本系统综述探讨了大语言模型(LLMs)在组合优化(CO)中的应用。我们遵循系统综述与元分析的首选报告项目(PRISMA)指南报告我们的研究发现。我们通过Scopus和Google Scholar进行了文献检索,检查了超过2,000篇文献。我们根据四项纳入标准和四项排除标准对文献进行了评估,这些标准涉及语言、研究重点、出版年份和类型。最终,我们选择了103篇研究。我们将这些研究按语义类别和主题进行分类,以提供该领域的全面概述,包括LLMs执行的任务、LLMs的架构、专门为评估LLMs在CO中应用设计的数据集以及应用领域。最后,我们确定了利用LLMs在该领域的未来发展方向。
关键词:系统综述 · 大语言模型 · 组合优化
1 引言
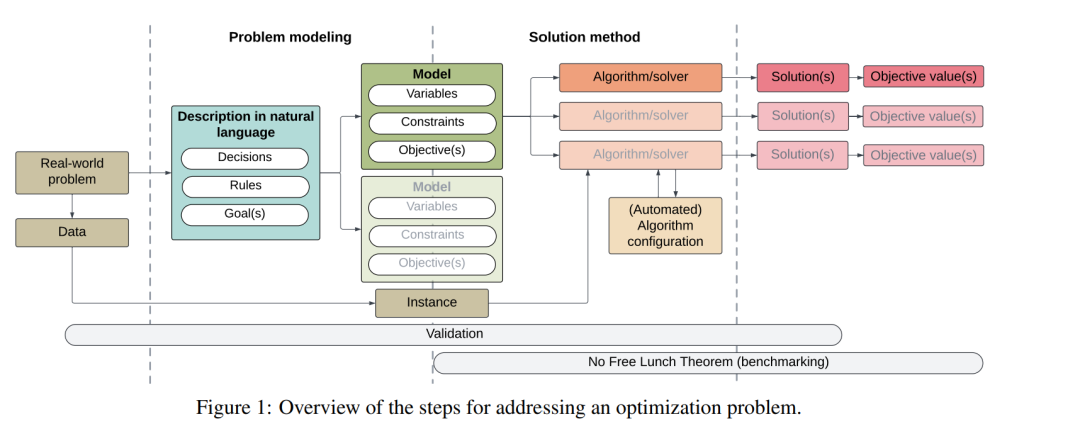
组合优化问题(COPs)是一类优化问题,其特点是离散的变量域和有限的搜索空间。组合优化(CO)在许多需要复杂决策能力的领域中发挥着至关重要的作用,如工业调度[219]、员工排班[25, 102]、设施选址[27, 64]和时间表安排[199, 254]等。传统上,这类问题通过线性规划(LP)、整数线性规划(ILP)、混合整数线性规划(MILP)和约束规划(CP)等技术进行建模,并通过商业求解器,如IBM ILOG CPLEX [88]或Gurobi [70],以及启发式和元启发式(MH)算法[194]来求解。 尽管许多成功的CO应用已被开发出来,但优化任务的设计和工程仍主要由人工驱动。用户必须通过定义一组变量、约束和一个或多个目标函数,将问题转化为优化模型,然后编写代码并运行软件求解器或算法来寻找解决方案。这些活动并非简单,需要一定的专业知识。 受最近大语言模型(LLMs)在执行广泛复杂任务中的应用进展的启发,越来越多的兴趣集中在将LLMs集成到CO中,以减轻优化过程中的人工密集型环节[53, 84, 145, 236]。LLMs处理、解释和生成自然语言的能力使其特别适合解决CO中的活动,包括将自然语言描述转化为数学模型等形式化表达[74, 89]以及代码生成[111, 214]。 人工智能(AI)特别是自然语言处理(NLP)的快速发展,使得LLMs的能力和应用大幅提升,导致了大量学术研究和模型的开发。尽管这个领域的活动日益增多,但这大量的研究成果也形成了一个复杂的知识体系,难以轻松掌握。特别是针对LLMs在CO中的应用,现有的学术文献较为有限且零散,现有的研究工作在方法学、应用领域和研究发现上存在较大差异。因此,本系统综述旨在整合当前LLMs应用于CO的最先进成果。我们通过筛选、分析和系统地组织文献,以澄清该主题并确定当前和未来研究的战略方向。我们遵循系统综述和元分析首选报告项目(PRISMA)指南进行报告。通过这一研究,我们旨在了解LLMs在解决复杂优化任务中的能力,并探索该领域中不断发展的趋势和方向。通过系统地综合和分析现有研究,本综述旨在提供一个结构化的理解,帮助理解LLMs如何在CO中应用,并为未来研究提供启示。
本综述的结构如下:第2节讨论了驱动我们工作的目标和动机;第3节探讨了与相关工作的关系和区别;第4节提供了理解LLMs与CO之间相互关系所需的背景;第5节详细介绍了我们遵循的方法论;第6节对我们综述中纳入的研究进行了分类和讨论;第7节概述了未来的研究方向;第8节讨论了我们方法的局限性;最后,第9节给出了结论并提出了未来的研究工作。