

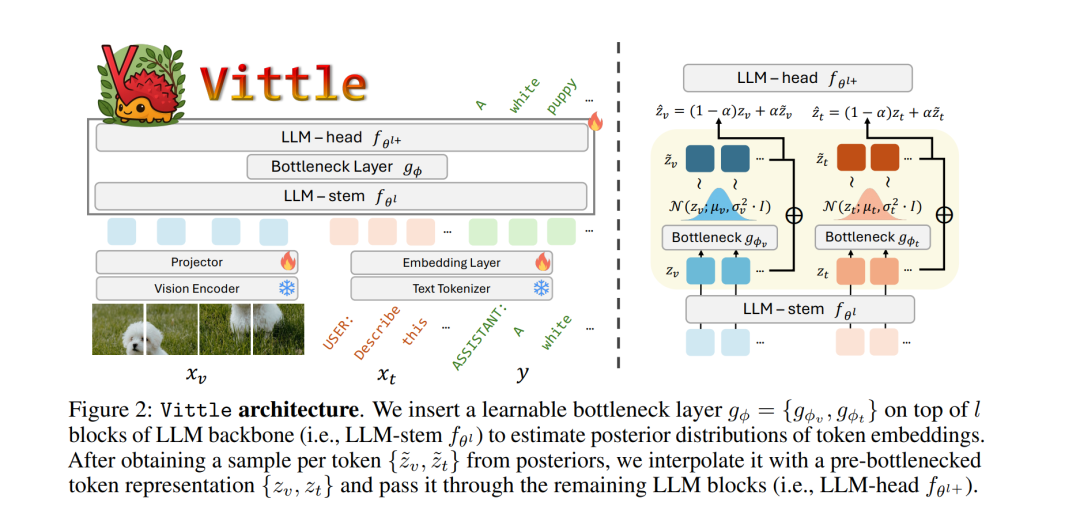
尽管多模态大型语言模型(MLLMs)已被广泛采用,但在遭遇分布偏移下的不熟悉查询时,其性能仍会下降。现有提升 MLLM 泛化能力的方法通常需要更多的指令数据或更大更先进的模型架构,这两者都会带来不小的人力与计算成本。本文从表征学习的角度出发,提出一种替代思路,以增强 MLLM 在分布偏移下的鲁棒性。受信息瓶颈(IB)原理启发,我们为 MLLM 推导了 IB 的变分下界,并据此设计了一种可行的实现——视觉指令瓶颈微调(Visual Instruction Bottleneck Tuning,Vittle)。随后,我们通过揭示 Vittle 与一种基于信息论的 MLLM 鲁棒性度量之间的联系,为该方法提供了理论论证。在涵盖 45 个数据集(其中包含 30 种偏移场景)的开放式与封闭式问答以及目标幻觉检测任务上的实证结果表明,Vittle 通过追求学习最小充分表征,能够持续提升 MLLM 在分布偏移下的鲁棒性。
成为VIP会员查看完整内容
相关内容

神经信息处理系统年会(Annual Conference on Neural Information Processing Systems)的目的是促进有关神经信息处理系统生物学,技术,数学和理论方面的研究交流。核心重点是在同行会议上介绍和讨论的同行评审新颖研究,以及各自领域的领导人邀请的演讲。在周日的世博会上,我们的顶级行业赞助商将就具有学术意义的主题进行讲座,小组讨论,演示和研讨会。星期一是教程,涵盖了当前的问询,亲和力小组会议以及开幕式演讲和招待会的广泛背景。一般会议在星期二至星期四举行,包括演讲,海报和示范。
官网地址:http://dblp.uni-trier.de/db/conf/nips/
Arxiv
219+阅读 · 2023年4月7日
Arxiv
84+阅读 · 2023年4月4日
Arxiv
150+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
219+阅读 · 2023年4月7日
Arxiv
84+阅读 · 2023年4月4日
Arxiv
150+阅读 · 2023年3月29日