

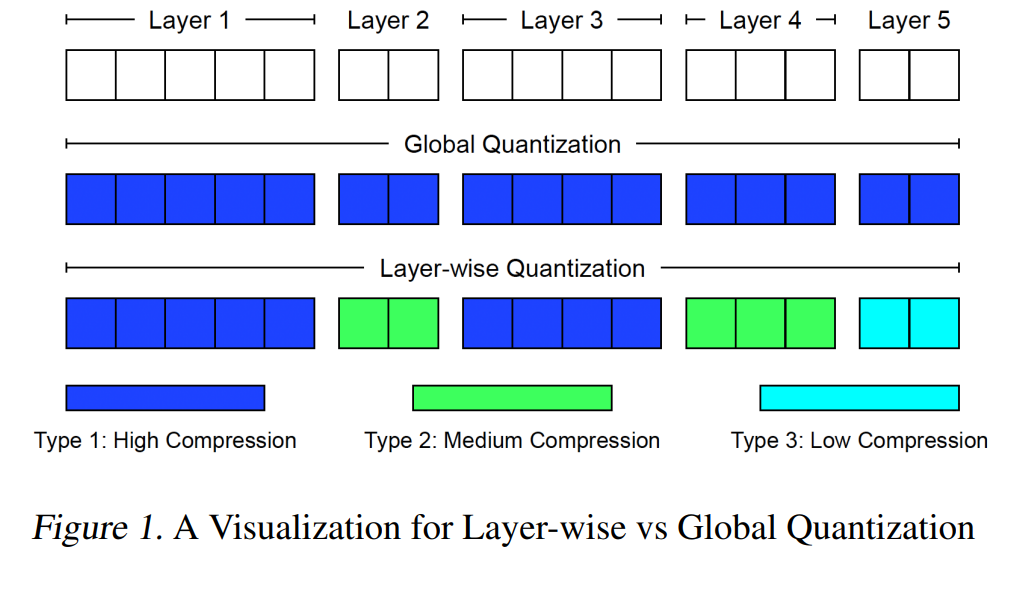
现代深度神经网络在多个层次上表现出显著的异质性,包括残差连接(residuals)、多头注意力机制(multi-head attention)等多种类型的结构。这些层由于在结构(如维度、激活函数等)和表征特性上的差异,对模型预测产生了重要影响。针对这一现象,我们提出了一种通用的逐层量化框架,具备紧致的方差界限与码长上界,能够在训练过程中自适应地适配各层的异质性。
基于此框架,我们在分布式变分不等式(variational inequalities, VIs)背景下引入了一种全新的逐层量化技术,并提出了具有自适应学习率的量化乐观双均值算法(QODA, Quantized Optimistic Dual Averaging)。该算法在处理单调变分不等式问题时可实现具有竞争力的收敛速度。 实证结果表明,在使用12块以上GPU训练Wasserstein GAN的端到端训练中,QODA相较于现有基线方法在训练时间上可实现最高达**150%**的加速效果。
成为VIP会员查看完整内容
相关内容
Arxiv
210+阅读 · 2023年4月7日
Arxiv
12+阅读 · 2021年10月4日

相关VIP内容
相关资讯
相关论文
Arxiv
210+阅读 · 2023年4月7日
Arxiv
12+阅读 · 2021年10月4日