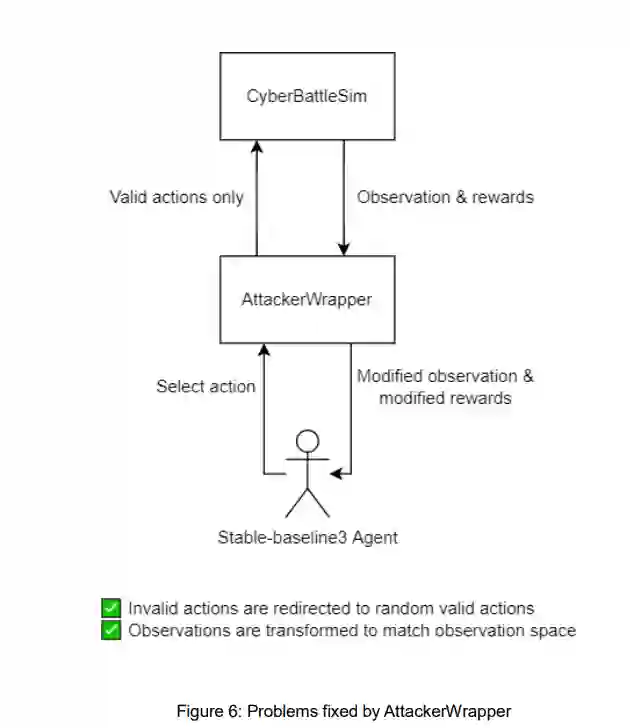
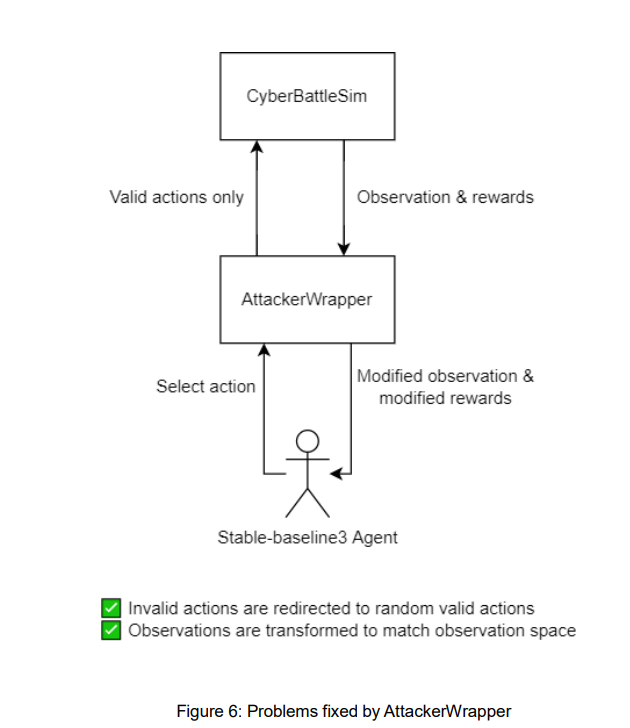
第二个先决条件是为CyberBattleSim添加MARL算法。目前CyberBattleSim的表Q学习和深Q学习实现在结构上无法处理这个问题。这是因为CyberBattleSim实现的表Q学习和深Q学习不符合适当的OpenAI Gym标准。因此,需要添加新的强化学习算法。
当前的防御者没有学习能力,这意味着要启用多智能体学习,防御者需要添加以下功能:添加使用所有可用行动的能力,将这些行动收集到行动空间,实现新的观察空间,并实现奖励函数。
最后,为了增加MARL,新创建的攻击者算法和新的可学习防御者必须在同一环境中组合。这样,两个智能体就可以在相互竞争的同时进行训练。